Evolution des Cluster-Scheduling-Systems
Kubernetes hat sich zum De-facto-Standard im Bereich der Container-Orchestrierung entwickelt. Alle Anwendungen werden in Zukunft auf Kubernetes entwickelt und ausgeführt. Der Zweck dieser Artikelserie ist es, die zugrunde liegenden Implementierungsprinzipien von Kubernetes auf tiefgreifende und einfache Weise vorzustellen.
Kubernetes ist ein Cluster-Scheduling-System. Dieser Artikel stellt hauptsächlich einige frühere Cluster-Scheduling-Systemarchitekturen von Kubernetes vor. Durch die Analyse ihrer Designideen und der Architekturmerkmale können wir den Entwicklungsprozess der Cluster-Scheduling-Systemarchitektur und das Hauptproblem, das beim Architekturdesign berücksichtigt werden muss, untersuchen. Das wird sehr hilfreich sein, um die Kubernetes-Architektur zu verstehen.
Wir müssen einige der grundlegenden Konzepte des Cluster-Scheduling-Systems verstehen, um es klar zu machen, Ich werde das Konzept anhand eines Beispiels erklären, Nehmen wir an, wir möchten einen verteilten Cron implementieren. Das System verwaltet eine Reihe von Linux-Hosts. Der Benutzer definiert den Job über die vom System bereitgestellte API. das System führt regelmäßig die entsprechende Aufgabe basierend auf der Aufgabendefinition aus, in diesem Beispiel sind die grundlegenden Konzepte unten aufgeführt:
- Cluster: Die von diesem System verwalteten Linux-Hosts bilden einen Ressourcenpool zum Ausführen von Aufgaben. Dieser Ressourcenpool wird Cluster genannt.
- Job: Definiert, wie der Cluster seine Aufgaben ausführt. In diesem Beispiel ist Crontab genau ein einfacher Job, der deutlich zeigt, was zu welchem Zeitpunkt (Zeitintervall) ausgeführt werden muss (Ausführungsskript).Die Definition einiger Jobs ist komplexer, z. B. die Definition eines Jobs, der in mehreren Aufgaben ausgeführt werden soll, und die Abhängigkeiten zwischen Aufgaben sowie die Ressourcenanforderungen jeder Aufgabe.
- Aufgabe: Ein Job muss in bestimmte Leistungsaufgaben eingeplant werden. Wenn wir einen Job definieren, um ein Skript jede Nacht um 1 Uhr morgens auszuführen, ist der Skriptprozess, der jeden Tag um 1 Uhr morgens ausgeführt wird, eine Aufgabe.
Beim Entwurf des Clusterplanungssystems sind die Kernaufgaben des Systems zwei:
- Aufgabenplanung: Nachdem die Aufträge an das Clusterplanungssystem gesendet wurden, müssen die übermittelten Aufträge in bestimmte Ausführungsaufgaben unterteilt und die Ausführungsergebnisse der Aufgaben nachverfolgt und überwacht werden. Im Beispiel des verteilten Cron muss das Planungssystem den Prozess gemäß den Anforderungen der Operation rechtzeitig starten. Wenn der Vorgang nicht ausgeführt werden kann, ist der erneute Versuch erforderlich usw. In einigen komplexen Szenarien, z. B. Hadoop Map Reduce, muss das Planungssystem die Map Reduce-Aufgabe in die entsprechenden Multiple Map- und Reduce-Aufgaben aufteilen und letztendlich die Ergebnisdaten für die Aufgabenausführung abrufen.
- Ressourcenplanung: Wird im Wesentlichen verwendet, um Aufgaben und Ressourcen abzugleichen, und es werden geeignete Ressourcen zugewiesen, um Aufgaben entsprechend der Ressourcennutzung der Hosts im Cluster auszuführen. Es ist ähnlich wie der Prozess des Scheduling-Algorithmus des Betriebssystems, das Hauptziel der Ressourcenplanung ist es, die Ressourcenauslastung so weit wie möglich zu verbessern und die Wartezeit für Aufgaben unter der Bedingung der festen Versorgung mit Ressourcen zu reduzieren, und reduzieren Sie die Verzögerung der Aufgabe oder Reaktionszeit (wenn es sich um Batch-Task handelt, bezieht es sich auf die Zeit von Anfang bis Ende der Task-Operationen, wenn es sich um Online-Response-Typ-Tasks handelt, wie Web-Anwendungen, die sich auf die jeweilige Antwortzeit auf die Anfrage beziehen), muss die Task-Priorität berücksichtigt werden, während sie so fair wie möglich ist möglich(Ressourcen werden fair auf alle Aufgaben verteilt). Einige dieser Ziele sind widersprüchlich und müssen ausgewogen sein, wie Ressourcenauslastung, Reaktionszeit, Fairness und Prioritäten.
Hadoop MRv1
Map Reduce ist eine Art paralleles Rechenmodell. Hadoop kann diese Art von Cluster-Management-Plattform für paralleles Computing ausführen. MRv1 ist die erste Generation der Map Reduce Task Scheduling Engine der Hadoop-Plattform. Kurz gesagt, MRv1 ist verantwortlich für die Planung und Ausführung des Auftrags auf dem Cluster, und zurück zu den Berechnungsergebnissen, wenn ein Benutzer eine Karte definiert Berechnung reduzieren und es an die Hadoop einreichen. So sieht die Architektur von MRv1 aus:
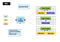
Die architektur ist relativ einfach, die standard Master/Slave architektur hat zwei core komponenten:
- Job Tracker ist die Hauptverwaltungskomponente von Cluster, die sowohl für die Ressourcenplanung als auch für die Aufgabenplanung verantwortlich ist.
- Task Tracker wird auf jedem Computer im Cluster ausgeführt, der für die Ausführung bestimmter Aufgaben auf dem Host und die Statusmeldung verantwortlich ist.
Mit der Popularität von Hadoop und der Zunahme verschiedener Anforderungen muss MRv1 die folgenden Probleme verbessern:
- Die Leistung hat einen gewissen Engpass: die maximale Anzahl der Knoten, die die Verwaltung unterstützen, beträgt 5.000, und die maximale Anzahl der Aufgaben zur Unterstützung des Betriebs beträgt 40.000. Es gibt noch Raum für Verbesserungen.
- Es ist nicht flexibel genug, um andere Aufgabentypen zu erweitern oder zu unterstützen. Neben Aufgaben vom Typ Map Reduce gibt es im Hadoop-Ökosystem viele andere Aufgabentypen, die geplant werden müssen, z. B. Spark, Hive, HBase, Storm, Oozie usw. Daher ist ein allgemeineres Planungssystem erforderlich, das mehr Aufgabentypen unterstützen und erweitern kann
- Geringe Ressourcenauslastung: MRv1 konfiguriert statisch eine feste Anzahl von Slots für jeden Knoten, und jeder Slot kann nur für den spezifischen Aufgabentyp (Map oder Reduce) verwendet werden, was zu dem Problem der Ressourcenauslastung führt. Beispielsweise steht eine große Anzahl von Zuordnungsaufgaben für ungenutzte Ressourcen in der Warteschlange, aber tatsächlich ist eine große Anzahl von Zuordnungssteckplätzen für Maschinen inaktiv.
- Probleme mit mehreren Mandanten und Versionen. Beispielsweise führen verschiedene Abteilungen Aufgaben im selben Cluster aus, die jedoch logisch voneinander isoliert sind, oder sie führen verschiedene Versionen von Hadoop im selben Cluster aus.
YARN
YARN(Yet Another Resource Negotiator) ist eine zweite Generation von Hadoop , deren Hauptzweck es ist, alle Arten von Problemen in MRv1 zu lösen. Garnarchitektur sieht so aus:

Das einfache Verständnis von YARN ist, dass die Hauptverbesserung gegenüber MRv1 darin besteht, die Verantwortlichkeiten des ursprünglichen Jobtracks in zwei verschiedene Komponenten aufzuteilen: Ressourcenmanager und Anwendungsmaster
- Ressourcenmanager: Es ist für die Ressourcenplanung verantwortlich, verwaltet alle Ressourcen, weist Ressourcen verschiedenen Arten von Aufgaben zu und erweitert den Ressourcenplanungsalgorithmus auf einfache Weise durch eine steckbare Architektur.
- Anwendungsmaster: Er ist für die Aufgabenplanung verantwortlich. Jeder Job (in YARN als Anwendung bezeichnet) startet einen entsprechenden Anwendungsmaster, der dafür verantwortlich ist, den Job in bestimmte Aufgaben aufzuteilen und Ressourcen vom Ressourcenmanager zu beantragen, die Aufgabe zu starten, den Status der Aufgabe zu verfolgen und die Ergebnisse zu melden.
Werfen wir einen Blick darauf, wie diese Architekturänderung die verschiedenen Probleme von MRv1 gelöst hat:
- Teilen Sie die ursprünglichen Aufgabenplanungsverantwortlichkeiten von Job Tracker auf, was zu erheblichen Leistungsverbesserungen führt. Die Aufgabenplanungsverantwortlichkeiten des ursprünglichen Jobtrackers wurden aufgeteilt, um vom Anwendungsmaster übernommen zu werden, und der Anwendungsmaster wurde verteilt, wobei jede Instanz nur die Anforderung eines Jobs behandelte, wodurch die maximale Anzahl von Clusterknoten von 5.000 auf 10.000 erhöht wurde.
- Die Komponenten Task Scheduling, Application Master und Resource Scheduling werden entkoppelt und dynamisch basierend auf Jobanforderungen erstellt. Eine Anwendungsmasterinstanz ist nur für einen Planungsauftrag verantwortlich, wodurch es einfacher wird, verschiedene Arten von Aufträgen zu unterstützen.
- Die Containerisolationstechnologie wird eingeführt, jede Aufgabe wird in einem isolierten Container ausgeführt, wodurch die Ressourcennutzung entsprechend dem Bedarf der Aufgabe an Ressourcen, die dynamisch zugewiesen werden können, erheblich verbessert wird. Der Nachteil davon ist, dass die Ressourcenverwaltung und -zuweisung von YARN nur eine Speicherdimension haben.
Mesos-Architektur
Das Designziel von YARN besteht weiterhin darin, die Planung des Hadoop-Ökosystems zu unterstützen. Das Ziel von Mesos kommt näher, es ist als allgemeines Planungssystem konzipiert, das den Betrieb des gesamten Rechenzentrums verwalten kann. Wie wir sehen, hat das architektonische Design von Mesos viel GARN als Referenz verwendet, die Jobplanung und Ressourcenplanung werden von den verschiedenen Modulen separat getragen. Der größte Unterschied zwischen Mesos und YARN besteht jedoch in der Art und Weise, wie Ressourcen geplant werden. Der Druck der Ressourcenplanung wird weiter gelöst, und die Skalierbarkeit der Jobplanung wird ebenfalls erhöht.

Die Hauptkomponenten von Mesos sind:
- Mesos Master: Es ist eine Komponente, die ausschließlich für die Ressourcenzuweisung und die Komponenten des Managements verantwortlich ist. Die Funktionsweise unterscheidet sich jedoch geringfügig, wie später erläutert wird.
- Framework: ist für die Jobplanung verantwortlich, verschiedene Jobtypen haben ein entsprechendes Framework, z. B. das Spark-Framework, das für Spark-Jobs verantwortlich ist.
Ressourcenangebot von Mesos
Es mag so aussehen, als wären die Mesos- und YARN-Architekturen ziemlich ähnlich, aber tatsächlich hat der Master of Mesos unter dem Aspekt des Ressourcenmanagements einen sehr einzigartigen (und etwas bizarren) Ressourcenangebotsmechanismus:
- GARN ist Pull: Wenn die Verbraucher der Ressource (Anwendungsmaster) Ressourcen benötigen, kann die Schnittstelle des Ressourcenmanagers aufgerufen werden, um Ressourcen zu erhalten, und der Ressourcenmanager reagiert nur passiv auf die Anforderungen des Anwendungsmasters.
- Mesos ist Push: Die von Master of Mesos bereitgestellten Ressourcen sind proaktiv. Master of Mesos wird regelmäßig die Initiative ergreifen, um alle aktuell verfügbaren Ressourcen (die sogenannten Ressourcenangebote, ich nenne es ab sofort Angebot) in das Framework zu schieben. Wenn das Framework Aufgaben ausführen muss, kann es keine Ressourcen aktiv beantragen, es sei denn, die Angebote gehen ein. Framework wählt eine qualifizierte Ressource aus dem zu akzeptierenden Angebot aus (diese Bewegung wird in Mesos als Akzeptieren bezeichnet) und lehnt die verbleibenden Angebote ab (diese Bewegung wird als Ablehnen bezeichnet). Wenn in dieser Angebotsrunde nicht genügend qualifizierte Ressourcen vorhanden sind, müssen wir auf die nächste Masterrunde warten, um ein Angebot zu unterbreiten.
Ich glaube, wenn Sie diesen aktiven Angebotsmechanismus sehen, werden Sie das gleiche Gefühl mit mir haben. Das heißt, die Effizienz ist relativ niedrig, und die folgenden Probleme werden auftreten:
- die Entscheidungseffizienz eines Frameworks beeinflusst die Gesamteffizienz. Aus Gründen der Konsistenz kann der Master jeweils nur ein Angebot für ein Framework bereitstellen und warten, bis das Framework das Angebot ausgewählt hat, bevor der Rest für das nächste Framework bereitgestellt wird. Auf diese Weise wirkt sich die Entscheidungseffizienz eines Rahmens auf die Gesamteffizienz aus.
- “verschwendet” viel Zeit mit Frameworks, die keine Ressourcen benötigen. Mesos weiß nicht wirklich, welches Framework Ressourcen benötigt. Es wird also ein Framework mit Ressourcenanforderungen geben, das für das Angebot in der Warteschlange steht, aber das Framework ohne Ressourcenanforderungen erhält häufig ein Angebot.
Als Reaktion auf die oben genannten Probleme hat Mesos einige Mechanismen bereitgestellt, um die Probleme zu mildern, z. B. das Festlegen eines Timeouts für das Framework, um Entscheidungen zu treffen, oder das Ablehnen von Angeboten durch das Festlegen des Status Unterdrücken. Da es nicht im Mittelpunkt dieser Diskussion steht, werden hier die Details vernachlässigt.
Tatsächlich gibt es einige offensichtliche Vorteile für Mesos, die diesen Mechanismus des aktiven Angebots verwenden:
- Die Leistung ist offensichtlich verbessert. Ein Cluster kann bis zu 100.000 Knoten unterstützen Gemäß den Simulationstests kann der größte Cluster für die Produktionsumgebung von Twitter 80.000 Knoten unterstützen. der Hauptgrund ist, dass das aktive Angebot des Mesos Master-Mechanismus die Verantwortlichkeiten des Mesos weiter vereinfacht. der Prozess der Ressourcenplanung, Resource to Task Matching, in Mesos ist in zwei Phasen unterteilt: Angebotene Ressourcen und Angebot an Aufgabe. Der Mesos-Master ist nur für den Abschluss der ersten Phase verantwortlich, und die Anpassung der zweiten Phase bleibt dem Framework überlassen.
- Flexibler und in der Lage, verantwortungsvollere Richtlinien für die Aufgabenplanung zu erfüllen. Zum Beispiel die Ressourcennutzungsstrategie von All Or Nothings.
Planungsalgorithmus von Mesos DRF (Dominant Resource Fairness)
Der DRF-Algorithmus hat eigentlich nichts mit unserem Verständnis der Mesos-Architektur zu tun, aber er ist sehr wichtig und wichtig in Mesos, daher werde ich hier etwas mehr erklären.
Wie oben erwähnt, bietet Mesos dem Framework wiederum ein Angebot, welches Framework sollte also ausgewählt werden, um jedes Mal ein Angebot zu machen? Dies ist das Kernproblem, das durch den DRF-Algorithmus gelöst werden soll. Das Grundprinzip besteht darin, sowohl Fairness als auch Effizienz zu berücksichtigen. Während alle Ressourcenanforderungen des Frameworks erfüllt werden, sollte es so fair wie möglich sein, zu vermeiden, dass ein Framework zu viele Ressourcen verbraucht und andere Frameworks verhungert.
DRF ist eine Variante des Min-Max-Fairness-Algorithmus. In einfachen Worten besteht es darin, das Framework mit der niedrigsten dominanten Ressourcennutzung auszuwählen, um das Angebot jedes Mal bereitzustellen. Wie berechnet man die dominante Ressourcennutzung des Frameworks? Aus allen vom Framework belegten Ressourcentypen wird der Ressourcentyp mit der niedrigsten Ressourcenbelegungsrate als dominante Ressource ausgewählt. Seine Ressourcenbelegungsrate ist genau die dominierende Ressourcennutzung des Frameworks. Beispielsweise belegt eine CPU des Frameworks 20% der Gesamtressource, 30% des Speichers und 10% der Festplatte. Die dominante Ressourcennutzung des Frameworks beträgt also 10%, der offizielle Begriff nennt eine Festplatte als dominante Ressource, und diese 10% werden als dominante Ressourcennutzung bezeichnet.
Das ultimative Ziel von DRF ist es, Ressourcen gleichmäßig auf alle Frameworks zu verteilen. Wenn ein Framework X in dieser Angebotsrunde zu viele Ressourcen akzeptiert, dauert es viel länger, bis die Gelegenheit für die nächste Angebotsrunde besteht. Vorsichtige Leser werden jedoch feststellen, dass dieser Algorithmus eine Annahme enthält, dh nachdem das Framework Ressourcen akzeptiert hat, werden diese schnell freigegeben, andernfalls gibt es zwei Konsequenzen:
- Andere Menschen verhungern. Ein Framework A akzeptiert die meisten Ressourcen im Cluster gleichzeitig, und die Aufgabe wird ausgeführt, ohne beendet zu werden, sodass die meisten Ressourcen ständig von Framework A belegt sind und andere Frameworks die Ressourcen nicht mehr erhalten.
- Verhungere dich. Da die dominante Ressourcennutzung dieses Frameworks immer sehr hoch ist, besteht keine Chance, lange Zeit ein Angebot zu erhalten, sodass keine weiteren Aufgaben ausgeführt werden können.
Mesos eignet sich also nur für die Planung kurzer Aufgaben, und Mesos wurden ursprünglich für kurze Aufgaben von Rechenzentren entwickelt.
Zusammenfassung
Von der großen architektur, alle die planung system architektur ist Master/Slave architektur, Slave ende ist installiert auf jeder maschine mit anforderung von management, die ist verwendet zu sammeln host informationen, und führen aufgaben auf die host. Der Master ist hauptsächlich für die Ressourcen- und Aufgabenplanung verantwortlich. Die Ressourcenplanung stellt höhere Anforderungen an die Leistung, und die Aufgabenplanung stellt höhere Anforderungen an die Skalierbarkeit. Der allgemeine Trend besteht darin, die beiden Arten von Aufgaben zu entkoppeln und durch verschiedene Komponenten zu vervollständigen.
