Ceph
- Benchmark Ceph Cluster Performance GmbH>
- Get Baseline Performance Statistics GmbH
- a lemezek összehasonlítási alapjainak meghatározása!
- Benchmark your Network (Benchmark) (hálózati referenciaérték)
- Benchmark a Ceph tároló klaszter (Ceph)
- referenciaérték Ceph Blokkeszközöknél!
- Benchmark a Ceph Object Gateway GmbH
- következtetés 6249>
Benchmark Ceph Cluster Performance GmbH>
az egyik leggyakoribb kérdés, amit hallunk: “Hogyan ellenőrizhetem, hogy a klaszterem maximális teljesítményen fut-e?”. Nem csoda többé-ebben az útmutatóban, végigvezetünk néhány eszközt, amellyel összehasonlíthatja a Ceph klaszterét.
megjegyzés: a cikkben szereplő ötletek Sebastian Han blogbejegyzésén, a TelekomCloud blogbejegyzésén és a Ceph fejlesztőitől és mérnökeitől származó inputokon alapulnak.
Get Baseline Performance Statistics GmbH
alapvetően a benchmarking az összehasonlításról szól. Nem fogja tudni, hogy a Ceph-fürt par alatt teljesít-e, hacsak nem először határozza meg, hogy mi a maximális lehetséges teljesítménye. Tehát a klaszter benchmarkingjának megkezdése előtt be kell szereznie a Ceph infrastruktúra két fő összetevőjére vonatkozó alapszintű teljesítménystatisztikát: a lemezekre és a hálózatra.
a lemezek összehasonlítási alapjainak meghatározása!
a lemez összehasonlításának legegyszerűbb módja a dd. Használja a következő parancsot egy fájl olvasásához és írásához, ne felejtse el hozzáadni az oflag paramétert a lemezlap gyorsítótárának megkerüléséhez:shell> dd if=/dev/zero of=here bs=1G count=1 oflag=direct
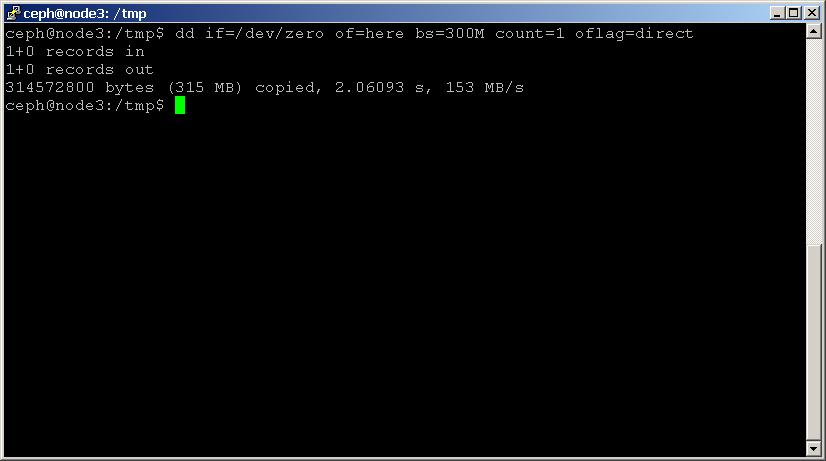
vegye figyelembe az utolsó megadott statisztikát, amely a lemez teljesítményét MB/sec-ben jelzi. végezze el ezt a tesztet a fürt minden lemezén, megjegyezve az eredményeket.
Benchmark your Network (Benchmark) (hálózati referenciaérték)
a Ceph-klaszter teljesítményét befolyásoló másik kulcsfontosságú tényező a hálózati teljesítmény. Jó eszköz erre az iperf, amely kliens-szerver kapcsolatot használ a TCP és UDP sávszélesség mérésére.
az iperf telepítése az apt-get install iperf vagy a yum install iperf használatával lehetséges.
az iperf-et a fürt legalább két csomópontjára kell telepíteni. Ezután az egyik csomóponton indítsa el az iperf szervert a következő paranccsal:
shell> iperf -s
egy másik csomóponton indítsa el az Ügyfelet a következő paranccsal, ne felejtse el használni az iperf szervert tároló csomópont IP-címét:
shell> iperf -c 192.168.1.1
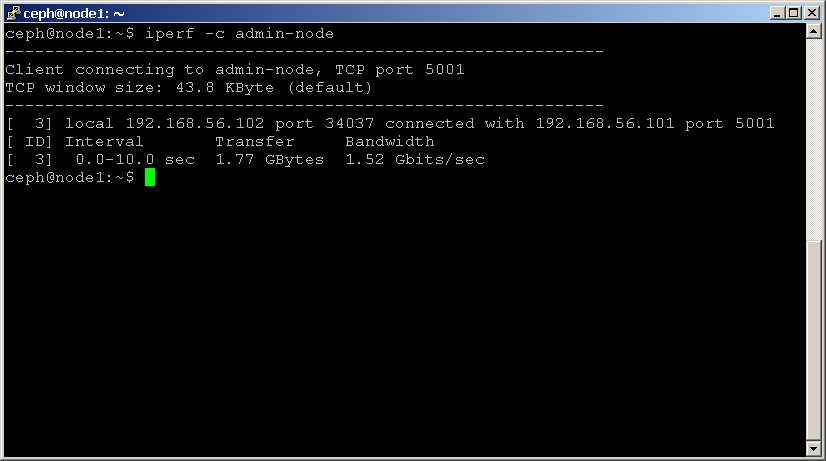
vegye figyelembe a sávszélesség-statisztikát Mbit/sec-ben, mivel ez jelzi a hálózat által támogatott maximális átviteli sebességet.
most, hogy rendelkezik néhány alapszámmal, elkezdheti a Ceph-klaszter benchmarkingját, hogy lássa, hasonló teljesítményt nyújt-e. A Benchmarking különböző szinteken végezhető el: elvégezheti magának a tárolófürtnek az alacsony szintű benchmarkingját, vagy elvégezheti a kulcsfontosságú interfészek, például a blokkeszközök és az objektum-átjárók magasabb szintű benchmarkingját. A következő szakaszok ezeket a megközelítéseket tárgyalják.
megjegyzés: mielőtt futtatná a referenciaértékeket a következő szakaszokban, dobja el az összes gyorsítótárat egy ilyen paranccsal:shell> sudo echo 3 | sudo tee /proc/sys/vm/drop_caches && sudo sync
Benchmark a Ceph tároló klaszter (Ceph)
a Ceph tartalmazza a rados bench parancsot, amelyet kifejezetten a RADOS tároló klaszter referenciaértékére terveztek. Használatához hozzon létre egy tárolókészletet, majd a rados bench segítségével hajtsa végre az írási referenciaértéket, az alábbiak szerint.
a rados parancsot a Ceph tartalmazza.
shell> ceph osd pool create scbench 128 128
shell> rados bench -p scbench 10 write --no-cleanup
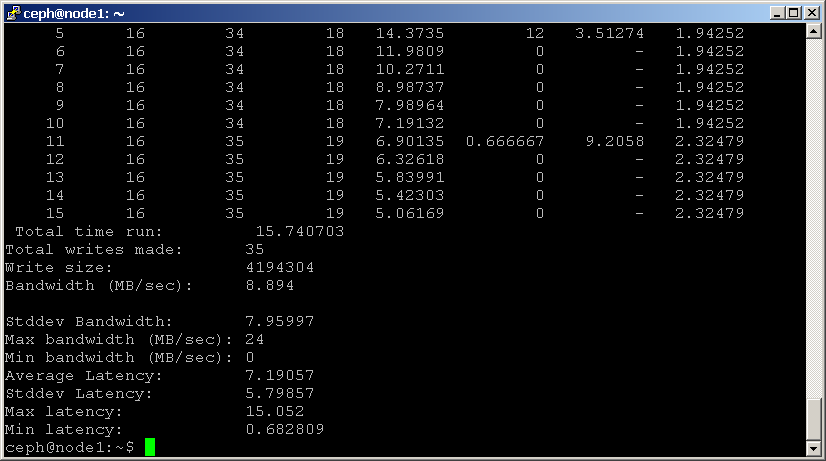
ez létrehoz egy új készletet ‘scbench’ néven, majd 10 másodpercig írási referenciaértéket hajt végre. Figyelje meg a — no-cleanup opciót, amely néhány adatot hagy maga után. A kimenet jól jelzi, hogy a fürt milyen gyorsan tud adatokat írni.
kétféle olvasási referenciaérték áll rendelkezésre: seq szekvenciális olvasáshoz és rand véletlenszerű olvasáshoz. Olvasási referenciaérték végrehajtásához használja az alábbi parancsokat:shell> rados bench -p scbench 10 seq
shell> rados bench -p scbench 10 rand
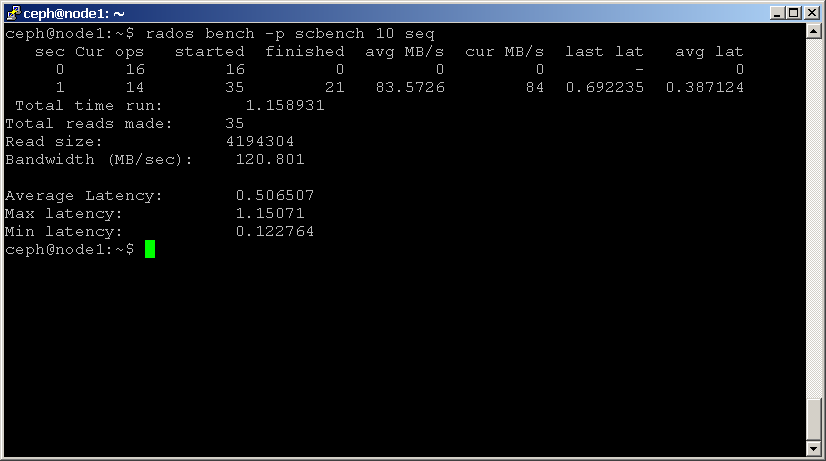
hozzáadhatja a-t paramétert az olvasás és írás párhuzamosságának növeléséhez (alapértelmezés szerint 16 szál), vagy a-b paramétert az írandó objektum méretének megváltoztatásához (alapértelmezés szerint 4 MB). Az is jó ötlet, ha ennek a referenciaértéknek több példányát futtatja különböző készletekkel, hogy megnézze, hogyan változik a teljesítmény több ügyfélnél.
az adatok megszerzése után elkezdheti összehasonlítani a fürt olvasási és írási statisztikáit a korábban elvégzett, csak lemezes referenciaértékekkel, azonosíthatja, hogy mekkora a teljesítménybeli különbség (ha van ilyen), és elkezdheti keresni az okokat.
ezzel a paranccsal megtisztíthatja az írási benchmark által hátrahagyott benchmark adatokat:
shell> rados -p scbench cleanup
referenciaérték Ceph Blokkeszközöknél!
Ha rajongsz a Ceph blokk Eszközökért, két eszközzel mérheted a teljesítményüket. A Ceph már tartalmazza az rbd bench parancsot, de használhatja a népszerű I/O benchmarking eszközt, a fio-t is, amely most már beépített támogatással rendelkezik a RADOS blokk eszközökhöz.
az rbd parancsot a Ceph tartalmazza. Az RBD támogatás a fio-ban viszonylag új, ezért le kell töltenie a tárházából, majd le kell fordítania és telepítenie kell using_ configure && make && make install_. Ne feledje, hogy a Fio fordítása előtt telepítenie kell a librbd-dev fejlesztői csomagot az apt-get install librbd-dev vagy a yum install librbd-dev programmal az RBD támogatás aktiválásához.
a két eszköz bármelyikének használata előtt azonban hozzon létre egy blokkeszközt az alábbi parancsok segítségével:shell> ceph osd pool create rbdbench 128 128
shell> rbd create image01 --size 1024 --pool rbdbench
shell> sudo rbd map image01 --pool rbdbench --name client.admin
shell> sudo /sbin/mkfs.ext4 -m0 /dev/rbd/rbdbench/image01
shell> sudo mkdir /mnt/ceph-block-device
shell> sudo mount /dev/rbd/rbdbench/image01 /mnt/ceph-block-device
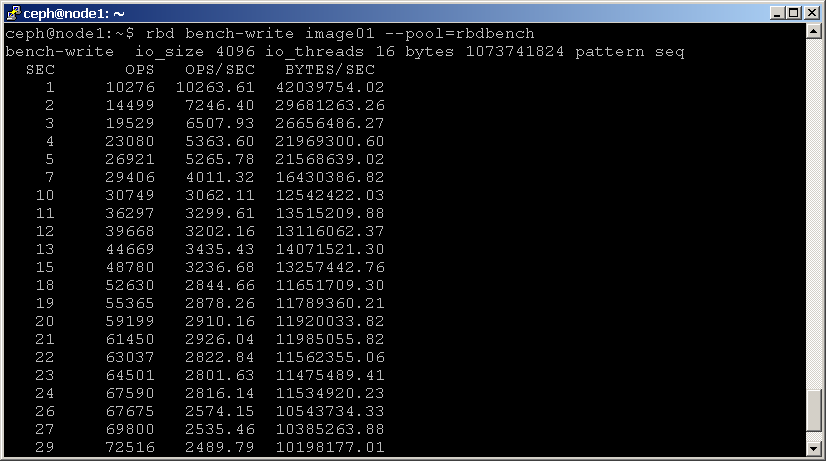
az rbd bench-write parancs szekvenciális írások sorozatát generálja a képre, és megméri az írási teljesítményt és a késleltetést. Íme egy példa:
shell> rbd bench-write image01 --pool=rbdbench
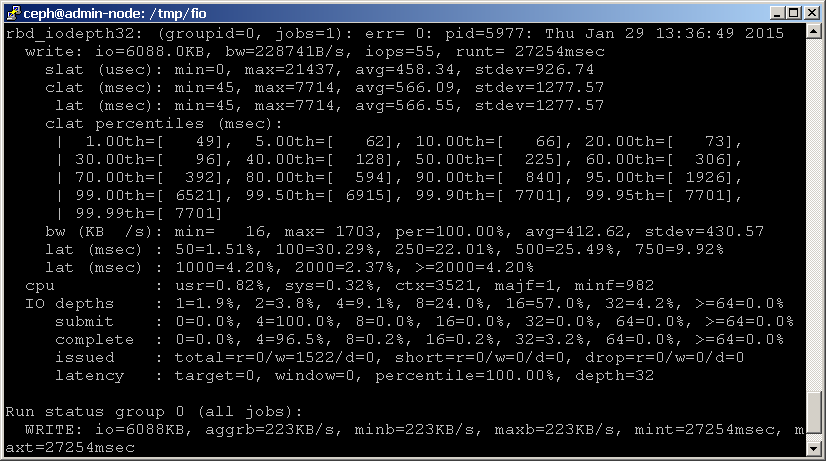
vagy használhatja a fio-t a blokkeszköz összehasonlításához. Egy példa rbd.a fio sablon a fio forráskódhoz tartozik, amely 4k véletlenszerű írási tesztet hajt végre egy RADOS blokk eszközzel librbd-n keresztül. Ne feledje, hogy frissítenie kell a sablont a medence és az eszköz helyes nevével, az alábbiak szerint.
ioengine=rbd
clientname=admin
pool=rbdbench
rbdname=image01
rw=randwrite
bs=4k
iodepth=32
ezután futtassa a fio-t az alábbiak szerint:shell> fio examples/rbd.fio
Benchmark a Ceph Object Gateway GmbH
Mikor jön a benchmarking a Ceph object gateway, ne keressen tovább, mint swift-bench, a benchmarking eszköz tartalmazza OpenStack Swift. A swift-bench eszköz teszteli a Ceph-fürt teljesítményét a kliens PUT és GET kérések szimulálásával és teljesítményük mérésével.
a swift-padot a pip install swift && pip install swift-bench használatával telepítheti.
a swift-bench használatához először létre kell hoznia egy átjáró felhasználót és alfelhasználót, az alábbiak szerint:shell> sudo radosgw-admin user create --uid="benchmark" --display-name="benchmark"
shell> sudo radosgw-admin subuser create --uid=benchmark --subuser=benchmark:swift
--access=full
shell> sudo radosgw-admin key create --subuser=benchmark:swift --key-type=swift
--secret=guessme
shell> radosgw-admin user modify --uid=benchmark --max-buckets=0
ezután hozzon létre egy konfigurációs fájlt a swift-bench számára egy kliens gazdagépen, az alábbiak szerint. Ne felejtse el frissíteni a hitelesítési URL-t, hogy tükrözze a Ceph objektumátjáró URL-jét, és a helyes felhasználónevet és hitelesítő adatokat használja.
auth = http://gateway-node/auth/v1.0
user = benchmark:swift
key = guessme
auth_version = 1.0
most futtathat egy benchmarkot az alábbiak szerint. Használja a-c paramétert az egyidejű kapcsolatok számának beállításához (Ez a példa 64-et használ), az-s paramétert pedig az írandó objektum méretének beállításához (Ez a példa 4K objektumokat használ). Az -n és-g paraméterek szabályozzák az objektumok számát.shell> swift-bench -c 64 -s 4096 -n 1000 -g 100 /tmp/swift.conf
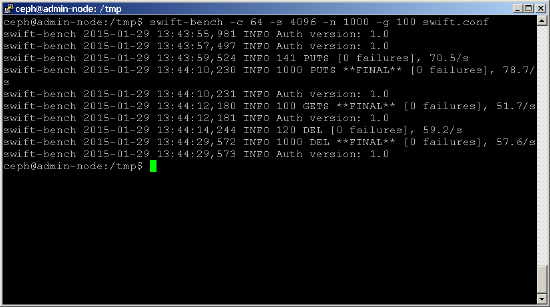
bár a swift-bench az objektumok/sec-ben méri a teljesítményt, elég könnyű ezt MB/sec-re konvertálni, megszorozva az egyes objektumok méretével. Azonban óvatosnak kell lennie, ha ezt közvetlenül összehasonlítja a korábban megszerzett alaplemez teljesítménystatisztikákkal, mivel számos más tényező is befolyásolja ezeket a statisztikákat, mint például:
- a replikáció szintje (és a késleltetési költség)
- teljes adatnapló írások (egyes helyzetekben a napló adatok egyesítésével ellensúlyozva)
- fsync az OSDs-en az adatbiztonság garantálása érdekében
- metaadatok a Rados-ban tárolt adatok megőrzéséhez
- késleltetés felső (hálózat, Ceph, stb) teszi readahead fontosabb
tip: Amikor az object gateway teljesítményéről van szó, nincs olyan kemény és gyors szabály, amellyel egyszerűen javíthatja a teljesítményt. Egyes esetekben a Ceph mérnökei okos gyorsítótárazási és egyesítési stratégiákkal jobb teljesítményt tudtak elérni, míg más esetekben az objektumátjáró teljesítménye alacsonyabb volt, mint a lemez teljesítménye a késleltetés, az fsync és a metaadatok fölött.
következtetés 6249>
számos eszköz áll rendelkezésre a Ceph-klaszterek összehasonlításához, különböző szinteken: lemez, hálózat, fürt, eszköz és átjáró. Most már betekintést kell nyernie a benchmarking folyamat megközelítésébe, és el kell kezdenie a klaszter teljesítményadatainak generálását. Sok szerencsét!