Gemeinsame Suche: Das Open Source Projekt bringt PageRank zurück
Melden Sie sich für unsere täglichen Rückblicke auf die sich ständig verändernde Suchmaschinenmarketing-Landschaft an.
Hinweis: Mit dem Absenden dieses Formulars stimmen Sie den Bedingungen von Third Door Media zu. Wir respektieren Ihre Privatsphäre.

In den letzten Jahren hat Google die Datenmenge, die SEO-Praktikern zur Verfügung steht, langsam reduziert. Zuerst waren es Keyword-Daten, dann PageRank-Score. Jetzt ist es spezifisches Suchvolumen von AdWords (es sei denn, Sie verbringen einige moola). Sie können mehr darüber in Russ Jones ‘ausgezeichnetem Artikel lesen, der die Auswirkungen der Forschung seines Unternehmens und Einblicke in Clickstream-Daten für die Volumendisambiguierung beschreibt.
Ein Punkt, an dem wir uns in letzter Zeit wirklich beteiligt haben, sind Common Crawl-Daten. Es gibt mehrere Teams in unserer Branche, die diese Daten seit einiger Zeit verwenden, daher fühlte ich mich etwas spät zum Spiel. Common Crawl Data ist ein Open-Source-Projekt, das in regelmäßigen Abständen das gesamte Internet kratzt. Zum Glück hat Amazon, das großartige Unternehmen, das es ist, die Daten gespeichert, um sie vielen ohne die hohen Speicherkosten zur Verfügung zu stellen.
Zusätzlich zu Common Crawl-Daten gibt es eine gemeinnützige Organisation namens Common Search, deren Aufgabe es ist, eine alternative Open Source- und transparente Suchmaschine zu erstellen — in vielerlei Hinsicht das Gegenteil von Google. Dies hat mein Interesse geweckt, weil es bedeutet, dass wir alle die Signale spielen, optimieren und mangeln können, um zu lernen, wie Suchmaschinen funktionieren, ohne die enorme Zeitinvestition, von Ground Zero aus zu starten.
Gemeinsame Suchdaten
Derzeit verwendet Common Search die folgenden Datenquellen zur Berechnung ihrer Suchrankings (diese werden direkt von ihrer Website übernommen):
- Common Crawl: Das größte offene Repository für Webcrawl-Daten. Dies ist derzeit unsere einzigartige Quelle für rohe Seitendaten.
- Wikidaten: Eine freie, verknüpfte Datenbank, die als zentraler Speicher für die strukturierten Daten vieler Wikimedia-Projekte wie Wikipedia, Wikivoyage und Wikisource dient.
- UT1 Blacklist: Diese Blacklist wird von Fabrice Prigent von der Université Toulouse 1 Capitole verwaltet und kategorisiert Domains und URLs in verschiedene Kategorien, darunter “adult” und “Phishing”.”
- DMOZ: Auch als Open Directory Project bekannt, ist es das älteste und größte noch lebende Webverzeichnis. Obwohl seine Daten nicht so zuverlässig sind wie in der Vergangenheit, verwenden wir sie immer noch als Signal- und Metadatenquelle.
- Web Data Commons Hyperlink Graphs: Graphen aller Hyperlinks aus einem 2012 Common Crawl Archiv. Wir verwenden derzeit die harmonische Zentralitätsdatei als temporäres Ranking-Signal für Domains. Wir planen, in naher Zukunft eine eigene Analyse des Webgraphen durchzuführen.
- Alexa Top 1M Websites: Alexa bewertet Websites anhand eines kombinierten Maßes für Seitenaufrufe und eindeutige Website-Benutzer. Es ist bekannt, demografisch voreingenommen zu sein. Wir verwenden es als temporäres Ranking-Signal für Domains.
Allgemeines Suchranking
Zusätzlich zu diesen Datenquellen werden bei der Untersuchung des Codes auch die URL-Länge, die Pfadlänge und der Domain-PageRank als Ranking-Signale in seinem Algorithmus verwendet. Siehe da, seit Juli hat Common Search seine eigenen Daten zum PageRank auf Host-Ebene, und wir alle haben es verpasst.
Ich komme gleich zum PageRank (PR), aber es ist interessant, den Code von Common Crawl zu überprüfen, insbesondere den Ranker.py befindet sich hier, weil Sie wirklich in den Fahrersitz gelangen können, indem Sie die Gewichte der Signale anpassen, mit denen die Seiten eingestuft werden:
signal_weights = {"url_total_length": 0.01,"url_path_length": 0.01,"url_subdomain": 0.1,"alexa_top1m": 5,"wikidata_url": 3,"dmoz_domain": 1,"dmoz_url": 1,"webdatacommons_hc": 1,"commonsearch_host_pagerank": 1}
Besonders hervorzuheben ist auch, dass Common Search BM25 als Ähnlichkeitsmaß für Keywords verwendet, um Body- und Metadaten zu dokumentieren. BM25 ist ein besseres Maß als TF-IDF, da es die Dokumentlänge berücksichtigt, was bedeutet, dass ein 200-Wort-Dokument, das Ihr Keyword fünfmal enthält, wahrscheinlich relevanter ist als ein 1.500-Wort-Dokument, das es gleich oft enthält.
Es lohnt sich auch zu sagen, dass die Anzahl der Signale hier sehr rudimentär ist und offensichtlich viele der Verfeinerungen (und Daten) fehlen, die Google in seinen Suchranking-Algorithmus integriert hat. Eines der wichtigsten Dinge, an denen wir arbeiten, ist die Verwendung der in Common Crawl verfügbaren Daten und der Infrastruktur von Common Search, um eine Themenvektorsuche nach Inhalten durchzuführen, die auf der Grundlage der Semantik relevant sind, nicht nur nach Keyword-Übereinstimmungen.
Weiter zum PageRank
Auf der Seite hier finden Sie Links zum Host-Level-PageRank für den Common Crawl vom Juni 2016. Ich benutze den mit dem Titel pagerank-top1m.txt.gz (Top 1 Million), weil die andere Datei 3 GB und über 112 Millionen Domains ist. Selbst in R habe ich nicht genug Maschine, um es zu laden, ohne es zu verschließen.
Nach dem Herunterladen müssen Sie die Datei in Ihr Arbeitsverzeichnis in R bringen. Die PageRank-Daten von Common Search sind nicht normalisiert und haben auch nicht das saubere 0-10-Format, in dem wir es alle gewohnt sind. Gemeinsame Suche verwendet “max (0, min (1, float ()) / 244660.58))” – im Grunde genommen der Rang einer Domain geteilt durch den Rang von Facebook – als Methode zur Übersetzung der Daten in eine Verteilung zwischen 0 und 1. Dies hinterlässt jedoch einige eindeutige Lücken, da dies den PageRank von Linkedin bei einer Skalierung um 10 als 1,4 belassen würde.

Der folgende Code lädt den Datensatz und hängt eine PR-Spalte mit einem besser angenäherten PR an:
#Grab the datadf <- read.csv("pagerank-top1m.txt", header = F, sep = " ")#Log NormalizelogNorm <- function(x){ #Normalize x <- (x-min(x))/(max(x)-min(x)) 10 / (1 - (log10(x)*.25))}#Append a Column named PR to the datasetdf$pr <- (round(logNorm(df$V2),digits = 0))
Wir mussten ein bisschen mit den Zahlen herumspielen, um sie (für einige Beispiele von Domains, für die ich mich an die PR erinnerte) der alten Google PR nahe zu bringen. Nachfolgend finden Sie einige Beispiel-PageRank-Ergebnisse:
- en.wikipedia.org (8)
- searchengineland.com (6)
- consultwebs.com (5)
- youtube.com (9)
- moz.com (6)
Hier ist ein Diagramm von 100.000 Zufallsstichproben. Der berechnete PageRank-Score liegt entlang der Y-Achse und der ursprüngliche allgemeine Suchwert entlang der X-Achse.
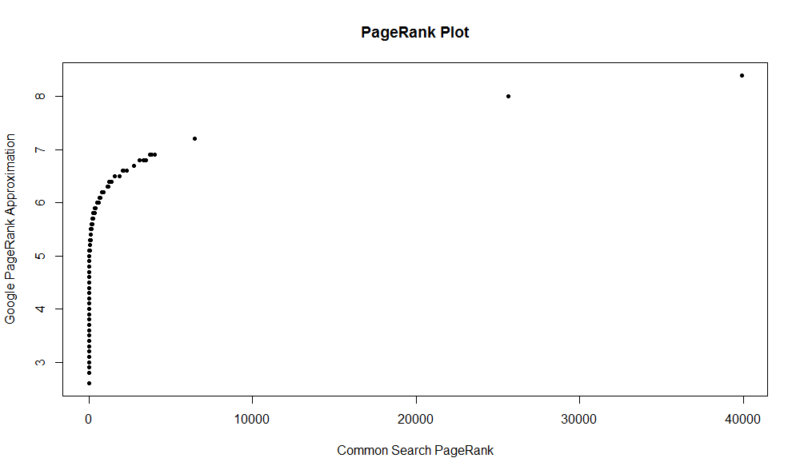
Um Ihre eigenen Ergebnisse zu erhalten, können Sie den folgenden Befehl in R ausführen (Ersetzen Sie einfach Ihre eigene Domäne):
df

Denken Sie daran, dass dieser Datensatz nur die Top eine Million Domains von PageRank hat, so aus 112 Millionen Domains, die gemeinsame Suche indiziert, gibt es eine gute Chance, Ihre Website nicht da sein kann, wenn es nicht ein ziemlich gutes Link-Profil hat. Außerdem enthält diese Metrik keinen Hinweis auf die Schädlichkeit von Links, sondern nur eine Annäherung an die Beliebtheit Ihrer Website in Bezug auf Links.
Common Search ist ein großartiges Werkzeug und eine großartige Grundlage. Ich freue mich darauf, mich mehr mit der Community dort zu beschäftigen und hoffentlich zu lernen, die Schrauben und Muttern hinter Suchmaschinen besser zu verstehen, indem ich tatsächlich an einer arbeite. Mit R und ein wenig Code können Sie PR für eine Million Domains in Sekundenschnelle überprüfen. Hoffe es hat euch gefallen!
Melden Sie sich für unsere täglichen Rückblicke auf die sich ständig verändernde Suchmaschinenmarketing-Landschaft an.
Hinweis: Mit dem Absenden dieses Formulars stimmen Sie den Bedingungen von Third Door Media zu. Wir respektieren Ihre Privatsphäre.
Über den Autor

JR Oakes ist Senior Director für technische SEO-Forschung bei Locomotive. Zuvor war er Director of Technical SEO bei der Agentur Adapt Partners. Er arbeitet mit Kunden an einer Vielzahl von Fronten, einschließlich technischer Probleme, Leistung, Klickrate, Crawling-Fähigkeit, Inhalt, und Datenanalyse. JR liebt das Testen, Codieren und Prototyping von Lösungen für schwierige Suchmaschinenmarketing-Probleme. Wenn er nicht arbeitet, liest er gerne über neue Technologien, spielt Bassgitarre, schaut College-Basketball, kocht und verbringt Zeit mit seinen Freunden und seiner Familie. Er ist auch einer der Mitorganisatoren des Raleigh SEO Meetup, der Raleigh SEO Conference und des RTP SEO Meetup.