klusterien aikataulujärjestelmän kehitys
Kubernetesista on tullut konttien orkestraation de facto standardi. Kaikki sovellukset kehitetään ja ajetaan Kubernetes tulevaisuudessa. Tämän artikkelisarjan tarkoituksena on esitellä kubernetesin taustalla olevat täytäntöönpanoperiaatteet syvällisellä ja yksinkertaisella tavalla.
Kubernetes on klusterien aikataulutusjärjestelmä. Tässä artikkelissa esitellään lähinnä joitakin aikaisempia klusterin aikataulutusjärjestelmän arkkitehtuuri Kubernetes. Analysoimalla heidän suunnitteluideoitaan ja arkkitehtuurin ominaisuuksia, voimme tutkia klusterin aikataulutusjärjestelmän arkkitehtuurin evoluutioprosessia ja suurinta ongelmaa, joka on otettava huomioon arkkitehtuurin suunnittelussa. Siitä on paljon apua kubernetesin arkkitehtuurin ymmärtämisessä.
meidän täytyy ymmärtää joitakin peruskäsitteitä klusterin aikataulutusjärjestelmä, jotta voidaan tehdä selväksi, selitän käsitteen kautta esimerkki, Oletetaan, että haluamme toteuttaa hajautettu Cron. Järjestelmä hallinnoi joukko Linux-isäntiä. Käyttäjä määrittelee työn järjestelmän tarjoaman API: n kautta. järjestelmä suorittaa säännöllisesti vastaavan tehtävän tehtävän määrittelyn perusteella, tässä esimerkissä peruskäsitteet ovat alla:
- klusteri: tämän järjestelmän hallinnoimat Linux-isännät muodostavat resurssipoolin tehtävien suorittamiseen. Tätä resurssipoolia kutsutaan klusteriksi.
- Job: se määrittelee, miten klusteri suorittaa tehtävänsä. Tässä esimerkissä Crontab on täsmälleen yksinkertainen työ, joka osoittaa selvästi, mitä on tehtävä(suoritus script) mihin aikaan (aikaväli).Joidenkin työtehtävien määrittely on monimutkaisempaa, kuten useissa tehtävissä suoritettavan työn määrittely ja tehtävien väliset riippuvuudet sekä kunkin tehtävän resurssivaatimukset.
- tehtävä: tehtävä on ajoitettava tiettyihin suoritustehtäviin. Jos määrittelemme tehtävän suorittaa komentosarja klo 1am joka ilta, niin komentosarjaprosessi suoritetaan klo 1am joka päivä on tehtävä.
klusterin aikataulujärjestelmää suunniteltaessa järjestelmän ydintehtäviä on kaksi:
- tehtävien aikataulutus: Kun työt on toimitettu klusterin aikataulujärjestelmään, toimitetut työt on jaettava tiettyihin suoritustehtäviin ja tehtävien suoritustuloksia on seurattava ja seurattava. Hajautetun Cronin esimerkissä aikataulujärjestelmän on käynnistettävä prosessi ajoissa toiminnan vaatimusten mukaisesti. Jos prosessi ei suorita, uudelleen on tarpeen jne. Joissakin monimutkaisissa skenaarioissa, kuten Hadoop Map Reduct, aikataulujärjestelmän on jaettava kartta Reduction-tehtävä vastaavaan moninkertaiseen karttaan ja vähennettävä tehtäviä, ja lopulta saatava tehtävän suorituksen tulosdata.
- resurssien aikataulutus: käytetään pääasiassa tehtävien ja resurssien yhteensovittamiseen, ja tehtävien suorittamiseen kohdennetaan asianmukaiset resurssit klusterin isäntien resurssien käytön mukaan. Se on samanlainen kuin käyttöjärjestelmän ajoitusalgoritmin prosessi, resurssien aikataulutuksen päätavoitteena on parantaa resurssien käyttöä mahdollisimman paljon ja vähentää tehtävien odotusaikaa resurssien kiinteän tarjonnan ehdoilla ja vähentää tehtävän tai vastausajan viivettä (jos se on erätehtävä, se viittaa tehtävän toiminnan alusta loppuun, jos se on online-vastaustyyppisiä tehtäviä, kuten Web-sovelluksia, joka viittaa kuhunkin pyyntöön vastausaikaan), tehtävän prioriteetti on otettava huomioon samalla kun se on yhtä oikeudenmukainen kuin mahdollinen (resurssit kohdennetaan oikeudenmukaisesti kaikkiin tehtäviin). Jotkin näistä tavoitteista ovat ristiriitaisia ja niitä on tasapainotettava, kuten resurssien käyttö, vasteaika, oikeudenmukaisuus ja prioriteetit.
Hadoop MRv1
Map Reduce on eräänlainen rinnakkaislaskennan malli. Hadoop voi suorittaa tällaista klusterin hallinta alustan rinnakkaista tietojenkäsittelyä. MRv1 on Hadoop-Alustan map Reduct task scheduling Enginen ensimmäisen sukupolven versio. Lyhyesti sanottuna, MRv1 on vastuussa aikataulutus ja suoritus työtä klusterin, ja palata laskennan tulokset, Kun käyttäjä määrittelee kartan vähentää laskenta ja toimittaa sen Hadoop. Tältä näyttää mrv1: n arkkitehtuuri:
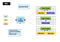
arkkitehtuuri on suhteellisen yksinkertaista, Standardimestari / Orja-arkkitehtuurissa on kaksi ydinosaa:
- Job Tracker on Clusterin päähallintakomponentti, joka vastaa sekä resurssien aikataulutuksesta että tehtävien aikataulutuksesta.
- tehtäväseuranta toimii jokaisella klusterin koneella, joka vastaa tiettyjen tehtävien suorittamisesta isäntä-ja raportointitilassa.
Hadoopin suosion ja erilaisten vaatimusten kasvun myötä MRv1: llä on seuraavat parannettavat ongelmat:
- esityksessä on tietty pullonkaula: johtamista tukevia solmuja on enintään 5 000 ja tukioperaation tehtäviä enintään 40 000. Parantamisen varaa on vielä.
- se ei ole tarpeeksi joustava laajentaakseen tai tukeakseen muita tehtävätyyppejä. Hadoop-ekosysteemissä on Map reduce-tyyppisten tehtävien lisäksi monia muita ajoitettavia tehtävätyyppejä, kuten Spark, Hive, HBase, Storm, Oozie jne. Siksi tarvitaan yleisempi aikataulujärjestelmä, joka voi tukea ja laajentaa useampia tehtävätyyppejä
- resurssien vähäistä käyttöä: MRv1 määrittää staattisesti tietyn määrän paikkoja kullekin solmulle, ja jokaista paikkaa voidaan käyttää vain tiettyyn tehtävätyyppiin (kartta tai vähennä), mikä johtaa resurssien hyödyntämisen ongelmaan. Esimerkiksi suuri osa Karttatehtävistä jonottaa joutokäyntiresursseja, mutta itse asiassa suuri osa Vähennyspaikoista on joutokäyntejä koneille.
- Moniasunto-ja moniversioasiat. Esimerkiksi eri osastot hoitavat tehtäviä samassa rykelmässä, mutta ne ovat loogisesti erillään toisistaan, tai ne pyörittävät Hadoopin eri versioita samassa rykelmässä.
Lanka
Lanka(vielä toinen Resurssineuvottelija) on toisen sukupolven Hadoop ,jonka päätarkoitus on ratkaista kaikenlaisia MRv1: n ongelmia. Lanka-arkkitehtuuri näyttää tältä:

yksinkertainen käsitys langasta on, että tärkein parannus MRv1: een verrattuna on jakaa alkuperäisen Jobtrackin vastuut kahteen eri komponenttiin: Resource Manager ja Application Master
- Resource Manager: Se vastaa resurssien aikatauluttamisesta, hallinnoi kaikkia resursseja, jakaa resursseja erityyppisiin tehtäviin ja laajentaa resurssien aikataulutusalgoritmia helposti liitettävän arkkitehtuurin avulla.
- Application Master: se vastaa tehtävien aikatauluttamisesta. Jokainen työ (jota kutsutaan langaksi sovellukseksi) aloittaa vastaavan Sovellusmestarin, joka vastaa työn jakamisesta tiettyihin tehtäviin ja resurssien hakemisesta Resurssienhallinnasta, tehtävän aloittamisesta, tehtävän tilan seurannasta ja tulosten raportoinnista.
Katsotaanpa, miten tämä arkkitehtuurimuutos ratkaisi MRv1: n erilaiset ongelmat:
- Jaa Job Trackerin alkuperäinen tehtävien aikataulutusvastuu, mikä johtaa merkittäviin suorituskykyparannuksiin. Alkuperäisen Job Trackerin tehtävien aikataulutusvastuut jaettiin Application Masterin tehtäväksi ja Application Master jaettiin, jokainen instanssi käsitteli vain yhden työn pyynnön, jolloin se edisti klusterisolmujen enimmäismäärää 5 000: sta 10 000: een.
- tehtävien aikataulutuksen, Sovellusmestarin ja resurssien aikataulutuksen osat on irrotettu tuotannosta ja luotu dynaamisesti työpyyntöjen perusteella. Yksi Sovellusmestari-instanssi vastaa vain yhdestä aikataulutyöstä, mikä helpottaa erityyppisten töiden tukemista.
- konttien eristystekniikka otetaan käyttöön, jokainen tehtävä suoritetaan eristetyssä kontissa, mikä parantaa huomattavasti resurssien käyttöä tehtävän dynaamisesti jaettavien resurssien tarpeen mukaan. Tämän varjopuolena on LANKAVARANTOJEN hallinta ja allokoinnilla on vain yksi muistin ulottuvuus.
Mesos-arkkitehtuuri
langan suunnittelutavoitteena on edelleen palvella Hadoop-ekosysteemin aikataulutusta. Mesoksen tavoite lähenee, se on suunniteltu yleiseksi aikataulujärjestelmäksi, joka voi hallita koko datakeskuksen toimintaa. Kuten näemme, arkkitehtoninen suunnittelu Mesos käytetty paljon Lanka viittaus, työn aikataulutus ja resurssien aikataulutus vastaa eri moduulit erikseen. Mutta suurin ero Mesojen ja langan välillä on tapa ajoittaa resursseja, suunnitellaan ainutlaatuinen mekanismi nimeltä Resurssitarjous. Resurssien aikataulutuksen paine purkautuu entisestään, ja myös työn aikataulutuksen skaalautuvuus kasvaa.

Mesojen pääkomponentit ovat:
- Mesos Master: se on komponentti, joka on yksin vastuussa resurssien kohdentamisesta ja hallinnan komponenteista, joka on sisempää lankaa vastaava Resurssienhallinta. Mutta toimintatapa on hieman erilainen, jos keskustellaan myöhemmin.
- Framework: vastaa työn aikatauluttamisesta, eri työtyypeillä on vastaava kehys, kuten Spark Framework, joka vastaa Kipinätöistä.
Mesojen Resurssitarjous
saattaa vaikuttaa siltä, että Mesojen ja lankojen arkkitehtuurit ovat melko samanlaisia, mutta itse asiassa Resurssinhallinnan kannalta Mesojen mestarilla on hyvin ainutlaatuinen (ja hieman omituinen) Resurssitarjousmekanismi:
- Lanka vetää: Resource managerin langassa tarjoamat resurssit ovat passiivisia, kun resurssin (Application Master) kuluttajat tarvitsevat resursseja, se voi kutsua Resource managerin rajapintaa resurssien saamiseksi, ja Resource Manager vastaa vain passiivisesti Application Masterin tarpeisiin.
- Mesos on Push: Master of Mesosin tarjoamat resurssit ovat ennakoivia. Master of Mesos tekee säännöllisesti aloitteen kaikkien nykyisten käytettävissä olevien resurssien (ns.Resurssitarjoukset, kutsun sitä tarjoukseksi tästä eteenpäin) työntämiseksi kehykseen. Jos kehyksessä on tehtäviä hoidettavana, se ei voi aktiivisesti hakea resursseja, ellei tarjouksia saada. Framework valitsee tarjouksesta hyväksytyn resurssin (tätä liikettä kutsutaan Mesoissa hyväksytyksi,) ja hylkää jäljellä olevat tarjoukset (tätä liikettä kutsutaan hylätyksi). Jos tällä tarjouskierroksella ei ole riittävästi päteviä resursseja, joudumme odottamaan seuraavan Master-kierroksen tarjousta.
uskon, että kun näette tämän aktiivisen Tarjousmekanismin, teillä on sama tunne kanssani. Eli tehokkuus on suhteellisen alhainen, ja seuraavat ongelmat syntyvät:
- minkä tahansa kehyksen päätöksentekotehokkuus vaikuttaa kokonaistehokkuuteen. Johdonmukaisuuden vuoksi Master voi tarjota tarjouksen vain yhdelle kehykselle kerrallaan ja odottaa, että kehys valitsee tarjouksen ennen kuin tarjoaa loput seuraavaan kehykseen. Näin minkä tahansa kehyksen päätöksenteon tehokkuus vaikuttaa kokonaistehokkuuteen.
- “tuhlaa” paljon aikaa kehyksiin, jotka eivät vaadi resursseja. Mesos ei oikein tiedä, mitkä puitteet tarvitsevat resursseja. Joten siellä on Framework resurssivaatimukset on jonottaa tarjous, mutta puitteet ilman resursseja vaatimukset saa tarjouksen usein.
vastauksena edellä mainittuihin kysymyksiin Mesos on esittänyt joitakin mekanismeja ongelmien lieventämiseksi, kuten asettanut aikalisän puitteiden päätöksenteolle tai antanut kehyksen hylätä tarjoukset asettamalla sen Tukahduttamistilaksi. Koska se ei ole tämän keskustelun keskipiste, yksityiskohdat jätetään tässä huomiotta.
itse asiassa Mesoilla on joitakin ilmeisiä etuja, jotka käyttävät tätä aktiivisen tarjoamisen mekanismia:
- suorituskyky on ilmeisesti parantunut. Klusteri voi simulaatiotestauksen mukaan tukea jopa 100 000 solmua, Twitterin tuotantoympäristössä suurin klusteri voi tukea 80 000 solmua. tärkein syy on se, että mesos Master-mekanismin aktiivinen tarjoaminen yksinkertaistaa Mesojen velvollisuuksia entisestään. prosessi resurssien aikataulutus, resurssien tehtävän matching, Mesos on jaettu kahteen vaiheeseen: resursseja tarjota, ja tarjota tehtävä. Mesos-mestari on vastuussa vain ensimmäisen vaiheen suorittamisesta, ja toisen vaiheen sovittaminen jää kehyksen tehtäväksi.
- joustavampi ja kykenevämpi vastaamaan vastuullisempiin tehtävien aikataulutusperiaatteisiin. Esimerkiksi resurssien käyttöstrategia kaikki tai ei mitään.
Mesos DRF: n Ajoitusalgoritmi (Dominant Resource Fairness)
DRF-algoritmin osalta sillä ei itse asiassa ole mitään tekemistä ymmärryksemme kanssa Mesos-arkkitehtuurista, mutta se on mesos-arkkitehtuurissa hyvin keskeinen ja tärkeä, joten selitän tässä hieman enemmän.
kuten edellä mainittiin, Mesos tarjoaa kehykselle vuorollaan tarjouksen, joten mikä kehys tulisi valita tarjoamaan joka kerta? Tämä on DRF-algoritmilla ratkaistava ydinongelma. Perusperiaatteena on ottaa huomioon sekä oikeudenmukaisuus että tehokkuus. Samalla kun se täyttää kaikki kehyksen resurssitarpeet, pitäisi olla mahdollisimman oikeudenmukaista välttää se, että yksi kehys kuluttaa liikaa resursseja ja näännyttää muut puitteet hengiltä.
DRF on muunnos min-Maxin oikeudenmukaisuusalgoritmista. Yksinkertaisesti sanottuna, se on valita puitteet pienin hallitseva resurssien käyttöä tarjota tarjouksen joka kerta. Miten lasketaan viitekehyksen vallitseva resurssien käyttö? Kaikista viitekehyksen käyttämistä resurssityypeistä valitaan vallitsevaksi resurssiksi resurssityyppi, jonka käyttöaste on alhaisin. Sen resurssien käyttöaste on juuri vallitseva resurssien Käyttökehyksen. Esimerkiksi Framework-suoritin vie 20% Kokonaisresurssista, 30% muistista ja 10% levykkeestä. Niinpä kehyksen dominoiva resurssien käyttö on 10%, virallinen termi kutsuu levyä dominoivaksi resurssiksi, ja Tätä 10%: a kutsutaan dominoivaksi resurssien käytöksi.
DRF: n perimmäinen tavoite on jakaa resurssit tasapuolisesti kaikkien kehysten kesken. Jos Framework X hyväksyy liian monta resurssia tällä tarjouskierroksella, sen jälkeen kestää paljon kauemmin saada mahdollisuus seuraavalle Tarjouskierrokselle. Kuitenkin huolellinen lukijat huomaavat, että tässä algoritmissa on oletus, eli kun kehys hyväksyy resurssit, se vapauttaa ne nopeasti, muuten on kaksi seurausta:
- muut puitteet nääntyvät nälkään. Yksi Framework a hyväksyy suurimman osan klusterin resursseista kerralla, ja tehtävä jatkuu lopettamatta, niin että suurin osa resursseista on koko ajan Framework A: n käytössä, eivätkä muut frameworkitkaan enää saa resursseja.
- näännytä itsesi nälkään. Koska määräävä resurssien käyttö näissä puitteissa on aina erittäin korkea, joten ei ole mahdollisuutta saada tarjousta pitkään aikaan, joten enemmän tehtäviä ei voi suorittaa.
joten Mesot sopivat vain lyhyiden tehtävien aikatauluttamiseen, ja Mesot suunniteltiin alun perin datakeskusten lyhyisiin tehtäviin.
tiivistelmä
suuresta arkkitehtuurista kaikki aikataulujärjestelmän arkkitehtuuri on Master/Slave-arkkitehtuuria, Slave end on asennettu jokaiseen koneeseen vaatimuksena hallinta, jota käytetään isäntätiedon keräämiseen ja tehtävien suorittamiseen isännällä. Päällikkö vastaa pääasiassa resurssien aikataulutuksesta ja tehtävien aikataulutuksesta. Resurssien ajoituksella on korkeammat vaatimukset suorituskyvylle ja tehtävien aikataulutuksella on korkeammat vaatimukset skaalautuvuudelle. Yleinen suuntaus on keskustella kahdenlaisista tulleista ja täydentää niitä eri osatekijöillä.
