yhteinen haku: avoimen lähdekoodin projekti tuo PageRankin takaisin
Rekisteröidy päivittäisiin kertauksiin alati muuttuvasta hakumarkkinointimaisemasta.
huomaa: lähettämällä tämän lomakkeen hyväksyt Third Door Median ehdot. Kunnioitamme yksityisyyttäsi.

useiden viime vuosien aikana Google on hitaasti vähentänyt hakukoneoptimoinnin harjoittajien käytettävissä olevan datan määrää. Ensin se oli avainsanatiedot, sitten PageRank pisteet. Nyt se on erityinen haku tilavuus AdWords (ellet viettää joitakin moola). Tästä voit lukea lisää Russ Jonesin erinomaisesta artikkelista, jossa kerrotaan hänen yrityksensä tutkimuksen ja oivallusten vaikutuksista clickstream-tietoihin volume disambiguationia varten.
yksi asia, johon olemme viime aikoina päässeet todella mukaan, on yleinen Ryömintädata. Alallamme on useita tiimejä, jotka ovat käyttäneet tätä dataa jo jonkin aikaa, joten tunsin hieman myöhästyneeni pelistä. Common Crawl data on avoimen lähdekoodin projekti, joka raaputtaa koko internetin säännöllisin väliajoin. Onneksi Amazon, koska suuri yritys se on, pystytti tallentaa tiedot, jotta se on monien saatavilla ilman korkeat tallennuskustannukset.
tavallisten Ryömintätietojen lisäksi on olemassa yleishyödyllinen yhteishaku, jonka tehtävänä on luoda vaihtoehtoinen avoimen lähdekoodin ja läpinäkyvän hakukoneen — monessa suhteessa Googlen vastakohta. Tämä herätti kiinnostukseni, koska se tarkoittaa, että me kaikki voimme pelata, nipistää ja mankeli signaaleja oppia, miten hakukoneet toimivat ilman valtava aika investointeja alkaen ground zero.
yhteiset hakutiedot
tällä hetkellä yhteishaku käyttää seuraavia tietolähteitä hakujärjestyksensä laskemiseen (tämä on otettu suoraan heidän verkkosivuiltaan):
- Common Crawl: suurin web crawl-tietojen avoin arkisto. Tämä on tällä hetkellä ainutlaatuinen lähde raw sivu tietoja.
- Wikidata: Ilmainen, linkitetty tietokanta, joka toimii keskeisenä tallennuksena monien Wikimediaprojektien, kuten Wikipedian, Wikivoyagen ja Wikisourcen, jäsennellyille tiedoille.
- UT1 Musta lista: Fabrice Prigentin ylläpitämä Université Toulouse 1 Capitole, tämä musta lista luokittelee verkkotunnukset ja URL-osoitteet useisiin luokkiin, mukaan lukien “AIKUINEN” ja “tietojenkalastelu.”
- DMOZ: tunnetaan myös nimellä Open Directory Project, se on vanhin ja suurin yhä elossa oleva web-hakemisto. Vaikka sen tiedot eivät ole yhtä luotettavia kuin aiemmin, käytämme niitä edelleen signaali-ja metatiedon lähteenä.
- Web Data Commons Hyperlink Graphs: graafit kaikista hyperlinkeistä vuoden 2012 yhteisestä Indeksiarkistosta. Käytämme tällä hetkellä sen harmoninen Keskeisyystiedosto väliaikaisena sijoitussignaali verkkotunnuksia. Suunnittelemme tekevämme Oman analyysimme web-graafista lähitulevaisuudessa.
- Alexa top 1m sites: Alexa rankkaa sivustot, jotka perustuvat yhteenlaskettuun sivunäkymien ja ainutlaatuisten sivuston käyttäjien mittaukseen. Sen tiedetään olevan demografisesti puolueellinen. Käytämme sitä väliaikaisena sijoitussignaalina verkkotunnuksissa.
yhteinen hakujärjestys
näiden tietolähteiden lisäksi koodia tutkiessaan se käyttää algoritmissaan myös URL-osoitteen pituutta, polun pituutta ja verkkotunnuksen PageRankia ranking-signaaleina. Kas kummaa, heinäkuusta lähtien Yhteishaulla on ollut oma datansa isäntätason Pagerankissa, ja me kaikki kaipasimme sitä.
pääsen hetken päästä Pagerankiin (PR), mutta on mielenkiintoista kerrata tavallisen ryöminnän, erityisesti rankkarin, koodia.py osa sijaitsee täällä, koska voit todella päästä kuljettajan istuin säätämällä painot signaaleja, että se käyttää listalla sivuja:
signal_weights = {"url_total_length": 0.01,"url_path_length": 0.01,"url_subdomain": 0.1,"alexa_top1m": 5,"wikidata_url": 3,"dmoz_domain": 1,"dmoz_url": 1,"webdatacommons_hc": 1,"commonsearch_host_pagerank": 1}
erityisen merkille pantavaa on myös se, että Common Search käyttää BM25: tä samankaltaisuuden mittana avainsanojen dokumentoidessa runkoa ja metatietoa. BM25 on parempi mittari kuin TF-IDF, koska se ottaa asiakirjan pituuden huomioon, eli 200 sanan dokumentti, jossa on avainsana viisi kertaa, on todennäköisesti merkityksellisempi kuin 1500 sanan dokumentti, jossa se on yhtä monta kertaa.
on myös syytä sanoa, että signaalien määrä tässä on hyvin alkeellista ja ilmeisesti puuttuu monia tarkennuksia (ja tietoja), jotka Google on sisällyttänyt hakujärjestysalgoritmiinsa. Yksi tärkeimmistä asioista, joita työskentelemme on käyttää saatavilla olevaa dataa Common Crawl ja infrastruktuuri yhteisen haun tehdä aihe vektorihaku sisältöä, joka on relevantti perustuu semantiikka, ei vain avainsanojen matching.
on to PageRank
oheiselta sivulta löydät linkit isäntätason Pagerankiin kesäkuun 2016 yleiselle Ryöminnälle. Käytän sitä, jonka nimi on pagerank-top1m.txt.gz (top 1 miljoonaa) koska toinen tiedosto on 3GB ja yli 112 miljoonaa verkkotunnuksia. R: ssäkään minulla ei ole tarpeeksi konetta lataamaan sitä ilman korkkia.
lataamisen jälkeen sinun on tuotava tiedosto työhakemistoosi R: ssä.Common Search-ohjelman PageRank-tiedot eivät ole normalisoituja, eivätkä myöskään puhtaassa 0-10-muodossa, jossa olemme kaikki tottuneet näkemään sen. Yhteishaussa käytetään merkintää ” max (0, min(1, float(sijoitus) / 244660.58))” — pohjimmiltaan, verkkotunnuksen sijoitus jaettuna Facebook listalla — menetelmänä kääntää tiedot jakaumaksi välillä 0 ja 1. Mutta tämä jättää joitakin selviä aukkoja, että tämä jättäisi LinkedInin PageRank kuin 1.4 kun skaalataan 10.

seuraava koodi Lataa aineiston ja liittää siihen PR-sarakkeen, jonka likiarvo on parempi:
#Grab the datadf <- read.csv("pagerank-top1m.txt", header = F, sep = " ")#Log NormalizelogNorm <- function(x){ #Normalize x <- (x-min(x))/(max(x)-min(x)) 10 / (1 - (log10(x)*.25))}#Append a Column named PR to the datasetdf$pr <- (round(logNorm(df$V2),digits = 0))
meidän piti pelata noin hieman numerot saada se jonnekin lähelle (useita näytteitä verkkotunnuksia, että muistin PR) vanhaan Google PR. Alla on muutamia esimerkkejä PageRankin tuloksista:
- en.wikipedia.org (8)
- searchengineland.com (6)
- consultwebs.com (5)
- youtube.com (9)
- moz.com (6)
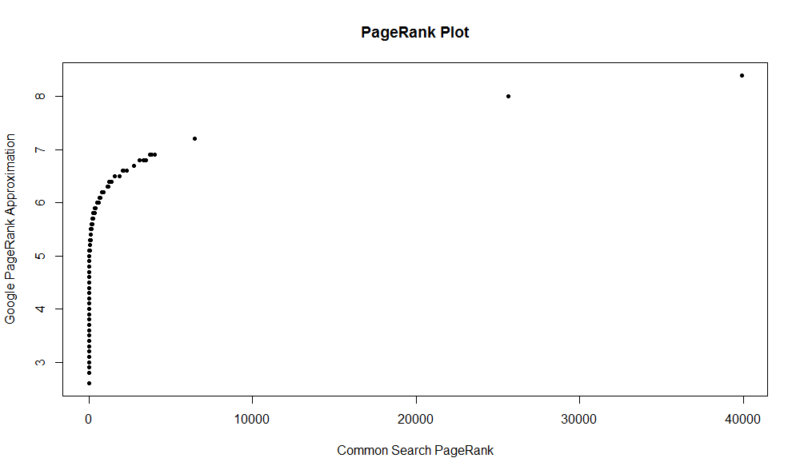
tässä on 100 000 satunnaisnäytteen juoni. Laskettu PageRankin pistemäärä on Y-akselin suuntainen ja alkuperäinen yhteinen Hakupiste X-akselin suuntainen.
nappataksesi omat tuloksesi, voit suorittaa seuraavan komennon R: ssä (korvaa vain oma verkkotunnuksesi):
df

muista, että tämä aineisto on vain alkuun miljoona verkkotunnuksia PageRank, joten ulos 112 miljoonaa verkkotunnuksia, jotka yhteinen haku indeksoitu, on hyvä mahdollisuus sivustosi ei ehkä ole olemassa, jos se ei ole melko hyvä linkki profiili. Tämä mittari ei myöskään sisällä mitään viitteitä linkkien haitallisuudesta, vain likiarvon sivustosi suosiosta linkkien suhteen.
yhteishaku on loistava työkalu ja hyvä perusta. Olen innolla saada enemmän mukana yhteisön siellä ja toivottavasti oppia ymmärtämään mutterit ja pultit takana hakukoneita paremmin itse työskentelemällä yksi. R ja pieni koodi, voit olla nopea tapa tarkistaa PR miljoona verkkotunnuksia muutamassa sekunnissa. Toivottavasti nautitte!
Rekisteröidy päivittäisiin kertauksiin alati muuttuvasta hakumarkkinointimaisemasta.
huomaa: lähettämällä tämän lomakkeen hyväksyt Third Door Median ehdot. Kunnioitamme yksityisyyttäsi.
tietoa tekijästä

JR Oakes on veturin teknisen SEO-tutkimuksen vanhempi johtaja. Hän toimi aiemmin adapt Partners Agencyn teknisen SEO: n johtajana. Hän työskentelee asiakkaiden kanssa monenlaisilla rintamilla, mukaan lukien tekniset kysymykset, suorituskyky, CTR, ryömintäkyky, sisältö ja data-analyysi. JR rakastaa testausta, koodausta ja prototyyppien ratkaisuja vaikeisiin hakumarkkinointiongelmiin. Kun hän ei ole töissä, hän nauttii lukemisesta kehittyvistä teknologioista, bassokitaran soittamisesta, yliopistokoripallon katselemisesta, ruoanlaitosta ja ajan viettämisestä ystäviensä ja perheensä kanssa. Hän on myös yksi Raleigh SEO Meetupin, Raleigh SEO Conferencen ja RTP SEO Meetupin järjestäjistä.