Cloud Data Warehouse vs Traditional Data Warehouse Concepts
pilvipohjaiset tietovarastot ovat uusi normi. Takana ovat päivät, jolloin yrityksesi oli ostaa laitteisto, luoda palvelinhuoneita ja vuokrata, kouluttaa, ja ylläpitää oma tiimi henkilökuntaa ajaa sitä. Nyt, muutamalla klikkauksella kannettavan tietokoneen ja luottokortin, voit käyttää käytännössä rajattomasti laskentatehoa ja tallennustilaa.
tämä ei kuitenkaan tarkoita, että perinteiset tietovaraston ideat olisivat kuolleet. Klassinen tietovarastoteoria tukee suurinta osaa siitä, mitä pilvipohjaiset tietovarastot tekevät.
tässä artikkelissa selitämme perinteiset tietovaraston konseptit, jotka sinun on tiedettävä, ja tärkeimmät pilvipalvelukonseptit valikoimalla parhaita tarjoajia: Amazon, Google ja Panoply. Lopuksi lopetamme kustannus-hyötyanalyysin perinteisistä vs. cloud-tietovarastoista, jotta tiedät, mikä niistä sopii sinulle.
aloitetaan.
- perinteiset Tietovarastokonseptit
- Facts, Dimensions, and Measures
- normalisointi ja Denormalisointi
- tietomallit
- Faktataulukko
- Tähtikaavio vs. lumihiutale-skeema
- OLAP vs. OLTP
- Kolmitasoarkkitehtuuri
- Virtual Data Warehouse / Data Mart
- Kimball vs. Inmon
- ETL vs. ELT
- Yritystietovarasto
- Pilvitietovaraston konseptit
- Cloud Data Warehouse Concepts – Amazon Redshift
- klusterit
- solmut
- osiot/viipaleet
- Pylväsvarasto
- Pakkaus
- tietojen lataus
- Cloud Database Warehouse – Google BigQuery
- Palvelematon palvelu
- Colossus File System
- Dremel Execution Engine
- tietojen jakaminen
- suoratoisto ja erän nieleminen
- Cloud Data Warehouse Concepts – Panoply
- ensisijaiset avaimet
- Inkrementaaliavaimet
- sisäkkäiset tiedot
- Historiataulukot
- muunnokset
- Merkkijonomuodot
- Tietosuoja
- kulunvalvonta
- IP-Whitelisting
- Conclusion: Traditional vs. Data Warehouse Concepts in Brief
- perinteiset tietovaraston käsitteet
- Cloud Data Warehouse Concepts – Amazon Redshift esimerkkinä
- Cloud Data Warehouse Concepts-BigQuery esimerkkinä
- perinteinen vs. pilvi kustannus-hyötyanalyysi
- lisätietoja tietovarastoista
perinteiset Tietovarastokonseptit
tietovarasto on mikä tahansa järjestelmä, joka kokoaa tietoa organisaation eri lähteistä. Tietovarastoja käytetään keskitettyinä tietovarastoina analysointi-ja raportointitarkoituksiin.
perinteinen tietovarasto sijaitsee paikan päällä toimistoissanne. Hankit laitteiston, palvelinhuoneet ja palkkaat henkilökunnan johtamaan sitä. Niitä kutsutaan myös on-prem – tietovarastoiksi tai (kieliopillisesti virheellisiksi) on-prem-tietovarastoiksi.
Facts, Dimensions, and Measures
tietovaraston tietojen Keskeiset rakenneosat ovat faktat, ulottuvuudet ja toimenpiteet.
tieto on se osa tietojasi, joka osoittaa tietyn tapahtuman tai tapahtuman. Esimerkiksi, jos yrityksesi myy kukkia, jotkut tosiasiat näkisit tietovarastossa ovat:
- myi 30 ruusua 19 dollarilla.99
- tilannut Kiinasta 500 uutta kukkaruukkua 1 500 dollarilla
- maksettua kassan palkkaa tältä kuultä $1000
useat numerot voivat kuvata jokaista tosiasiaa, ja kutsumme näitä numeroita toimenpiteiksi. Joitakin toimenpiteitä kuvaamaan sitä, “tilattu 500 uutta kukkaruukkuja Kiinasta $1500” ovat:
- tilattu määrä-500
- kustannukset – $1500
kun analyytikot työskentelevät tietojen kanssa, he tekevät laskelmia toimenpiteistä (esim.summa, maksimi, keskiarvo) poimiakseen oivalluksia. Haluat esimerkiksi tietää, kuinka monta kukkaruukkua tilaat keskimäärin joka kuukausi.
a – dimensio luokittelee faktat ja mittarit ja antaa niille jäsenneltyä merkintätietoa-muuten ne olisivat vain kokoelma järjestämättömiä numeroita! Jotkut mitat kuvaamaan sitä, “tilattu 500 uutta kukkaruukkuja Kiinasta $1500” ovat:
- Ostomaa-Kiina
- ostoaika – klo 13
- arvioitu saapumispäivä – 6. kesäkuuta
et voi tehdä mittoja koskevia laskelmia eksplisiittisesti, eikä siitä todennäköisesti olisi kovin paljon apua – miten löydät “tilausten keskimääräisen saapumispäivän”? Ulottuvuuksista on kuitenkin mahdollista luoda uusia toimenpiteitä, joista on hyötyä. Jos esimerkiksi tiedät, kuinka monta päivää tilauspäivän ja saapumispäivän välillä on keskimäärin, voit suunnitella varastoostot paremmin.
normalisointi ja Denormalisointi
normalisointi on prosessi, jossa data organisoidaan tehokkaasti tietovarastossa (tai missä tahansa muussa paikassa, jossa tietoja säilytetään). Päätavoitteet ovat vähentää tietojen redundanssia – eli poistaa mahdolliset päällekkäiset tiedot – ja parantaa tietojen eheyttä-eli parantaa tietojen tarkkuutta. Normalisoinnissa on eri tasoja, eikä “parhaasta” menetelmästä ole yksimielisyyttä. Kaikissa menetelmissä on kuitenkin kyse erillisten mutta toisiinsa liittyvien tietojen tallentamisesta eri taulukoihin.
normalisoinnissa on monia etuja, kuten:
- nopeampi haku ja lajittelu jokaisessa taulukossa
- yksinkertaisemmat taulukot tekevät datan muokkauskomennoista nopeampia kirjoittamaan ja suorittamaan
- vähemmän turhaa dataa tarkoittaa levytilan säästämistä, joten voit kerätä ja tallentaa enemmän tietoa
Denormalisointi on prosessi, jossa jo normalisoituneeseen dataan lisätään tarkoituksellisesti turhia kopioita tai tietoryhmiä. Se ei ole sama kuin normalisoimattomat tiedot. Denormalisointi parantaa lukutehoa ja helpottaa taulukoiden muokkaamista haluamiisi muotoihin. Kun analyytikot työskentelevät tietovarastojen kanssa, he tyypillisesti vain lukevat tietoja. Näin, denormalisoitu data voi säästää niitä valtavia määriä aikaa ja päänsärkyä.
Denormalisaation hyödyt:
- vähemmän taulukoita minimoi taulukkoliittymien tarpeen, mikä nopeuttaa data-analyytikoiden työnkulkua ja saa heidät löytämään hyödyllisempiä oivalluksia tiedoista
- vähemmän taulukoita yksinkertaistaa kyselyjä, jotka johtavat vähemmän bugeja
tietomallit
olisi hurjan tehotonta tallentaa kaikki tietosi yhteen massiiviseen taulukkoon. Niin, tietovarastosi sisältää monia taulukoita, jotka voit liittää yhteen saada tiettyjä tietoja. Päätaulua kutsutaan faktataulukoksi, ja ulottuvuustaulukot ympäröivät sitä.
ensimmäinen vaihe tietovaraston suunnittelussa on rakentaa käsitteellinen tietomalli, joka määrittelee haluamasi datan ja niiden väliset korkean tason suhteet.
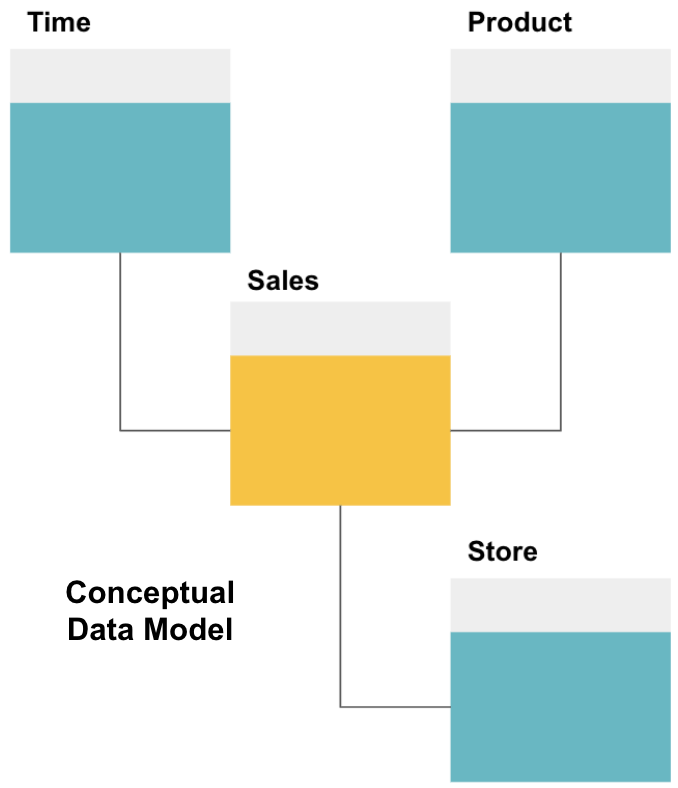
tässä on määritelty käsitteellinen malli. Tallennamme myyntitietoja ja meillä on kolme muuta taulukkoa – aika, tuote ja myymälä – jotka tarjoavat ylimääräistä, tarkempaa tietoa jokaisesta myynnistä. Faktataulukko on myynti ja muut ovat ulottuvuustaulukoita.
seuraava vaihe on loogisen tietomallin määrittely. Tämä malli kuvaa tiedot yksityiskohtaisesti selkokielellä ilman huolta siitä, miten se toteutetaan koodina.
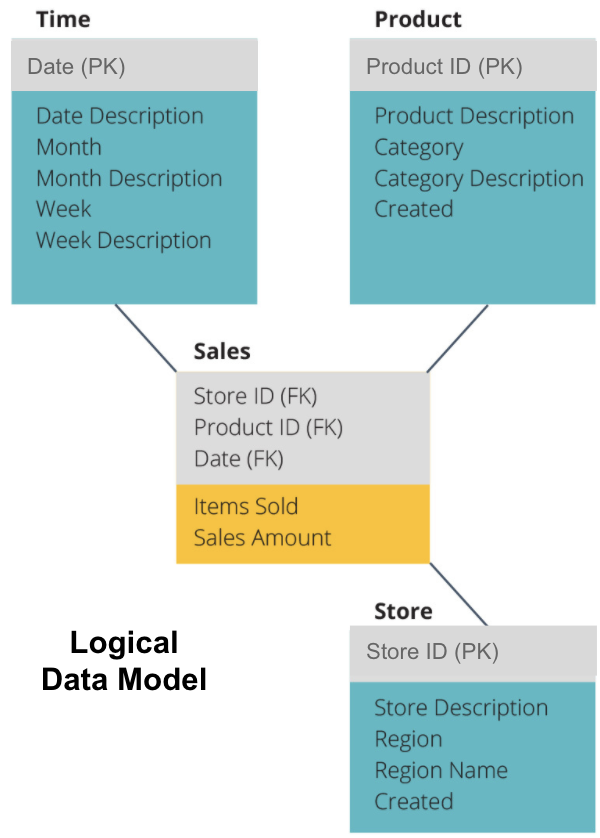
nyt olemme täyttäneet, mitä tietoja kukin taulukko sisältää selkokielellä. Kussakin aika -, tuote-ja Myymäläulottuvuustaulukossa on ensisijainen avain (PK) harmaassa laatikossa ja vastaavat tiedot sinisissä laatikoissa. Myyntitaulukossa on kolme ulkomaista avainta (FK), jotta se voi nopeasti liittyä muiden pöytien joukkoon.
viimeisessä vaiheessa luodaan fyysinen tietomalli. Tämä malli kertoo, miten tietovarasto toteutetaan koodina. Se määrittelee taulukot, niiden rakenteen ja niiden välisen suhteen. Siinä määritellään myös sarakkeiden tietotyypit, ja kaikki nimetään sellaisiksi kuin ne ovat lopullisessa tietovarastossa, eli kaikki korkit ja niihin on liitetty alaviivoja. Lopuksi, jokainen dimension taulukko alkaa DIM_, ja jokainen faktataulukko alkaa FACT_.
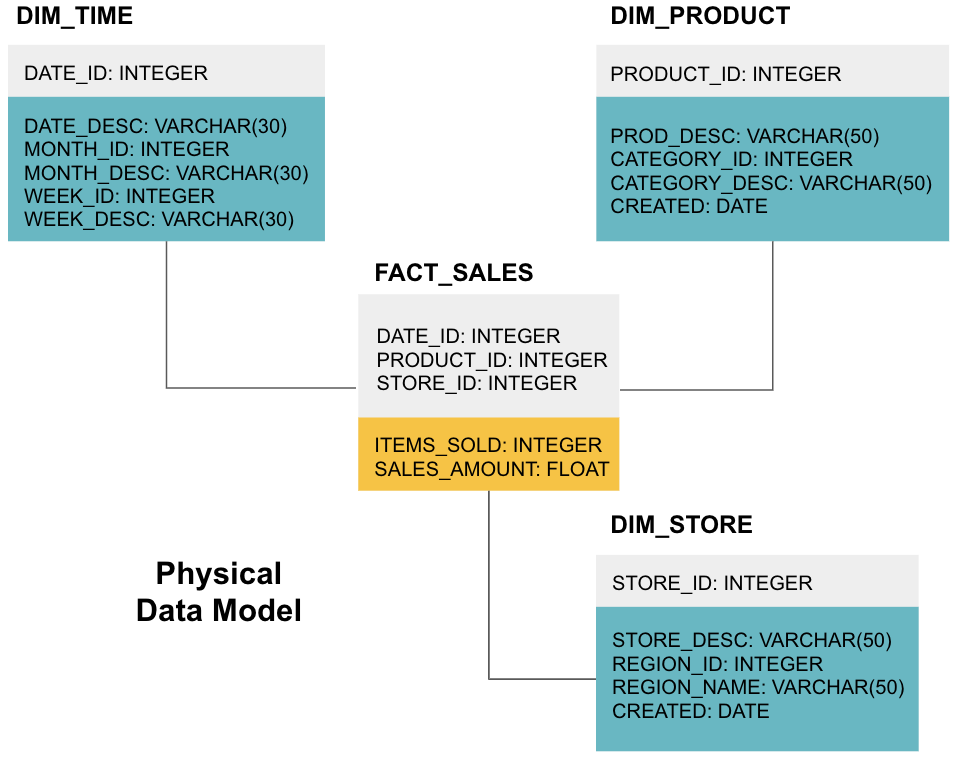
nyt osaat suunnitella tietovaraston, mutta on olemassa muutamia vivahteita tosiasia ja ulottuvuus taulukoita, jotka selitämme seuraavaksi.
Faktataulukko
jokaisella yritystoiminnolla – esimerkiksi myynnillä, markkinoinnilla, rahoituksella – on vastaava faktataulukko.
Faktataulukoissa on kahdenlaisia sarakkeita: muuttujasarakkeita ja faktasarakkeita. Mittapylväät-esimerkeissämme harmaat-sisältävät ulkomaisia avaimia (FK), joiden avulla voit liittyä faktataulukkoon, jossa on ulottuvuustaulukko. Nämä ulkomaiset avaimet ovat ensisijainen avaimet (PK) kunkin ulottuvuus taulukoita. Faktapalstat-esimerkeissämme keltainen – sisältävät analysoitavat todelliset tiedot ja mittarit, esimerkiksi myytyjen tuotteiden määrän ja myynnin dollarimäärän.
faktataulukko on tietyntyyppinen faktataulukko, jossa on vain dimension sarakkeita. Tällaiset taulukot ovat hyödyllisiä tapahtumien seurannassa, kuten opiskelijoiden läsnäolo tai työntekijöiden lomat, koska mitat kertovat kaiken, mitä sinun tarvitsee tietää tapahtumista.
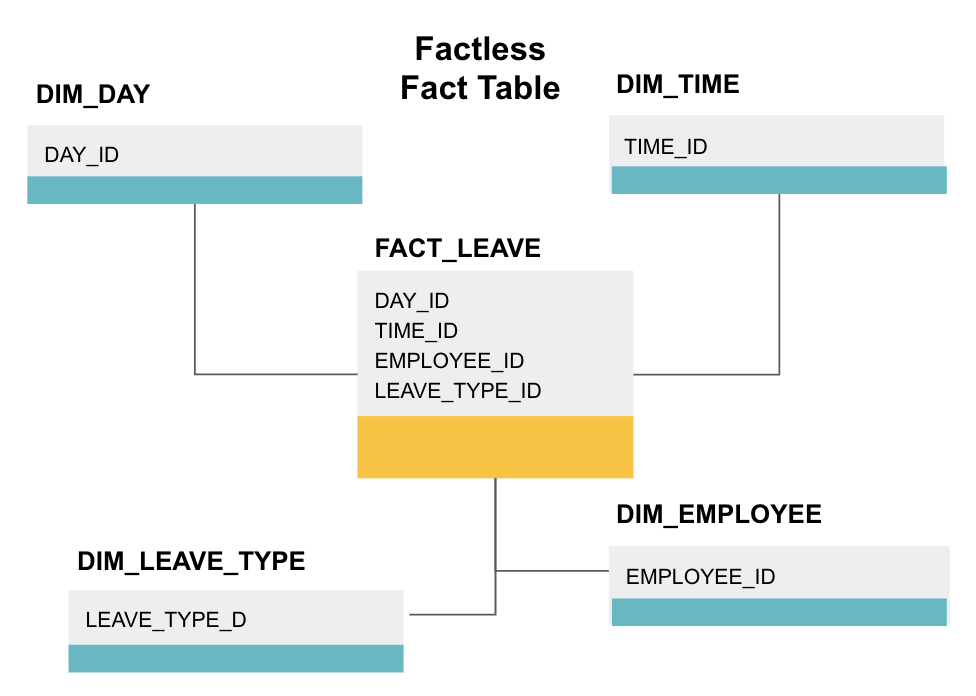
yllä oleva faktataulukko seuraa työntekijöiden lomia. Ei ole faktoja, koska sinun tarvitsee vain tietää:
- mikä päivä ne olivat pois (DAY_ID).
- kuinka kauan he olivat poissa (TIME_ID).
- joka oli virkavapaalla (TYÖNTEKIJÄ_ID).
- heidän virkavapautensa syy, esim., sairaus, loma, lääkärin vastaanotto jne. (LEAVE_TYPE_ID).
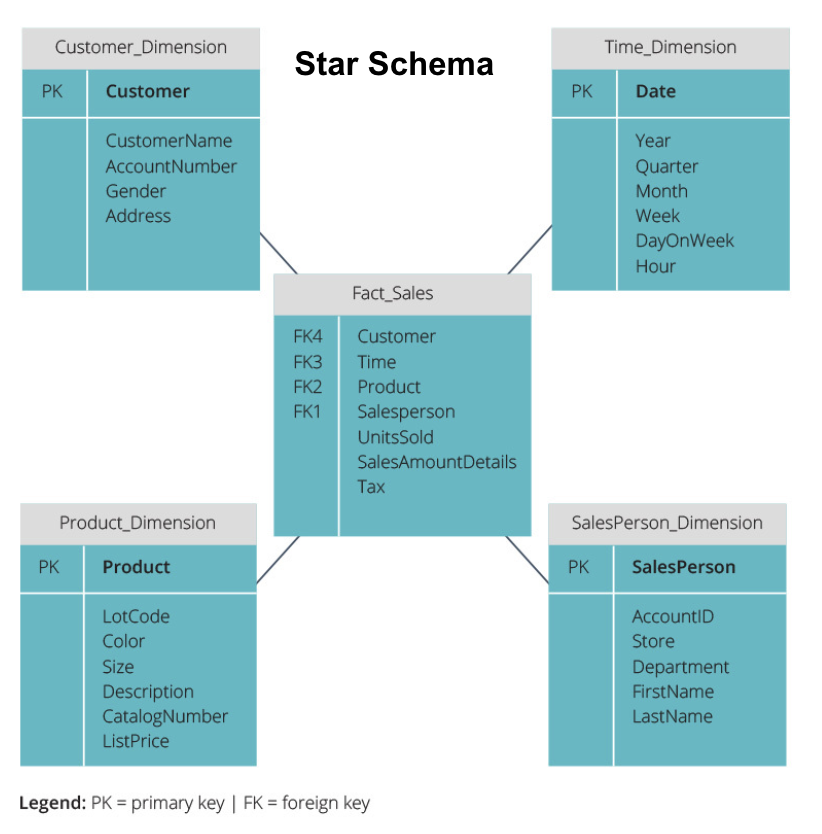
Tähtikaavio vs. lumihiutale-skeema
yllä olevissa tietovarastoissa on kaikissa ollut samanlainen asettelu. Tämä ei kuitenkaan ole ainoa tapa järjestää niitä.
kaksi yleisintä tietovarastojen järjestämiseen käytettyä skeemaa ovat tähti ja lumihiutale. Molemmissa menetelmissä käytetään muuttujataulukoita, jotka kuvaavat faktataulukon sisältämiä tietoja.
tähtikaavio ottaa tiedon faktataulukosta ja jakaa sen denormalisoituihin ulottuvuustaulukoihin. Tähtikaavion painopiste on kyselynopeudessa. Vain yksi liittymä tarvitaan liittämään faktataulukot jokaiseen ulottuvuuteen, joten jokaisen taulukon kyseleminen on helppoa. Koska taulukot ovat kuitenkin denormalisoituja, ne sisältävät usein toistuvaa ja turhaa tietoa.
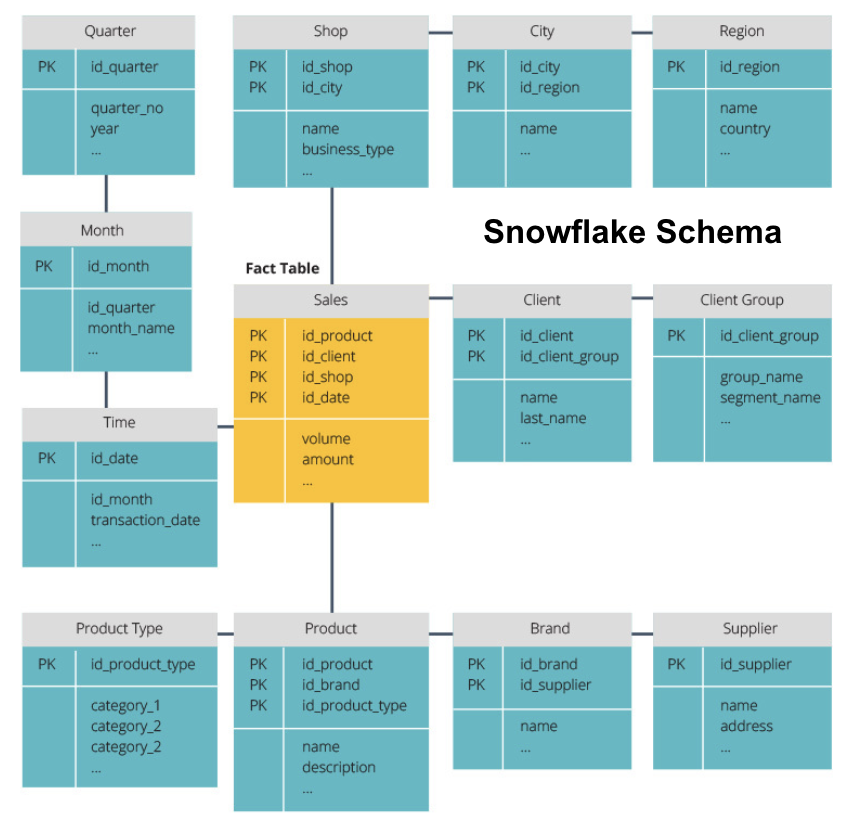
lumihiutale-skeema jakaa faktataulukon sarjaan normalisoituja ulottuvuustaulukoita. Normalisointi luo enemmän ulottuvuustaulukoita ja vähentää siten tietojen eheysongelmia. Snowflake-skeeman käyttäminen on kuitenkin haastavampaa, koska tarvitset enemmän taulukkoliittimiä, jotta pääset käsiksi olennaisiin tietoihin. Niin, sinulla on vähemmän tarpeettomia tietoja,mutta se on vaikeampi päästä.
nyt selitämme perusteellisempia tietovaraston käsitteitä.
OLAP vs. OLTP
online transaction processing (OLTP) on ominaista lyhyet kirjoitustapahtumat, joihin liittyy yrityksen tietoarkkitehtuurin etupään sovelluksia. OLTP-tietokannat korostavat nopeaa kyselyjen käsittelyä ja käsittelevät vain ajankohtaisia tietoja. Yritykset käyttävät näitä tietojen keräämiseen liiketoimintaprosesseja varten ja lähdetietojen toimittamiseen tietovarastolle.
Online analyyttinen käsittely (OLAP) mahdollistaa monimutkaisten lukukyselyiden suorittamisen ja siten historiallisen tapahtumatiedon yksityiskohtaisen analyysin suorittamisen. OLAP järjestelmät auttavat analysoimaan tietoja tietovarastossa.
Kolmitasoarkkitehtuuri
perinteiset tietovarastot rakentuvat tyypillisesti kolmeen tasoon:
- alempi taso: tietokantapalvelin, tyypillisesti RDBMS, joka poimii tietoja eri lähteistä yhdyskäytävän avulla. Tälle tasolle syötettyjä tietolähteitä ovat operatiiviset tietokannat ja muunlaiset etupään tiedot, kuten CSV-ja JSON-tiedostot.
- Middle Tier: OLAP-palvelin, joka joko
- toteuttaa operaatiot suoraan, tai
- kartoittaa moniulotteisen datan operaatiot standardirelaatio-operaatioihin, esim.litistäen XML-tai JSON-datan riveihin taulukoissa.
- Top Tier: tietojen analysoinnin ja liiketoimintatiedon tiedustelu-ja raportointityökalut.
Virtual Data Warehouse / Data Mart
virtuaalinen tietovarasto käyttää hajautettuja kyselyjä useissa tietokannoissa integroimatta tietoja yhteen fyysiseen tietovarastoon.
datamarketit ovat tietovarastojen osajoukkoja, jotka on suunnattu tiettyihin liiketoiminnan toimintoihin, kuten myyntiin tai rahoitukseen. Tietovarasto yhdistää tyypillisesti useiden datamarkettien tietoja useassa liiketoiminnassa. Silti, data mart sisältää tietoja joukko lähdejärjestelmiä yhden liiketoiminnan toiminto.
Kimball vs. Inmon
tietovaraston suunnitteluun on olemassa kaksi lähestymistapaa, joita ovat ehdottaneet Bill Inmon ja Ralph Kimball. Bill Inmon on yhdysvaltalainen tietojenkäsittelytieteilijä, joka tunnetaan tietovaraston isänä. Ralph Kimball on yksi tietovarastoinnin alkuperäisistä arkkitehdeista ja on kirjoittanut aiheesta useita kirjoja.
näillä kahdella asiantuntijalla oli ristiriitaisia mielipiteitä siitä, miten tietovarastot tulisi jäsentää. Tämä konflikti on synnyttänyt kaksi koulukuntaa.
Inmonin lähestymistapa on ylhäältä alas suunniteltu. Inmonin metodologialla tietovarasto luodaan ensin ja se nähdään analyyttisen ympäristön keskeisenä komponenttina. Tiedot sitten tiivistetään ja jaetaan keskitetystä varastosta yhteen tai useampaan riippuvaiseen datamarkettiin.
Kimball-lähestymistapa ottaa alhaalta ylöspäin suuntautuvan näkemyksen tietovaraston suunnittelusta. Tässä arkkitehtuurissa organisaatio luo erillisiä datamarketteja, jotka tarjoavat näkymiä organisaation yksittäisiin osastoihin. Tietovarasto on näiden datamarkettien yhdistelmä.
ETL vs. ELT
Extract, Transform, Load (ETL) kuvaa prosessia, jossa tiedot otetaan lähdejärjestelmistä (tyypillisesti transaktiojärjestelmistä), muunnetaan kyselyä ja analysointia varten sopivaan muotoon tai rakenteeseen ja lopuksi Ladataan tietovarastoon. ETL käyttää erillistä valmistelutietokantaa ja soveltaa poimittuihin tietoihin useita sääntöjä tai toimintoja ennen lataamista.
Extract, Load, Transform (ELT) on erilainen lähestymistapa lataustietoihin. ELT ottaa tiedot eri lähteistä ja lataa ne suoraan kohdejärjestelmään, kuten tietovarastoon. Tämän jälkeen järjestelmä muuntaa ladatut tiedot tilauksesta analysoinnin mahdollistamiseksi.
ELT tarjoaa ETL: ää nopeamman latauksen, mutta se vaatii tehokkaan järjestelmän tietojen muuntamiseen tilauksesta.
Yritystietovarasto
yritystietovarasto on tarkoitettu yhtenäiseksi, keskitetyksi varastoksi, joka sisältää kaikki organisaation tapahtumatiedot, sekä nykyiset että historialliset tiedot. Yritystietovaraston tulisi sisältää tietoja kaikista liiketoimintaan liittyvistä aihealueista, kuten markkinoinnista, myynnistä, rahoituksesta ja henkilöresursseista.
nämä ovat perinteisiä tietovarastoja muodostavia ydinajatuksia. Nyt katsotaan, mitä pilvitietovarastot ovat lisänneet niiden päälle.
Pilvitietovaraston konseptit
Pilvitietovarastot ovat uusia ja jatkuvasti muuttuvia. Jotta ymmärtäisit parhaiten heidän peruskäsitteensä, on parasta tutustua johtaviin pilvitietovaraston ratkaisuihin.
kolme johtavaa pilvitietovaraston ratkaisua ovat Amazon Redshift, Google BigQuery ja Panoply. Alla selitämme kunkin palvelun peruskäsitteitä, jotta saat yleiskuvan siitä, miten nykyaikaiset tietovarastot toimivat.
Cloud Data Warehouse Concepts – Amazon Redshift
seuraavia käsitteitä käytetään eksplisiittisesti Amazon Redshift cloud data Warehousessa, mutta niitä voidaan tulevaisuudessa soveltaa myös Amazonin infrastruktuuriin perustuviin tietovaraston lisäratkaisuihin.
klusterit
Amazonin Punasiirtymä perustaa arkkitehtuurinsa klustereihin. Klusteri on yksinkertaisesti joukko jaettuja laskentaresursseja, joita kutsutaan solmuiksi.
solmut
solmut ovat laskentaresursseja, joissa on suoritin -, RAM-ja kiintolevytilaa. Klusteri, jossa on kaksi tai useampia solmuja, koostuu leader-solmusta ja laskusolmuista.
Leader-solmut kommunikoivat asiakasohjelmien kanssa ja kokoavat koodin kyselyiden suorittamiseen, jolloin se annetaan solmujen laskemiseen. Laske solmut suorita kyselyt ja palauttaa tulokset leader solmu. Laskusolmu suorittaa vain kyselyjä, jotka viittaavat kyseiseen solmuun tallennettuihin taulukoihin.
osiot/viipaleet
Amazon-osiot jokainen laskee solmun viipaleiksi. Siivu saa osuutensa muistista ja levytilasta solmussa. Useat viipaleet toimivat rinnakkain kyselyn suoritusajan nopeuttamiseksi.
Pylväsvarasto
Punasiirtymä käyttää pylväsvarastoa, mikä mahdollistaa paremman analyyttisen kyselyn suorituskyvyn. Sen sijaan, että se tallentaisi tietueet riveihin, se tallentaa arvot yhdestä sarakkeesta useille riveille. Seuraavat kaaviot selventävät tätä:
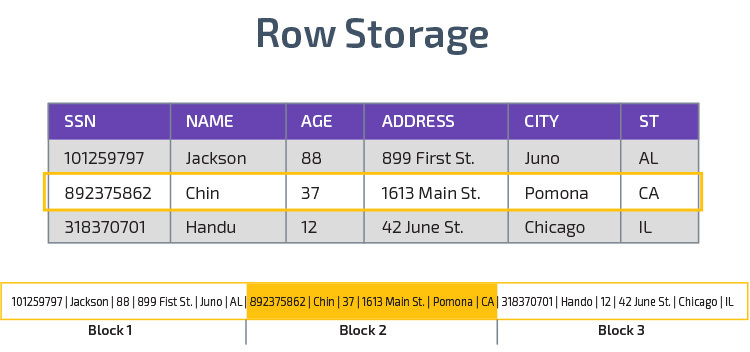
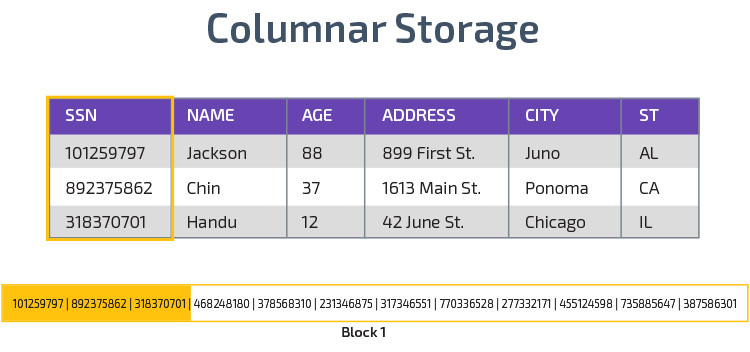
Columnar-tallennus mahdollistaa tietojen lukemisen nopeammin, mikä on ratkaisevan tärkeää analyyttisissä kyselyissä, jotka kattavat useita sarakkeita datajoukossa. Columnar varastointi vie myös vähemmän levytilaa, koska jokainen lohko sisältää samantyyppisiä tietoja, eli se voidaan pakata tiettyyn muotoon.
Pakkaus
pakkaus pienentää tallennetun tiedon kokoa. Punasiirtymässä tietojen tallennustavan vuoksi pakkautuminen tapahtuu saraketasolla. Punasiirtymän avulla voit pakata tietoja manuaalisesti taulukkoa luotaessa tai automaattisesti KOPIOINTIKOMENNOLLA.
tietojen lataus
voit käyttää Redshiftin kopiointikomentoa lataamaan suuria määriä dataa tietovarastoon. KOPIOINTIKOMENTO käyttää Redshiftin MPP-arkkitehtuuria tietojen lukemiseen ja lataamiseen rinnakkain Amazon S3: n tiedostoista, DynamoDB-taulukosta tai yhden tai useamman etäpalvelimen tekstilähdöstä.
tietoja on myös mahdollista suoratoistaa Punasiirtymään Amazon Kinesis Firehose-palvelun avulla.
Cloud Database Warehouse – Google BigQuery
seuraavia käsitteitä käytetään nimenomaisesti Google BigQueryn pilvitietovarastossa, mutta niitä voidaan soveltaa tulevaisuudessa Googlen infrastruktuuriin perustuviin lisäratkaisuihin.
Palvelematon palvelu
BigQuery käyttää palvelematonta arkkitehtuuria. BigQueryn avulla yritysten ei tarvitse hallita fyysisiä palvelinyksiköitä suorittaakseen tietovarastojaan. Sen sijaan BigQuery hallinnoi dynaamisesti laskentaresurssiensa jakamista. Palvelua käyttävät yritykset maksavat vain tietojen tallennuksesta gigatavua kohden ja kyselyistä teratavua kohden.
Colossus File System
BigQuery käyttää Googlen hajautetun tiedostojärjestelmän uusinta versiota, koodinimeltään Colossus. Colossus-tiedostojärjestelmä käyttää columnar-tallennus-ja pakkausalgoritmeja datan tallentamiseen analyyttisiin tarkoituksiin optimaalisesti.
Dremel Execution Engine
Dremel execution engine käyttää pylväsmäistä asettelua kysyäkseen nopeasti suuria tietovarastoja. Dremelin suoritusmoottori voi suorittaa ad hoc-kyselyjä miljardeilla riveillä sekunneissa, koska se käyttää massiivisesti rinnakkaista käsittelyä puuarkkitehtuurin muodossa.
puuarkkitehtuuri jakaa kyselyt useille juuripalvelimen välipalvelimille. Välipalvelimet työntävät kyselyn alas Leaf-palvelimille (jotka sisältävät tallennettua tietoa), jotka skannaavat tiedot rinnakkain. Paluumatkalla puuhun jokainen leaf-palvelin lähettää kyselytuloksia, ja välipalvelimet suorittavat osittaisten tulosten rinnakkaisen yhdistelyn.
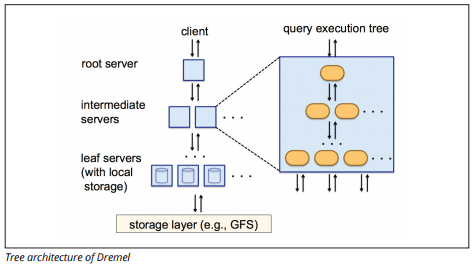
Image source
Dremel antaa organisaatioille mahdollisuuden suorittaa kyselyjä jopa kymmenillätuhansille palvelimille samanaikaisesti. Dremel pystyy Googlen mukaan skannaamaan 35 miljardia riviä ilman indeksiä kymmenissä sekunneissa.
tietojen jakaminen
Google BigQueryn palvelimeton arkkitehtuuri mahdollistaa sen, että yritykset voivat helposti jakaa tietoja muiden organisaatioiden kanssa ilman, että näiden organisaatioiden tarvitsee investoida omaan tallennustilaansa.
organisaatiot, jotka haluavat tiedustella jaettua dataa, voivat tehdä niin, ja he maksavat vain kyselyistä. Ei ole tarvetta luoda kalliita jaettuja datasiiloja, jotka ovat organisaation datainfrastruktuurin ulkopuolisia, ja kopioida tiedot näihin siiloihin.
suoratoisto ja erän nieleminen
Google Cloud Storagesta on mahdollista ladata tietoja BigQueryyn, mukaan lukien CSV, JSON (newline-karsittu) ja Avro-tiedostot sekä Google Cloud Datastore-varmuuskopiot. Voit myös ladata tietoja suoraan luettavasta tietolähteestä.
BigQuery tarjoaa myös Streamausrajapinnan, jolla voi ladata dataa järjestelmään miljoonien rivien sekuntivauhdilla suorittamatta kuormaa. Aineisto saadaan analysoitavaksi lähes välittömästi.
Cloud Data Warehouse Concepts – Panoply
Panoply on monitoimivarasto, joka yhdistää ETL: n tehokkaaseen tietovarastoon. Se on helpoin tapa synkronoida, tallentaa ja käyttää yrityksen tietoja poistamalla big datan muuntamiseen, integrointiin ja hallintaan liittyvä kehitys ja koodaus.
alla on muutamia Panoplyn tietovaraston pääkäsitteitä, jotka liittyvät tiedon mallintamiseen ja tietosuojaan.
ensisijaiset avaimet
ensisijaiset avaimet varmistavat, että kaikki taulukoiden rivit ovat yksilöllisiä. Jokaisessa taulukossa on yksi tai useampi ensisijainen avain, joka määrittää, mikä edustaa yhtä ainutkertaista riviä tietokannassa. Kaikissa sovellusliittymissä on oletusavain taulukoille.
Inkrementaaliavaimet
Panoply käyttää inkrementaaliavainta ohjatakseen attribuutteja, jotka lataavat tietoa tietovarastoon vaiheittain lähteistä, sen sijaan että lataisivat koko aineiston uudelleen joka kerta, kun jokin muuttuu. Tämä ominaisuus on hyödyllinen suuremmille tietokokonaisuuksille, jotka voivat kestää kauan lukea enimmäkseen muuttumattomia tietoja. Inkrementaaliavain ilmaisee kyseisen tietolähteen rivien viimeisen päivityspisteen.
sisäkkäiset tiedot
sisäkkäiset tiedot eivät ole täysin yhteensopivia BI—suitien ja standardikyselyiden kanssa-Panoply käsittelee sisäkkäisiä tietoja käyttämällä vahvaa relaatiomallia, joka ei salli sisäkkäisiä arvoja. Panoply muuntaa sisäkkäisiä tietoja näillä tavoilla:
- Subtables: oletuksena, Panoply muuntaa sisäkkäisiä tietoja joukoksi monia-to-monet tai yksi-to-monet relaatiotaulukot, jotka ovat litteitä relaatiotauluja.
- litistyminen: kun tämä tila on käytössä, Panoply litistää sisäkkäisen rakenteen sen sisältävälle tietueelle.
Historiataulukot
joskus tietoja on analysoitava seuraamalla ajan mittaan muuttuvia tietoja, jotta voidaan nähdä, miten tiedot tarkalleen muuttuvat (esimerkiksi ihmisten osoitteet).
tällaisten analyysien tekemiseen Panoply käyttää Historiataulukoita, jotka ovat aikasarjataulukoita, jotka sisältävät historiallisia tilannekuvia alkuperäisen staattisen taulukon jokaisesta rivistä. Voit sitten suorittaa yksinkertaisen kyselytutkimuksen alkuperäisestä taulukosta tai taulukon tarkistuksista kelaamalla mihin tahansa ajankohtaan.
muunnokset
Panoply käyttää ELT: tä, joka on muunnelma alkuperäisestä ETL-tiedon integraatioprosessista. Kun olet syöttänyt lähteestä peräisin olevaa tietoa tietovarastoosi, Panoply muuntaa sen välittömästi. Tämä prosessi tarjoaa reaaliaikaisen data-analyysin ja optimaalisen suorituskyvyn verrattuna tavalliseen ETL-prosessiin.
Merkkijonomuodot
Panoply jäsentää merkkijonomuotoja ja käsittelee niitä kuin ne olisivat sisäkkäisiä olioita alkuperäisessä aineistossa. Tuettuja merkkijonomuotoja ovat CSV, TSV, JSON, JSON-Line, Ruby object format, URL-kyselymerkkijonot ja web-jakelulokeja.
Tietosuoja
Panoply on rakennettu AWS: n päälle, joten siinä on uusimmat AWS: n tarjoamat tietoturvakorjaukset ja salausominaisuudet, mukaan lukien laitteistokiihdytetty RSA-salaus ja Amazon Redshiftin erityiset turvaominaisuudet.
lisäsuojaus tulee columnar-salauksesta, jonka avulla voit käyttää yksityisiä avaimia, joita ei ole tallennettu Panoplyn palvelimille.
kulunvalvonta
Panoply käyttää kaksivaiheista verifiointia luvattoman käytön estämiseksi, ja käyttöoikeusjärjestelmän avulla voit rajoittaa pääsyä tiettyihin taulukoihin, näkymiin tai sarakkeisiin. Anomalian havaitseminen tunnistaa uusista tietokoneista tai eri maasta tulevat kyselyt, jolloin voit estää nämä kyselyt, ellei niille anneta manuaalista hyväksyntää.
IP-Whitelisting
suosittelemme, että estät yhteydet tunnistamattomista lähteistä palomuurin tai AWS-suojausryhmän avulla ja luetteloit IP-osoitteet, joita Panoplyn tietolähteet käyttävät aina tietokantaasi päästessäsi.
Conclusion: Traditional vs. Data Warehouse Concepts in Brief
to wrap up, we ‘ ll summary the concepts introduced in this document.
perinteiset tietovaraston käsitteet
- Faktat ja mittarit: mitta on ominaisuus, josta voidaan tehdä laskelmia. Viittaamme toimenpidekokonaisuuteen faktoina,mutta joskus termejä käytetään keskenään.
- normalisointi: prosessi, jossa vähennetään päällekkäisen tiedon määrää, mikä johtaa muistitehokkaampaan tietovarastoon, joka on hitaampi kyselemään.
- ulottuvuus: käytetään faktojen ja toimenpiteiden luokitteluun ja kontekstualisointiin mahdollistaen näiden toimenpiteiden analysoinnin ja raportoinnin.
- käsitteellinen tietomalli: määrittelee kriittiset korkean tason tietoyksiköt ja niiden väliset suhteet.
- looginen tietomalli: Kuvaa datasuhteita, entiteettejä ja attribuutteja selkokielellä ilman huolta siitä, miten se toteutetaan koodina.
- fyysinen tietomalli: esitys siitä, miten tietomalli toteutetaan tietyssä tietokannan hallintajärjestelmässä.
- Tähtikaavio: ottaa faktataulukon ja jakaa sen tiedot denormalisoituihin ulottuvuustaulukoihin.
- lumihiutale skeema: jakaa faktataulukon normalisoituneisiin ulottuvuustaulukoihin. Normalisointi vähentää tietojen redundanssiongelmia ja parantaa tietojen eheyttä, mutta kyselyt ovat monimutkaisempia.
- OLTP: Online-tapahtumankäsittelyjärjestelmät helpottavat nopeaa, tapahtumakeskeistä käsittelyä yksinkertaisilla kyselyillä.
- OLAP: Online-analyyttinen käsittely mahdollistaa monimutkaisten lukukyselyiden suorittamisen ja siten historiallisen tapahtumatiedon yksityiskohtaisen analyysin suorittamisen.
- Datamart: tiettyyn aiheeseen tai osastoon keskittyvä tietoarkisto organisaatiossa.
- Inmonin lähestymistapa: Bill Inmonin data warehouse-lähestymistapa määrittelee tietovaraston koko yrityksen keskitetyksi tietovarastoksi. Tietovarastosta voidaan rakentaa datamarketteja palvelemaan eri osastojen analyyttisiä tarpeita.
- Kimball approach: Ralph Kimball kuvaa tietovarastoa tehtäväkriittisten datamarkettien yhdistämiseksi, jotka on ensin luotu palvelemaan eri osastojen analyyttisiä tarpeita.
- ETL: integroi tiedot tietovarastoon irrottamalla ne eri transaktiolähteistä, muuntamalla tiedot optimoidakseen ne analysointia varten ja lopuksi lataamalla ne tietovarastoon.
- ELT: Muunnelma ETL: stä, joka poimii raakaa dataa organisaation tietolähteistä ja lataa sen tietovarastoon. Tarvittaessa se muunnetaan analyyttisiin tarkoituksiin.
- Yritystietovarasto: EDW: ssä kootaan tietoja kaikilta yritykseen liittyviltä aihealueilta.
Cloud Data Warehouse Concepts – Amazon Redshift esimerkkinä
- Cluster: pilveen perustuva jaettujen laskentaresurssien ryhmä.
- solmu: klusterin sisällä oleva laskentaresurssi. Jokaisella solmulla on oma suoritin, RAM ja Kiintolevytila.
- Pylväsvarasto: Tämä tallentaa taulukon arvot sarakkeisiin rivien sijaan, mikä optimoi tiedot yhdistettyjä kyselyjä varten.
- Pakkaus: tallennetun tiedon koon pienentämiseen tähtäävät tekniikat.
- tietojen lataus: tietojen saaminen lähteistä pilvipohjaiseen tietovarastoon. Redshiftissä voi käyttää kopiointikomentoa tai datan suoratoistopalvelua.
Cloud Data Warehouse Concepts-BigQuery esimerkkinä
- Serverless service: pilvipalvelujen tarjoaja hallinnoi dynaamisesti koneresurssien jakamista käyttäjän kuluttaman määrän perusteella. Pilvipalvelujen tarjoaja piilottaa palvelinhallinta-ja kapasiteettisuunnittelupäätökset palvelun käyttäjiltä.
- Colossus file system: hajautettu tiedostojärjestelmä, joka käyttää columnar-tallennus-ja tiedon pakkausalgoritmeja optimoimaan dataa analysointia varten.
- Dremel execution engine: kyselymoottori, joka käyttää massiivisesti rinnakkaista käsittelyä ja columnar-tallennustilaa kyselyjen nopeaan suorittamiseen.
- tietojen jakaminen: palveluttomassa palvelussa on käytännöllistä tiedustella toisen organisaation jaettua dataa panostamatta tietojen tallentamiseen—kyselyistä vain maksetaan.
- Streamausdata: datan syöttäminen reaaliajassa tietovarastoon suorittamatta kuormaa. Voit suoratoistaa tietoja eräpyynnöissä, jotka ovat useita API-puheluita yhdistettynä yhteen HTTP-pyyntöön.
perinteinen vs. pilvi kustannus-hyötyanalyysi
| kustannus / hyöty | perinteinen | pilvi |
| kustannukset | suuret ennakkokustannukset on-prem-järjestelmän ostamisesta ja asentamisesta. tarvitset laitteistoa, palvelinhuoneita ja erikoishenkilöstöä (jota maksat jatkuvasti). jos et ole varma, kuinka paljon säilytystilaa tarvitset, on olemassa riski uponneista kustannuksista, joita on vaikea saada takaisin. |
ei tarvitse ostaa laitteistoja, palvelinhuoneita tai palkata asiantuntijoita. uponneiden kustannusten riskiä ei ole – varastojen ostaminen tulevaisuudessa on helppoa. lisäksi tallennustilan ja laskentatehon kustannukset laskevat ajan myötä. |
| skaalautuvuus | kun olet maksimoinut nykyiset palvelinhuoneesi tai laitteistokapasiteettisi, saatat joutua ostamaan uutta laitteistoa ja rakentamaan/ostamaan lisää paikkoja sen asuttamiseksi. Plus, sinun täytyy ostaa tarpeeksi tallennustilaa selviytyäksesi ruuhka-ajoista; näin, suurimman osan ajasta, suurin osa tallennustilaa ei käytetä. |
voit helposti ostaa lisää tallennustilaa sitä mukaa kuin tarvitset. usein on vain maksettava siitä, mitä käyttää, joten ylikorvauksen riskiä ei juuri ole. |
| integraatiot | koska pilvilaskenta on normi, useimmat integraatiot, jotka haluat tehdä, tehdään pilvipalveluihin. mukautetun tietovaraston liittäminen niihin voi osoittautua haastavaksi. |
koska pilvitietovarastot ovat jo pilvessä, yhdistäminen useisiin muihin pilvipalveluihin on helppoa. |
| turvallisuus | sinulla on tietovarastosi täydellinen hallinta. verrattaessa tallennetun datan määrää Amazoniin tai Googleen olet pienempi varkaiden kohde. Saatat siis todennäköisemmin jäädä yksin. |
Pilvitietovaraston tarjoajilla on tiimit täynnä korkeasti koulutettuja tietoturvainsinöörejä, joiden ainoa tarkoitus on tehdä tuotteestaan mahdollisimman turvallinen. maailman merkittävimmät yritykset hallinnoivat niitä ja toteuttavat siksi maailmanluokan turvallisuuskäytäntöjä. |
| hallinnointi | tiedät tarkalleen missä tietosi ovat ja voit käyttää niitä paikallisesti. pienempi riski siitä, että erittäin arkaluonteinen tieto rikkoo tahattomasti lakia esimerkiksi matkustamalla ympäri maailmaa pilvipalvelimella. |
yläpilven tietovaraston tarjoajat varmistavat noudattavansa hallinto-ja tietoturvalakeja, kuten GDPR: ää. Lisäksi ne auttavat yritystäsi varmistamaan, että olet yhteensopiva. on ollut ongelmia sen suhteen, että tietäisit tarkalleen tietosi ja missä ne liikkuvat. Näitä ongelmia käsitellään ja ratkaistaan aktiivisesti. huomaa, että suurten määrien erittäin arkaluonteisia tietoja tallentaminen pilveen saattaa olla tiettyjen lakien vastaista. Tämä on yksi esimerkki, jossa cloud computing voi olla sopimatonta yrityksesi. |
| luotettavuus | jos on-prem-tietovarastosi pettää, on sinun vastuullasi korjata se. IT-tiimilläsi on pääsy fyysiseen laitteistoon ja se voi käyttää jokaista ohjelmistotasoa vianmääritykseen. Tämä nopea pääsy voi tehdä ongelmien ratkaisemisesta paljon nopeampaa. ei kuitenkaan ole mitään takeita siitä, että varastollasi olisi tietty määrä käyttöaikaa joka vuosi. |
Pilvitietovaraston tarjoajat takaavat luotettavuutensa ja käytettävyytensä SLAs-palveluissa. ne toimivat massiivisesti hajautetuissa järjestelmissä kaikkialla maailmassa, joten jos yhdessä on vika, se ei todennäköisesti vaikuta sinuun. |
| valvonta | tietovarastosi on räätälöity tarpeidesi mukaan. Teoriassa se tekee mitä haluaa, milloin haluaa, tavalla jonka ymmärtää. | sinulla ei ole täydellistä kontrollia tietovarastoosi. suurimman osan ajasta kontrolli on kuitenkin enemmän kuin tarpeeksi. |
| nopeus | jos olet pieni yritys yhdessä maantieteellisessä paikassa, jossa on pieni määrä dataa, tietojenkäsittely on nopeampaa. puhutaan kuitenkin millisekunneista vs. sekunneista joidenkin prosessien loppuunsaattamiseksi. useissa maissa toimiva suuryritys ei todennäköisesti näe merkittävää nopeusvoittoa on-prem-järjestelmällä. |
pilvipalvelujen tarjoajat ovat investoineet ja luoneet järjestelmiä, jotka toteuttavat massiivisesti Rinnakkaisprosessointia (MPP), räätälöityjä arkkitehtuuri-ja suoritusmoottoreita sekä älykkäitä tietojenkäsittelyalgoritmeja. Pilvitietovarastot ovat vuosien tutkimus-ja testaustyön tulosta, jonka tavoitteena on luoda nopeudelle ja suorituskyvylle optimoituja resursseja. joissakin tapauksissa se voi olla hieman hitaampaa kuin on-prem, mutta nämä viiveet ovat usein vähäisiä ihmisillä (sekunteja vs. millisekunteja). |
Panoply on turvallinen paikka tallentaa, synkronoida ja käyttää kaikkia liiketoimintatietojasi. Panoply voidaan perustaa minuuteissa, vaatii nolla käynnissä huolto, ja tarjoaa online-tukea, mukaan lukien pääsy kokeneita data arkkitehdit. Kokeile Panoply ilmaiseksi 14 päivän ajan.
lisätietoja tietovarastoista
- tietovaraston arkkitehtuuri: perinteinen vs. pilvi
- tietokanta vs. tietovarasto
- Datamart vs. tietovarasto