Clustering ja K Means: Definition & Cluster Analysis in Excel
tilastolliset määritelmät > ryhmittely / klusterianalyysi
mikä on ryhmittely?
tilastoissa ryhmittelyllä tarkoitetaan sitä, miten tietoja kerätään (“ryhmitellään”) sellaisten tekijöiden mukaan kuin:
- Ikä.
- kotitalouden koko.
- Tulot.
- tai koulutustaso.
tietojen lajittelu klustereiksi johtaa joskus tietojen tarkempaan tutkimiseen. Esimerkiksi syöpäryppäät voivat kertoa jostakin ongelmasta ympäristössä. Tai ne voivat johtua vain siitä, että luonto on sattumanvarainen. Klusterianalyysi on usein subjektiivinen; se riippuu siitä, mitä koet yleisinä säikeinä aineistossa. Tekniikka ei ole oikeastaan mitään uutta tilastoissa; jos olet joskus tehnyt pylväsdiagrammin, olet luultavasti jo tehnyt klustereita (vaikka et kutsunutkaan sitä siksi). Esimerkiksi, bar kuvaaja osoittaa koirarodut edellyttää klusterin rodun (Siperianhusky, Bordercollie, Saksanpaimenkoira…) tai kaavio tulotason voidaan ryhmitelty alhainen, keski-ja korkea tulotaso.
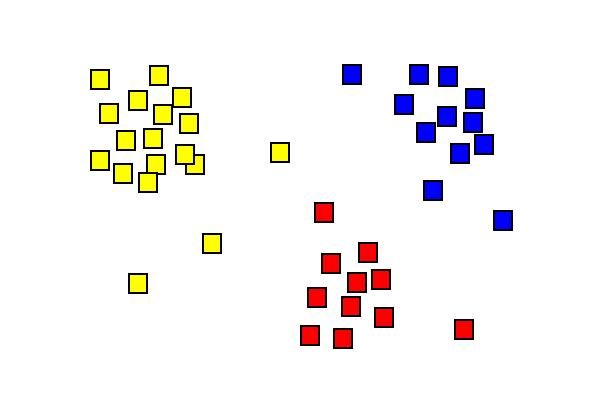
Klusterianalyysin tulokset osoittavat kolme eriväristä klusteria.
klusterit voivat perustua mm.:
- Etäisyysperusteista ryhmittelyä. Kohteet lajitellaan niiden läheisyyden (tai etäisyyden) perusteella. Esimerkiksi syöpätapaukset saattavat ryhmittyä yhteen, jos ne sijaitsevat samassa maantieteellisessä paikassa.
- käsitteellinen ryhmittely. Erät on ryhmitelty tekijöillä, jotka erillä on yhteistä. Esimerkiksi syöpärykelmät voitaisiin ryhmitellä ” teollisuudessa työskentelevien ihmisten mukaan.”
Ryhmittelytyypit
- Eksklusiiviset Ryhmittelyt. Kukin kohde voi kuulua vain yhteen ryppääseen. Se ei voi kuulua toiseen rykelmään.
- sumea ryhmittely: datapisteille annetaan todennäköisyys kuulua yhteen tai useampaan klusteriin.
- Päällekkäiset Ryhmittymät. Jokainen kohde voi kuulua useampaan kuin yhteen klusteriin.
- Hierarkkinen Ryhmittymä. Tämä on monimutkaisempi lähestymistapa klusterointia käytetään tiedonlouhinta. Periaatteessa jokaiselle kohteelle annetaan oma klusterinsa. Klusteripari yhdistyy yhtäläisyyksien perusteella, jolloin klusteri on yksi vähemmän. Tämä prosessi toistetaan, kunnes kaikki kohdat on ryhmitelty. Dendrogrammi on graafi, joka esittää hierarkkisia klustereita.
- Todennäköisyyslaskenta. Tiedot ryhmitellään käyttäen algoritmeja, jotka yhdistävät kohteita etäisyyksien tai tiheyksien avulla. Tämän suorittaa yleensä tietokone.
- Wardin menetelmä: käyttää jokaisessa vaiheessa minimivarianssia suhteellisen pienten, tasakokoisten klustereiden luomiseen.
K tarkoittaa ryhmittelyä
ryhmittelyä on vain tapa ryhmitellä tietojoukko pienempiin joukkoihin. Kaksi tapaa ryhmitellä joukko tietoja ovat kvantitatiivisesti (käyttäen numeroita) ja kvalitatiivisesti (käyttäen luokkia). Esimerkiksi kirjoja Amazon.com on lueteltu sekä kategorioittain (kvalitatiivinen) että best seller-kategorioittain (kvantitatiivinen). K-Means clustering on yksi yksinkertaisimmista valvomattomista oppimisalgoritmeista, joka ratkaisee klusterointiongelmat kvantitatiivisella menetelmällä: määrittelet ennalta joukon klustereita ja käytät yksinkertaista algoritmia tietojen lajitteluun. Se sanoi, “yksinkertainen” tietokonemaailmassa ei vastaa yksinkertaista tosielämässä. Tämä on itse asiassa NP-kova ongelma, joten sinun kannattaa käyttää ohjelmistoa K-means clustering. Jotkut ohjelmat, jotka suorittavat tämän Sinulle (klikkaa linkkiä menettelyn) ovat:
- SPSS.
- r
- MATLAB
k-means-ryhmittelyalgoritmin yleiset vaiheet ovat:
- päätä, kuinka monta klusteria (k).
- Aseta k keskipisteet eri paikkoihin (yleensä kaukana toisistaan).
- ota jokainen datapiste ja aseta se lähelle sopivaa keskipistettä. Toista, kunnes kaikki datapisteet on osoitettu.
- laske k uudet keskipisteet uudelleen barycentereiksi.
- toista datapisteiden osoittaminen, tällä kertaa uuteen keskuspisteeseen (barycenteriin).
- toistetaan 4 ja 5, kunnes keskipisteet (barykentät) eivät enää liiku.
K-tarkoittaa ryhmittelyä: muodollisempi määritelmä
muodollisempi tapa määritellä K-tarkoittaa ryhmittelyä on luokitella n-kohteet k(k>1) ennalta määriteltyihin ryhmiin. Tavoitteena on minimoida etäisyys kustakin datapisteestä klusteriin. Toisin sanoen löytää: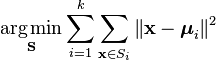
missä:
X on datapiste
k on klusterien lukumäärä
ui on si: n pisteiden keskiarvo.
klusterianalyysi vs. Diskriminanttianalyysi
klusterianalyysi on hyvin samankaltainen kuin diskriminanttianalyysi. Molempiin menetelmiin kuuluu erottautuminen ryhmiin. Klusterianalyysi on kuitenkin tapa tunnistaa ryhmät, kun taas diskriminanttianalyysi edellyttää ryhmien tuntemista ennen analyysin aloittamista. Sanotaan esimerkiksi, että teillä oli ryhmä psykiatrisia potilaita, joilla oli epänormaalia käyttäytymistä. Klusterianalyysi voisi auttaa löytämään erillisiä ryhmiä, kuten potilaat, joilla on ollut hyväksikäyttöä, ne, joilla on traumaperäinen stressihäiriö, tai ne, joilla on hallusinaatioita. Jos samaan ihmisryhmään tehtäisiin discriminant-analyysi, potilaan diagnoosit on tunnettava ennen kuin heitä aletaan sijoittaa ryhmiin.
klusterointi Excelissä
Microsoft Excelissä on tiedonlouhinta-lisäosa klustereiden tekemiseen. Ohjeet löydät täältä. Ohjattu toiminto toimii Excel-taulukoiden, vaihteluvälien tai Analyysikyselyiden kanssa. Tämä lisäosa voidaan räätälöidä, toisin kuin Detect Categories-työkalu. Lisäksi Detect Categories-työkalu rajoittuu taulukoiden tietoihin.
käyttöön:
- Lataa ja asenna tiedonlouhinta-lisäosa.
- valitse “tiedon louhinta”, valitse sitten” klusteri”, sitten ” Seuraava.”
- kerro Excelille, missä tietosi ovat. Valitse esimerkiksi joukko tietoja. Ryhmittelysivu tulee saataville.
- ryhmittely: jätä automaattiseen ryhmittelyyn sellaisenaan, tai voit määrittää useita ryhmiä.
- segmentit: jätetään sellaisenaan automaattista ryhmittelyä varten tai määritellään useita luokkia.
Stephanie Glen. “Clustering and K Means: Definition & Cluster Analysis in Excel” alkaen StatisticsHowTo.com: Alkeellisia tilastoja meille muille! https://www.statisticshowto.com/clustering/
——————————————————————————
Tarvitsetko apua kotitehtävissä tai koekysymyksessä? Chegg Studyn avulla saat askelmittaisia ratkaisuja kysymyksiisi alan asiantuntijalta. Ensimmäinen 30 minuuttia Chegg tutor on ilmainen!