kovera runko
klusterirajan luominen K-lähimmät naapurit-lähestymistavalla
a couple of months ago, I writed here on Medium an article on mapping the UK ‘ s traffic accidents hot spots. Olin lähinnä huolissani dbscan-ryhmittelyalgoritmin käytön havainnollistamisesta maantieteellisissä tiedoissa. Käytin kirjoituksessa Yhdistyneen kuningaskunnan hallituksen julkaisemia paikkatietoja ilmoitetuista liikenneonnettomuuksista. Tarkoitukseni oli ajaa tiheysperusteista ryhmittelyä löytääkseni alueet, joilla liikenneonnettomuuksia raportoidaan useimmin. Lopputuloksena syntyi geo-aidat, jotka edustivat näitä onnettomuuspesäkkeitä.
keräämällä kaikki tietyn klusterin pisteet voit saada käsityksen siitä, miltä klusteri näyttäisi kartalla, mutta sinulta puuttuu tärkeä tieto: klusterin ulkomuoto. Tällöin puhutaan suljetusta monikulmiosta, joka voidaan esittää kartalla geoaitana. Minkä tahansa pisteen geoaidan sisällä voidaan olettaa kuuluvan klusteriin, mikä tekee tästä muodosta mielenkiintoisen tiedon: voit käyttää sitä erottelutoimintona. Kaikkien äskettäin otettujen pisteiden, jotka kuuluvat monikulmion sisään, voidaan olettaa kuuluvan vastaavaan klusteriin. Kuten olen vihjannut artikkelissa, voit käyttää tällaisia polygons puolustaa ajo riski, käyttämällä niitä luokitella Oman näytteenotto GPS sijainti.
kysymys on nyt siitä, miten luodaan mielekäs monikulmio tietyn klusterin muodostavien pisteiden pilvestä. Lähestymistapani ensimmäisessä artikkelissa oli jokseenkin naiivi ja heijasteli ratkaisua, jota olin jo käyttänyt tuotantokoodissa. Tämä ratkaisu merkitsi asettamalla ympyrän keskipisteenä kunkin klusterin pistettä ja sitten yhdistämällä kaikki ympyrät yhteen muodostaen pilvenmuotoisen monikulmion. Tulos ei ole kovin mukava eikä realistinen. Myös käyttämällä ympyröitä perusmuotona lopullisen monikulmion rakentamisessa, näillä on enemmän pisteitä kuin virtaviivaisemmalla muodolla, mikä lisää tallennuskustannuksia ja tekee inkluusiota tunnistavista algoritmeista hitaampia toimimaan.

toisaalta tämän lähestymistavan etuna on laskennallisesti yksinkertainen (ainakin kehittäjän näkökulmasta), sillä se käyttää Shapelyn cascaded_union funktiota sulauttamaan kaikki ympyrät yhteen. Toinen etu on se, että monikulmion muoto määritellään implisiittisesti käyttäen kaikkia klusterin pisteitä.
kehittyneempiä lähestymistapoja varten meidän on jotenkin tunnistettava klusterin rajapisteet, ne, jotka näyttävät määrittelevän pistepilven muodon. Mielenkiintoista, joidenkin DBSCAN toteutuksia voit itse palauttaa raja pistettä sivutuotteena klusteroinnin prosessi. Valitettavasti tämä tieto ei (ilmeisesti) ole saatavilla SciKit Learnin toteutuksesta, joten meidän on tehtävä se.
ensimmäinen mieleen noussut lähestymistapa oli laskea pisteiden joukon Kupera runko. Tämä on hyvin ymmärretty algoritmi, mutta kärsii ongelmasta ei käsitellä kovera muotoja, kuten tämä:

tämä muoto ei kuvaa oikein pohjapisteiden olemusta. Jos sitä käytettäisiin erottimena, jotkin kohdat luokiteltaisiin virheellisesti klusterin sisäisiksi, kun ne eivät ole. Tarvitsemme toisen lähestymistavan.
kovera Runkovaihtoehto
onneksi tälle asiaintilalle on vaihtoehtoja: voimme laskea koveran rungon. Tältä kovera runko näyttää, kun sitä levitetään samoille pisteille kuin edellisessä kuvassa:

tai ehkä tämä:
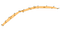
kuten näkyy, ja toisin kuin kupera runko, ei ole olemassa yhtä määritelmää siitä, mikä on kovera runko pistejoukossa. Esittelemäni algoritmin avulla valinta siitä, kuinka koveraksi haluat runkosi, tehdään yhden parametrin avulla: k — lähimpien naapureiden lukumäärä, joka otetaan huomioon runkolaskennassa. Katsotaan, miten tämä toimii.
algoritmin
tässä esittelemäni algoritmin kuvailivat yli vuosikymmen sitten Adriano Moreira ja Maribel Yasmina Santos portugalilaisesta Minhon yliopistosta . Abstraktista:
tässä asiakirjassa kuvataan algoritmi laskea kirjekuori joukko kohtia lentokoneessa,joka tuottaa kupera, ei-Kupera rungot, jotka edustavat alueen käytössä annettujen pisteiden. Ehdotettu algoritmi perustuu k-lähimmät naapurit-lähestymistapaan, jossa K: n, ainoan algoritmin parametrin, arvoa käytetään ohjaamaan lopullisen ratkaisun “tasaisuutta”.
koska aion soveltaa tätä algoritmia maantieteelliseen tietoon, jouduttiin tekemään joitakin muutoksia, nimittäin laskettaessa kulmia ja etäisyyksiä . Mutta nämä eivät muuta millään tavalla algoritmin ydinajatusta, jota voidaan karkeasti kuvata seuraavilla askelilla:
- Etsi kohta alin y (leveysaste)koordinoida ja tehdä siitä nykyinen.
- Etsi nykyistä pistettä lähimmät k-pisteet.
- K: n lähimmistä pisteistä valitaan se, joka vastaa suurinta oikeanpuoleista käännöstä edellisestä kulmasta. Täällä käytämme käsitettä laakeri ja alkaa kulma 270 astetta (suoraan länteen).
- Tarkista, ettei uusi piste kasvavaan viivajonoon leikkaa itseään. Jos näin käy, valitse k-lähimmästä pisteestä toinen piste tai käynnistä se uudelleen suuremmalla arvolla k.
- tee uudesta pisteestä nykyinen piste ja poista se luettelosta.
- k-iterointien jälkeen lisätään ensimmäinen piste takaisin listaan.
- Silmukka sijalle 2.
algoritmi vaikuttaa melko yksinkertaiselta, mutta on olemassa useita yksityiskohtia, jotka on hoidettava, varsinkin koska kyse on maantieteellisistä koordinaateista. Etäisyydet ja kulmat mitataan eri tavalla.
koodi
Täällä minä julkaisen on mukautettu versio edellisen artikkelin koodista. Löydät edelleen saman klusterointikoodin ja saman pilvenmuotoisen klusterigeneraattorin. Päivitetty versio sisältää nyt geomath.hulls – nimisen paketin, josta löytyy ConcaveHull – Luokka. Voit luoda kovera rungot tehdä seuraavasti:
yllä olevassa koodissa points on mittojen joukko (N, 2), jossa rivit sisältävät havaitut pisteet ja sarakkeet Maantieteelliset koordinaatit (pituus, leveys). Tuloksena olevalla jonolla on täsmälleen sama rakenne, mutta se sisältää vain ne pisteet, jotka kuuluvat klusterin monikulmioon. Eräänlainen suodatin.
koska käsittelemme arrayta, on vain luonnollista tuoda NumPy mukaan taisteluun. Kaikki laskelmat oli asianmukaisesti vectorisoitu, aina kun mahdollista, ja pyrittiin parantamaan suorituskykyä lisättäessä ja poistettaessa kohteita taulukoista (spoileri: niitä ei siirretä lainkaan). Yksi puuttuvista parannuksista on koodin parallelization. Mutta se voi odottaa.
järjestin koodin algoritmin ympärille siten, että se paljastuu lehdessä, vaikka joitakin optimointeja tehtiin käännöksen aikana. Algoritmi rakentuu useiden aliohjelmien ympärille, jotka paperi selvästi tunnistaa, joten hoidetaan ne pois alta nyt heti. Lukemisen helpottamiseksi käytän samoja nimiä kuin lehdessä.
CleanList —pistelistan puhdistus suoritetaan luokassa rakentaja:
kuten näette, lista pistettä on toteutettu numpy array suorituskyvyn syistä. Listan puhdistus suoritetaan linjalla 10, jossa säilytetään vain uniikkeja pisteitä. Data set array on järjestetty havainnot riveihin ja maantieteelliset koordinaatit kaksi saraketta. Huomaa, että olen myös luomassa boolean array linjalla 13, jota käytetään indeksoida tärkeimmät tiedot set array, helpottaa urakka poistaa kohteita ja, silloin tällöin, lisäämällä ne takaisin. Olen nähnyt numpy-dokumentissa tämän “naamioksi” kutsutun tekniikan, ja se on erittäin tehokas. Mitä alkulukuihin tulee, keskustelen niistä myöhemmin.
FindMinYPoint-tämä vaatii pienen funktion:
tätä funktiota kutsutaan datajoukon argumenttina ja se palauttaa pisteen indeksin alimmalla leveysasteella. Huomaa, että rivit on koodattu pituusaste ensimmäisessä sarakkeessa ja leveysaste toisessa.
RemovePoint
AddPoint – nämä ovat ei-aivoisia, johtuen indices – ryhmän käytöstä. Tätä taulukkoa käytetään aktiivisten indeksien tallentamiseen päätietokantaan, joten kohteiden poistaminen tietojoukosta on helppoa.
vaikka lehdessä kuvattu algoritmi vaatii pisteen lisäämistä rungon muodostavaan joukkoon, tämä toteutetaan itse asiassa:
myöhemmin test_hull muuttuja annetaan takaisin hull, kun viivajono katsotaan leikkaamattomaksi. Mutta menen asioiden edelle. Pisteen poistaminen datajoukosta on niin yksinkertaista kuin:
self.indices = False
lisäämällä se takaisin on vain kysymys käännetään, että array arvo samalla indeksillä takaisin true. Mutta kaikki tämä mukavuus tulee Hinta täytyy pitää silmällä indeksit. Lisää tästä myöhemmin.
NearestPoints-asiat alkavat käydä kiinnostaviksi täällä, koska emme ole tekemisissä planaaristen koordinaattien kanssa, joten ulos Pythagoraan kanssa ja sisään Haversinen kanssa:
huomaa, että toinen ja kolmas parametri ovat taulukoita dataset-muodossa: pituusaste ensimmäisessä sarakkeessa ja leveysaste toisessa sarakkeessa. Kuten näette, tämä funktio palauttaa joukon etäisyyksiä metreinä toisen argumentin pisteen ja kolmannen argumentin pisteiden välillä. Kun meillä on nämä, saamme k-lähimmät naapurit helpolla tavalla. Mutta on olemassa erityinen tehtävä, että ja se ansaitsee joitakin selityksiä:
funktio alkaa luomalla joukon, jossa on perusindeksit. Nämä ovat niiden pisteiden indeksejä, joita ei ole poistettu tietojoukosta. Esimerkiksi, jos kymmenen pisteen klusterin aloitimme poistamalla ensimmäinen piste, base indeksit array olisi . Seuraavaksi laskemme etäisyydet ja lajittelemme tuloksena olevat array-indeksit. Ensimmäinen k uutetaan ja sitten käytetään naamio hakea perusindeksit. Se on vääristelty, mutta toimii. Kuten näette, funktio ei palauta joukko koordinaatteja, mutta joukko indeksejä osaksi data set array.
SortByAngle — täällä on enemmän ongelmia, koska emme laske yksinkertaisia kulmia, vaan laakereita. Nämä mitataan nolla astetta pohjoiseen, kulmien kasvaessa myötäpäivään. Tässä on koodin ydin, joka laskee Laakerit.:
funktio palauttaa joukon laakereita, jotka on mitattu pisteestä, jonka indeksi on ensimmäisessä argumentissa, pisteisiin, joiden indeksit ovat kolmannessa argumentissa. Lajittelu on yksinkertaista:
tässä vaiheessa ehdokkaiden joukko sisältää K-lähimpien pisteiden indeksit, jotka on lajiteltu laskevan laakerijärjestyksen mukaan.
IntersectQ-sen sijaan, että olisin pyörittänyt omia ratojen risteysfunktioitani, Käännyin Shapelyn puoleen pyytääkseni apua. Itse asiassa, kun rakennamme monikulmio, olemme pääasiassa käsittely line merkkijono, liittämällä segmenttejä, jotka eivät leikkaa edellisen niistä. Tämän testaaminen on yksinkertaista: poimimme rakenteilla olevan runkorakenteen, muutamme sen Muodokkaaksi rivijonoesineeksi ja testaamme, onko se yksinkertainen (ei itse leikkaava) vai ei.
pähkinänkuoressa muodollinen viivajono muuttuu monimutkaiseksi, jos se risteytyy itsestään, joten is_simple predikaatista tulee epätosi. Helppo.
PointInPolygon-tämä osoittautui hankalimmaksi toteuttaa. Sallikaa minun selittää tarkastelemalla koodia, joka suorittaa lopullisen rungon monikulmion validoinnin (tarkistaa, jos kaikki klusterin pisteet sisältyvät monikulmioon):
shapelyn funktioiden leikkauspisteiden ja inkluusioiden testaamiseksi olisi pitänyt riittää tarkistamaan, onko lopullinen rungon monikulmio päällekkäinen kaikkien klusterin pisteiden kanssa, mutta näin ei ollut. Miksi? Shapely on koordinaatti-agnostikko, joten se käsittelee leveysasteina ja pituusasteina ilmaistuja maantieteellisiä koordinaatteja täsmälleen samalla tavalla kuin karteesisen tason koordinaatteja. Mutta maailma käyttäytyy eri tavalla, kun elät pallolla, eivätkä kulmat (tai Laakerit) ole vakio geodeettisesti. Esimerkki Bagdadin ja Osakan yhdistävästä geodeettisesta linjasta valaisee tätä täydellisesti. On niin, että joissakin olosuhteissa algoritmi voi sisältää pisteen, joka perustuu laakerin kriteeri, mutta myöhemmin, käyttäen Shapely ‘ s planar algoritmeja, katsotaan koskaan niin vähän ulkopuolella monikulmio. Sitä pieni etäisyyskorjaus siellä tekee.
tämän selvittämiseen meni aikaa. Minun virheenkorjaus apua oli QGIS, suuri pala vapaata ohjelmistoa. Jokaisessa vaiheessa epäilyttäviä laskelmia haluaisin tulostaa tiedot WKT-muodossa CSV-tiedostoon, joka luetaan kerroksena. Todellinen hengenpelastaja!
lopuksi, jos monikulmio ei kata kaikkia klusterin pisteitä, ainoa vaihtoehto on lisätä k ja yrittää uudelleen. Tässä lisäsin hieman omaa intuitiotani.
alkuluku k
artikkelissa ehdotetaan, että K: n arvoa nostetaan yhdellä ja algoritmi suoritetaan uudelleen tyhjästä. Varhaiset testini tällä vaihtoehdolla eivät olleet kovin tyydyttäviä: ajoajat olisivat hitaita ongelmallisilla klustereilla. Tämä johtui K: n hitaasta kasvusta, joten päätin käyttää toista korotusaikataulua: alkulukujen taulukkoa. Algoritmi alkaa jo K=3: sta, joten se oli helppo laajennus saada kehittymään alkulukujen listalla. Näin näet tapahtuvan rekursiivisessa kutsussa:
minulla on juttu alkuluvuille, tiedättehän …
räjäyttää
tämän algoritmin synnyttämät koverat runkokulmat tarvitsevat vielä hieman jatkojalostusta, koska ne erottelevat vain rungon sisällä olevia, mutta eivät sen lähellä olevia pisteitä. Ratkaisu on lisätä hieman pehmustetta näihin laihoihin rykelmiin. Tässä käytän täsmälleen samaa tekniikkaa kuin ennenkin, ja tässä on, miltä se näyttää:

tässä käytin Shapelyn bufferfunktiota temppuun.
funktio hyväksyy muodollisen monikulmion ja palauttaa paisutetun version itsestään. Toinen parametri on lisätyn pehmusteen säde metreinä.
koodin ajaminen
aloita vetämällä koodi GitHub-arkistosta paikalliseen koneeseesi. Suoritettava tiedosto on ShowHotSpots.py pääkansiossa. Kun ensimmäinen suoritus, koodi lukee Yhdistyneen kuningaskunnan liikenneonnettomuuksien tiedot 2013-2016 ja klusterin se. Tulokset tallennetaan välimuistiin CSV-tiedostona seuraavia suorituksia varten.
tämän jälkeen sinulle esitetään kaksi karttaa: ensimmäinen luodaan pilvenmuotoisilla klustereilla, kun taas toinen käyttää tässä käsiteltyä koveraa klusterointialgoritmia. Vaikka polygon generation code suorittaa, saatat nähdä, että muutamia vikoja on raportoitu. Jotta ymmärtäisimme, miksi algoritmi ei luo koveraa runkoa, koodi kirjoittaa klusterit CSV-tiedostoiksi data/out/failed/ – hakemistoon. Kuten tavallista, Voit käyttää QGIS tuoda nämä tiedostot tasoina.
oleellisesti tämä algoritmi epäonnistuu, kun se ei löydä tarpeeksi pisteitä “kiertää” muotoa ilman, että se leikkaa itsensä. Tämä tarkoittaa, että sinun on oltava valmis joko hylkäämään nämä klusterit tai soveltamaan niille erilaista käsittelyä (Kupera runko tai yhteenkasvaneet kuplat).
koveruus
se on kääre. Tässä artikkelissa esitin menetelmä jälkikäsittely DBSCAN syntyy maantieteellisiä klustereita kovera muotoja. Tämä menetelmä voi tarjota klustereille paremmin sopivan monikulmion ulkopuolen verrattuna muihin vaihtoehtoihin.
Kiitos lukemisesta ja nauti koodin puuhastelusta!
Kryszkiewicz M., Lasek P. (2010) TI-DBSCAN: Clustering with Dbscan by Means of the Triangle epäyhtälö. In: Szczuka M., Kryszkiewicz M., Ramanna S., Jensen R., hu Q. (eds) Rough Sets and Current Trends in Computing. RSCTC 2010. Luento Notes in Computer Science, vol 6086. Springer, Berlin, Heidelberg
Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, s. 2825-2830, 2011
Moreira, A. and Santos, M. Y., 2007, Concave Hull: A K-nearest neighbors approach for the computation of the region asked by a set of points
Calculate distance, bearing and more between later/Longitude points
Github repository