Cloud adattárház vs hagyományos adattárház koncepciók
a felhőalapú adattárházak az új norma. Elmúltak azok a napok, amikor vállalkozásának hardvert kellett vásárolnia, szerverszobákat kellett létrehoznia, és külön munkatársakat kellett bérelnie, kiképeznie és fenntartania annak működtetéséhez. Most, néhány kattintással a laptopra és a hitelkártyára, gyakorlatilag korlátlan számítási teljesítményt és tárhelyet érhet el.
ez azonban nem jelenti azt, hogy a hagyományos adattárház-ötletek halottak. Klasszikus adattárház elmélet alátámasztja a legtöbb, amit a felhő-alapú adattárházak csinálni.
ebben a cikkben elmagyarázzuk a hagyományos adattárház-koncepciókat, amelyeket ismernie kell, és a legfontosabb felhőket a legjobb szolgáltatók közül: az Amazon, a Google és a Panoply. Végül lezárjuk a hagyományos vs. felhő adattárházak költség-haszon elemzését, így tudja, melyik az Ön számára megfelelő.
kezdjük.
- hagyományos adattárház koncepciók
- tények, dimenziók és mértékek
- normalizálás és Denormalizálás
- adatmodellek
- ténytábla
- csillag séma vs.hópehely séma
- OLAP vs.OLTP
- háromszintű architektúra
- virtuális adattárház / Data Mart
- Kimball vs.Inmon
- ETL vs.ELT
- vállalati adattárház
- felhő adattárház koncepciók
- Cloud Data Warehouse Concepts – Amazon Redshift
- klaszterek
- csomópontok
- partíciók/szeletek
- oszlopos Tárolás
- tömörítés
- Adattöltés
- Cloud Database Warehouse – Google BigQuery
- szerver nélküli szolgáltatás
- Colossus fájlrendszer
- Dremel végrehajtó Motor
- adatmegosztás
- Streaming és Batch Lenyelés
- Cloud Data Warehouse Concepts – Panoply
- elsődleges kulcsok
- növekményes kulcsok
- beágyazott adatok
- Előzménytáblák
- transzformációk
- Karakterláncformátumok
- Adatvédelem
- hozzáférés-vezérlés
- IP Engedélyezőlista
- következtetés: hagyományos vs.adattárház fogalmak röviden
- hagyományos adattárház fogalmak
- Cloud Data Warehouse Concepts – Amazon Redshift példaként
- Cloud Data Warehouse Concepts – BigQuery példaként
- hagyományos vs. felhő költség-haszon elemzés
- Tudjon meg többet az Adattárházakról
hagyományos adattárház koncepciók
az adattárház minden olyan rendszer, amely egy szervezeten belül számos forrásból gyűjt adatokat. Az adattárházakat analitikai és jelentéstételi célokra központosított adattárházként használják.
hagyományos adattárház található a helyszínen az irodáiban. Megveszed a hardvert, a szervertermeket, és felbéreled a személyzetet, hogy működtessék. Ezeket helyszíni, on-prem vagy (nyelvtanilag helytelen) helyszíni adattárházaknak is nevezik.
tények, dimenziók és mértékek
az adattárház információinak alapvető építőelemei a tények, dimenziók és mértékek.
a tény az adatok azon része, amely egy adott eseményt vagy tranzakciót jelez. Például, ha vállalkozása virágokat értékesít, néhány tény, amelyet az adattárházában látna:
- eladott 30 rózsák in-store $ 19.99
- rendelt 500 új virágcserepek Kínából $ 1500
- Fizetett fizetése pénztáros ebben a hónapban $1000
több szám is leírhat minden tényt, és ezeket a számokat méréseknek nevezzük. Néhány intézkedés annak leírására ,hogy ‘500 új virágcserepet rendeltek Kínából 1500 dollárért’:
- megrendelt mennyiség-500
- költség – $1500
amikor az elemzők adatokkal dolgoznak, számításokat végeznek az intézkedésekről (például összeg, maximum, átlag), hogy betekintést nyerjenek. Például érdemes tudni, hogy a havonta megrendelt virágcserepek átlagos száma.
egy dimenzió kategorizálja a tényeket és a mértékeket, és strukturált címkézési információkat nyújt számukra – különben csak rendezetlen számok gyűjteménye lenne! Néhány dimenzió annak leírására ,hogy ‘500 új virágcserepet rendeltek Kínából 1500 dollárért’:
- ország vásárolt-Kína
- idő vásárolt-1 pm
- várható érkezési dátum-június 6.
nem lehet számításokat végezni a méretek kifejezetten, és ezzel valószínűleg nem lenne nagyon hasznos – hogyan lehet megtalálni a ‘Átlagos érkezési dátum megrendelések’? Lehetséges azonban dimenziókból új intézkedéseket létrehozni, amelyek hasznosak. Ha például ismeri a megrendelés dátuma és az érkezés dátuma közötti napok átlagos számát, akkor jobban megtervezheti a készletvásárlásokat.
normalizálás és Denormalizálás
a normalizálás az adatok hatékony rendszerezésének folyamata egy adattárházban (vagy bármely más helyen, amely adatokat tárol). A fő célok az adatok redundanciájának csökkentése – azaz az ismétlődő adatok eltávolítása – és az adatok integritásának javítása-azaz az adatok pontosságának javítása. A normalizációnak különböző szintjei vannak, és nincs konszenzus a legjobb módszerről. Azonban minden módszer magában foglalja a különálló, de kapcsolódó információk tárolását különböző táblázatokban.
a normalizálásnak számos előnye van, például:
- gyorsabb keresés és rendezés minden táblán
- az egyszerűbb táblák az adatmódosítási parancsok gyorsabb írását és végrehajtását teszik lehetővé
- A kevesebb redundáns adat azt jelenti, hogy lemezterületet takarít meg, így több adatot gyűjthet és tárolhat
a Denormalizálás a redundáns másolatok vagy adatcsoportok szándékos hozzáadásának folyamata a már normalizált adatokhoz. Ez nem ugyanaz, mint a nem normalizált adatok. A denormalizálás javítja az olvasási teljesítményt, és sokkal könnyebbé teszi a táblázatok kívánt űrlapokká alakítását. Amikor az elemzők adattárházakkal dolgoznak, általában csak az adatok olvasását végzik. Így a denormalizált adatok hatalmas időt és fejfájást takaríthatnak meg nekik.
a denormalizáció előnyei:
- kevesebb tábla minimalizálja a táblaillesztések szükségességét, ami felgyorsítja az adatelemzők munkafolyamatát, és arra készteti őket, hogy több hasznos betekintést fedezzenek fel az adatokban
- kevesebb tábla egyszerűsíti a lekérdezéseket, ami kevesebb hibához vezet
adatmodellek
vadul nem lenne hatékony az összes adatot egy hatalmas táblában tárolni. Tehát az adattárház számos táblát tartalmaz, amelyeket összekapcsolhat, hogy konkrét információkat kapjon. A főtáblát ténytáblának hívják, a dimenziótáblák pedig körülveszik.
az adattárház tervezésének első lépése egy koncepcionális adatmodell felépítése, amely meghatározza a kívánt adatokat és a köztük lévő magas szintű kapcsolatokat.
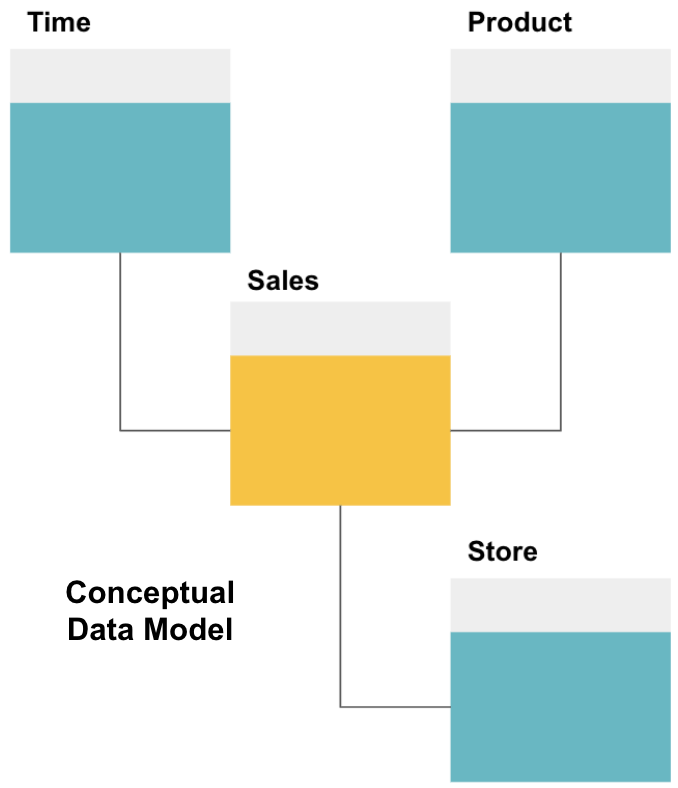
itt definiáltuk a fogalmi modellt. Értékesítési adatokat tárolunk, és három további táblázattal rendelkezünk-idő, Termék és áruház -, amelyek extra, részletesebb információkat nyújtanak minden egyes értékesítésről. A tény táblázat az értékesítés, a többi pedig dimenziós táblázat.
a következő lépés egy logikai adatmodell meghatározása. Ez a modell részletesen leírja az adatokat egyszerű angol nyelven, anélkül, hogy aggódna a kódban történő megvalósítás miatt.
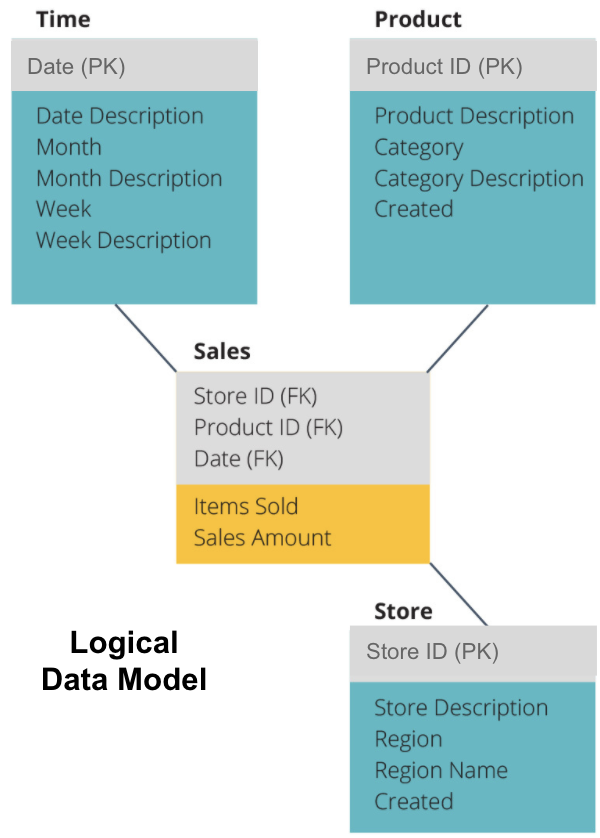
most kitöltöttük, hogy az egyes táblázatok mely információkat tartalmazzák egyszerű angol nyelven. A Time, Product és Store dimenzió táblázatok mindegyike az elsődleges kulcsot (PK) mutatja a szürke mezőben, a megfelelő adatokat pedig a kék mezőben. Az értékesítési táblázat három idegen kulcsot (FK) tartalmaz, így gyorsan csatlakozhat a többi táblához.
az utolsó lépés egy fizikai adatmodell létrehozása. Ez a modell megmutatja, hogyan kell végrehajtani az adattárházat kódban. Meghatározza a táblázatokat, azok szerkezetét és a köztük lévő kapcsolatot. Megadja az oszlopok adattípusait is, és minden meg van nevezve, ahogy a végső adattárházban lesz, azaz minden nagybetűvel és aláhúzással összekapcsolva. Végül minden dimenziótábla DIM_ – vel kezdődik, és minden ténytábla FACT_-vel kezdődik.
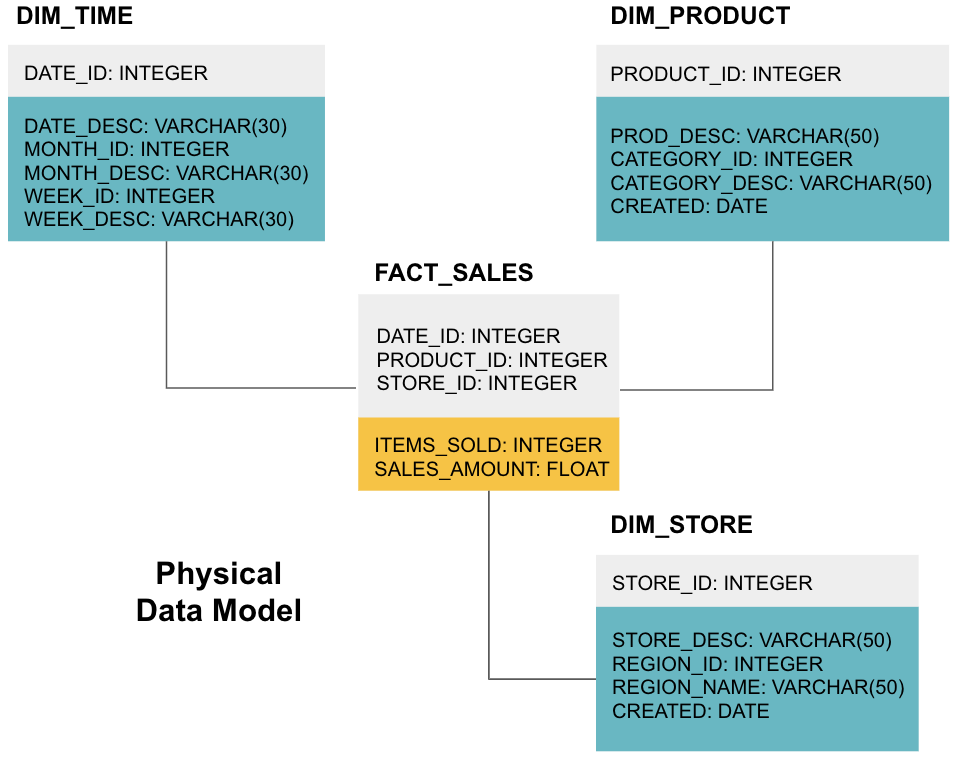
most már tudja, hogyan kell megtervezni egy adattárházat, de van néhány árnyalat a tény-és dimenziótáblákban, amelyeket a következőkben ismertetünk.
ténytábla
minden üzleti funkciónak – pl. értékesítés, marketing, pénzügy – van egy megfelelő ténytáblája.
a ténytáblák kétféle oszlopot tartalmaznak: dimenzióoszlopokat és tényoszlopokat. A dimenzióoszlopok – a példáinkban szürke színűek-idegen kulcsokat (FK) tartalmaznak, amelyeket egy ténytábla dimenziótáblával való összekapcsolásához használ. Ezek az idegen kulcsok az egyes dimenziótáblák elsődleges kulcsai (PK). A példánkban sárga színű tényoszlopok tartalmazzák az elemzendő tényleges adatokat és intézkedéseket, például az eladott tételek számát és az eladások teljes dollárértékét.
a tény nélküli ténytábla egy bizonyos típusú ténytábla, amelynek csak dimenzióoszlopai vannak. Az ilyen táblázatok hasznosak az események, például a hallgatói részvétel vagy a munkavállalói szabadság nyomon követéséhez, mivel a méretek mindent elmondanak, amit tudnia kell az eseményekről.
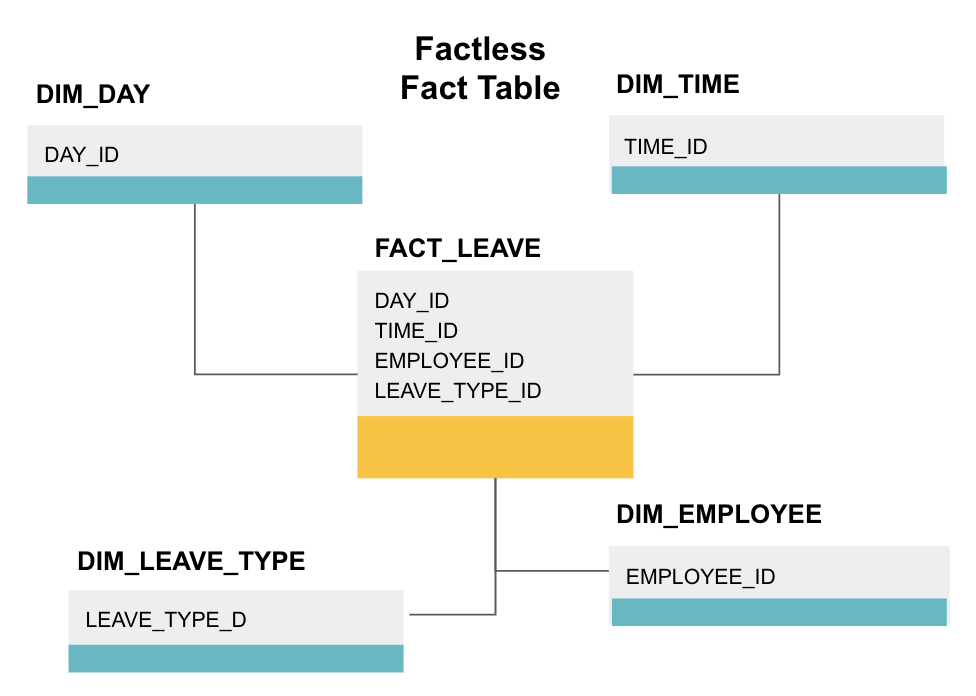
a fenti factless fact táblázat nyomon követi az alkalmazottak szabadságát. Nincsenek tények, mivel csak tudnod kell:
- melyik napon voltak ki (DAY_ID).
- mennyi ideig voltak kikapcsolva (TIME_ID).
- ki volt szabadságon (EMPLOYEE_ID).
- a szabadság oka, pl., betegség, ünnep, orvos kinevezése stb. (LEAVE_TYPE_ID).
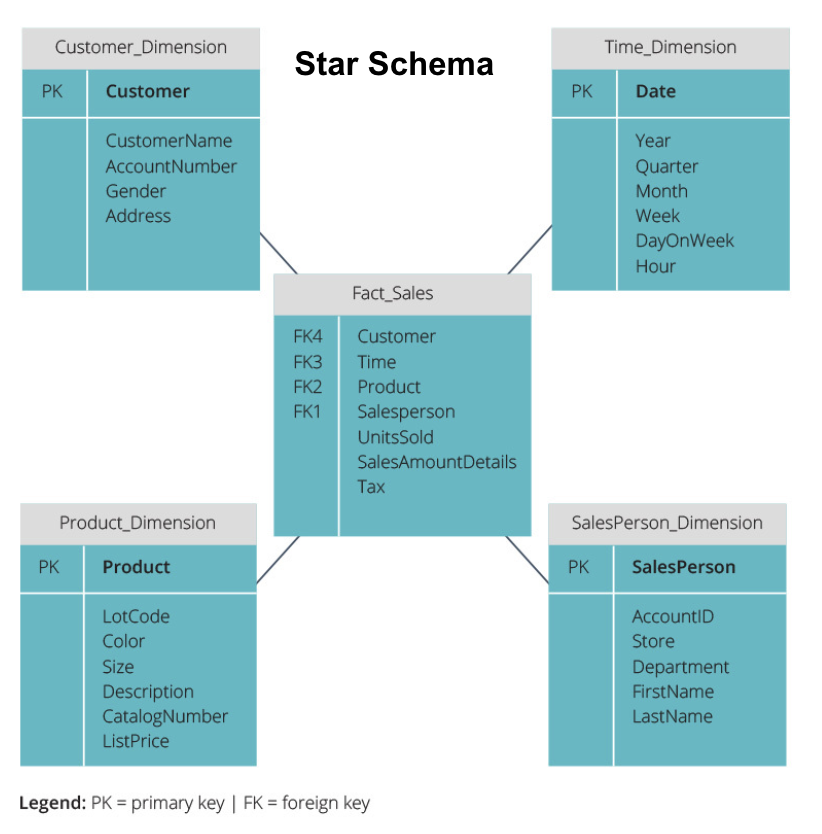
csillag séma vs.hópehely séma
a fenti adattárházak mindegyike hasonló elrendezésű volt. Ez azonban nem az egyetlen módja annak, hogy elrendezzük őket.
az adattárházak szervezéséhez használt két leggyakoribb séma a csillag és a hópehely. Mindkét módszer dimenziótáblákat használ, amelyek leírják a ténytáblában található információkat.
a csillagséma a ténytáblából veszi az információt, és denormalizált dimenziótáblákra osztja. A csillagséma hangsúlya a lekérdezés sebességén van. Csak egy csatlakozás szükséges a ténytáblák összekapcsolásához az egyes dimenziókhoz, így az egyes táblák lekérdezése egyszerű. Mivel azonban a táblák denormalizáltak, gyakran ismétlődő és redundáns adatokat tartalmaznak.
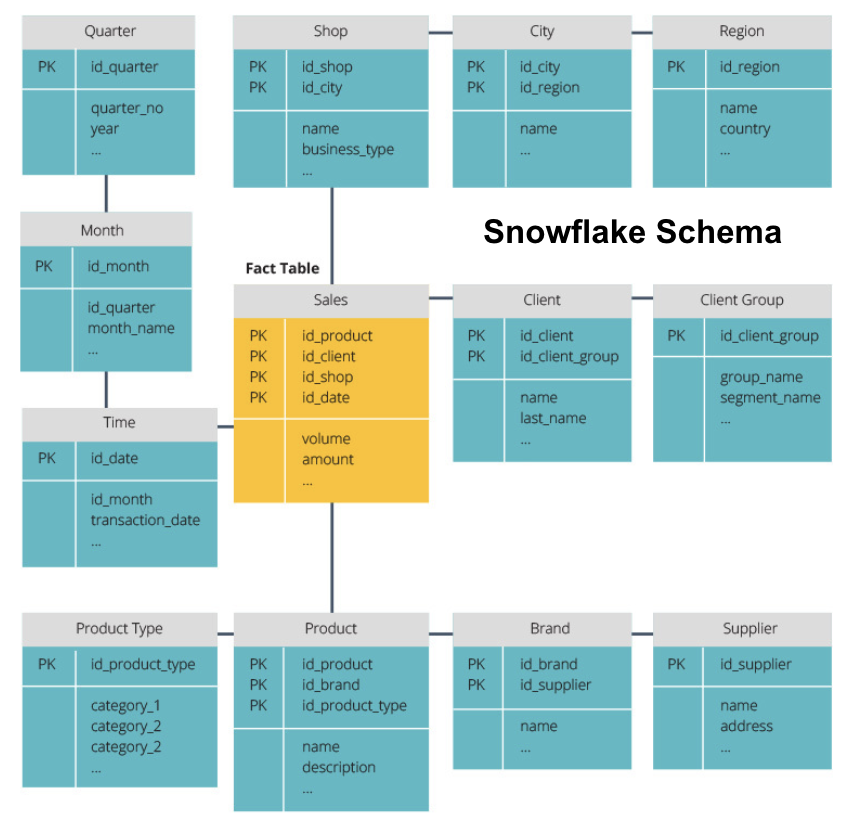
a hópehely séma a ténytáblát normalizált dimenziótáblák sorozatára osztja. A normalizálás több dimenziótáblát hoz létre, és így csökkenti az adatintegritási problémákat. A lekérdezés azonban nagyobb kihívást jelent a hópehely séma használatával, mert a releváns adatok eléréséhez több táblaillesztésre van szükség. Tehát kevesebb redundáns adat van, de nehezebb hozzáférni.
most elmagyarázunk néhány alapvető adattárház-koncepciót.
OLAP vs.OLTP
az online tranzakciófeldolgozást (OLTP) rövid írási tranzakciók jellemzik, amelyek magukban foglalják a vállalati adatarchitektúra front-end alkalmazásait. Az OLTP adatbázisok hangsúlyozzák a gyors lekérdezésfeldolgozást, és csak az aktuális adatokkal foglalkoznak. A vállalkozások ezeket arra használják, hogy információkat rögzítsenek az üzleti folyamatokhoz, és forrásadatokat biztosítsanak az adattárház számára.
az online analitikai feldolgozás (OLAP) lehetővé teszi összetett olvasási lekérdezések futtatását, és így a múltbeli tranzakciós adatok részletes elemzését. Az OLAP rendszerek segítenek az adattárház adatainak elemzésében.
háromszintű architektúra
a hagyományos adattárházak jellemzően három szintben vannak felépítve:
- alsó szint: adatbázis-kiszolgáló, általában egy RDBMS, amely átjáró segítségével különböző forrásokból nyer ki adatokat. Az ebbe a rétegbe betáplált adatforrások közé tartoznak az operatív adatbázisok és más típusú front-end adatok, például CSV és JSON fájlok.
- középső szint: olyan OLAP-kiszolgáló, amely vagy
- közvetlenül végrehajtja a műveleteket, vagy
- a többdimenziós adatokon végzett műveleteket szabványos relációs műveletekre térképezi fel, például az XML vagy JSON adatok táblázatokon belüli sorokba simításával.
- Felső szint: az adatelemzés és az üzleti intelligencia lekérdezési és jelentési eszközei.
virtuális adattárház / Data Mart
a virtuális adattárház több adatbázisban elosztott lekérdezéseket használ, anélkül, hogy az adatokat egyetlen fizikai adattárházba integrálná.
az adattárházak az adattárházak részhalmazai, amelyek meghatározott üzleti funkciókra, például értékesítésre vagy pénzügyre irányulnak. Az adattárház általában több adatpiacból származó információkat kombinál több Üzleti funkcióban. Mégis, a data mart tartalmaz adatokat egy sor forrás rendszerek egy üzleti funkció.
Kimball vs.Inmon
az adattárház tervezésének két megközelítése van, Bill Inmon és Ralph Kimball által javasolt. Bill Inmon egy amerikai számítógépes tudós, akit az adattárház atyjaként ismernek el. Ralph Kimball az adattárház egyik eredeti építésze, számos könyvet írt a témáról.
a két szakértő ellentmondásos véleményt fogalmazott meg az adattárházak felépítéséről. Ez a konfliktus két gondolkodási iskolát eredményezett.
az Inmon megközelítés felülről lefelé tervez. Az Inmon módszertanával először az adattárház jön létre, amelyet az analitikai környezet központi elemének tekintenek. Az adatokat ezután összegzik és elosztják a központosított raktárból egy vagy több függő adattárházba.
a Kimball megközelítés alulról felfelé néz az adattárház tervezéséről. Ebben az architektúrában a szervezet külön adatpiacokat hoz létre, amelyek nézeteket biztosítanak a szervezet egyetlen részlegére. Az adattárház ezeknek az adatpiacoknak a kombinációja.
ETL vs.ELT
az Extract, Transform, Load (ETL) az adatok forrásrendszerekből (jellemzően tranzakciós rendszerekből) történő kinyerésének folyamatát írja le, az adatokat lekérdezésre és elemzésre alkalmas formátumba vagy struktúrába konvertálja, majd végül betölti az adattárházba. Az ETL egy külön átmeneti adatbázist használ, és egy sor szabályt vagy funkciót alkalmaz a kibontott adatokra a betöltés előtt.
az Extract, Load, Transform (ELT) az adatok betöltésének más megközelítése. Az ELT különböző forrásokból veszi az adatokat, és közvetlenül betölti azokat a célrendszerbe, például az adattárházba. Ezután a rendszer igény szerint átalakítja a betöltött adatokat az elemzés lehetővé tétele érdekében.
az ELT gyorsabb betöltést kínál, mint az ETL, de nagy teljesítményű rendszerre van szükség az adatátalakítások igény szerinti végrehajtásához.
vállalati adattárház
a vállalati adattárház egységes, központosított raktárként szolgál, amely a szervezet összes tranzakciós információját tartalmazza, mind az aktuális, mind a történelmi információkat. A vállalati adattárháznak tartalmaznia kell az üzleti tevékenységhez kapcsolódó összes tárgyterület adatait, például a marketinget, az értékesítést, a pénzügyeket és az emberi erőforrásokat.
ezek az alapvető ötletek alkotják a hagyományos adattárházakat. Most nézzük meg, hogy a felhő adattárházak mit adtak hozzá a tetejükhöz.
felhő adattárház koncepciók
a felhő adattárházak újak és folyamatosan változnak. Alapvető fogalmaik legjobb megértése érdekében a legjobb, ha megismerjük a vezető felhőalapú adattárház-megoldásokat.
három vezető felhőalapú adattárház-megoldás az Amazon Redshift, a Google BigQuery és a Panoply. Az alábbiakban ismertetjük az egyes szolgáltatások alapvető fogalmait, hogy általános megértést nyújtsunk Önnek a modern adattárházak működéséről.
Cloud Data Warehouse Concepts – Amazon Redshift
a következő fogalmakat kifejezetten használják az Amazon Redshift cloud data warehouse-ban, de a jövőben az Amazon infrastruktúráján alapuló további adattárházi megoldásokra is vonatkozhatnak.
klaszterek
az Amazon Redshift architektúráját klaszterekre alapozza. A klaszter egyszerűen megosztott számítási erőforrások csoportja, az úgynevezett csomópontok.
csomópontok
a csomópontok olyan számítási erőforrások, amelyek rendelkeznek CPU-val, RAM-mal és merevlemez-területtel. A két vagy több csomópontot tartalmazó fürt egy leader csomópontból és számítási csomópontokból áll.
a Leader csomópontok kommunikálnak az ügyfélprogramokkal, és lefordítják a kódot a lekérdezések végrehajtásához, hozzárendelve a csomópontok kiszámításához. A számítási csomópontok futtatják a lekérdezéseket, és az eredményeket visszaadják a leader csomópontnak. A számítási csomópont csak olyan lekérdezéseket hajt végre, amelyek az adott csomóponton tárolt táblákra hivatkoznak.
partíciók/szeletek
az Amazon minden számítási csomópontot szeletekre választ fel. A slice megkapja a csomópont memóriájának és lemezterületének elosztását. Több szelet párhuzamosan működik a lekérdezés végrehajtási idejének felgyorsítása érdekében.
oszlopos Tárolás
a Redshift oszlopos tárolást használ, amely jobb analitikai lekérdezési teljesítményt tesz lehetővé. Ahelyett, hogy rekordokat sorokban tárolna, egyetlen oszlop értékeit tárolja több sorhoz. A következő ábrák ezt világosabbá teszik:
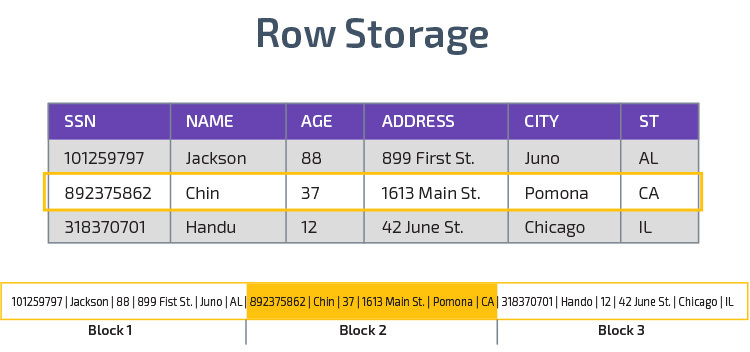
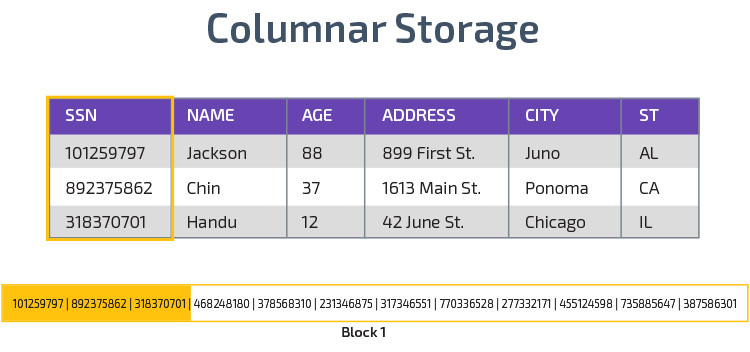
az oszlopos tárolás lehetővé teszi az adatok gyorsabb olvasását, ami elengedhetetlen az adathalmaz sok oszlopát lefedő analitikai lekérdezésekhez. Az oszlopos Tárolás kevesebb lemezterületet is igénybe vesz, mivel minden blokk azonos típusú adatokat tartalmaz, vagyis tömöríthető egy adott formátumba.
tömörítés
a tömörítés csökkenti a tárolt adatok méretét. Vöröseltolódás esetén az adatok tárolásának módja miatt a tömörítés az oszlop szintjén történik. A Redshift lehetővé teszi az információk kézi tömörítését táblázat létrehozásakor, vagy automatikusan a másolás parancs használatával.
Adattöltés
a Redshift másolási parancsával nagy mennyiségű adatot tölthet be az adattárházba. A COPY parancs kihasználja a Redshift MPP architektúráját az adatok párhuzamos olvasására és betöltésére az Amazon S3 fájljaiból, egy DynamoDB táblából vagy egy vagy több távoli gazdagép szöveges kimenetéből.
az Amazon Kinesis Firehose szolgáltatás segítségével az adatok vöröseltolódásba is továbbíthatók.
Cloud Database Warehouse – Google BigQuery
a következő fogalmakat kifejezetten használják a Google BigQuery cloud data warehouse-ban, de a jövőben további, a Google infrastruktúráján alapuló megoldásokra is vonatkozhatnak.
szerver nélküli szolgáltatás
a BigQuery szerver nélküli architektúrát használ. A BigQuery segítségével a vállalkozásoknak nem kell fizikai szerveregységeket kezelniük az adattárházak futtatásához. Ehelyett a BigQuery dinamikusan kezeli számítási erőforrásainak elosztását. A szolgáltatást használó vállalkozások egyszerűen fizetnek az adattárolásért gigabájtonként, a lekérdezésekért pedig terabájtonként.
Colossus fájlrendszer
a BigQuery a Google elosztott fájlrendszerének legújabb verzióját használja, a Colossus kódnevet. A Colossus fájlrendszer oszlopos tárolási és tömörítési algoritmusokat használ az adatok elemzési célokra történő optimális tárolására.
Dremel végrehajtó Motor
a Dremel végrehajtó motor oszlopos elrendezést használ a hatalmas adattárak gyors lekérdezéséhez. A Dremel végrehajtó motorja másodpercek alatt képes ad-hoc lekérdezéseket futtatni sorok milliárdjain, mert masszívan párhuzamos feldolgozást használ fa architektúra formájában.
a faarchitektúra a lekérdezéseket egy gyökérkiszolgáló több köztes kiszolgálója között osztja el. A köztes kiszolgálók a lekérdezést a (tárolt adatokat tartalmazó) levélszerverekre tolják, amelyek párhuzamosan szkennelik az adatokat. A fa felé vezető úton minden levélkiszolgáló lekérdezési eredményeket küld, a közbenső kiszolgálók pedig a részeredmények párhuzamos összesítését hajtják végre.
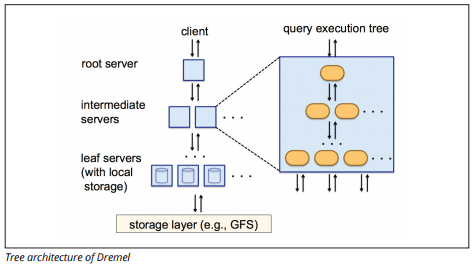
Image source
a Dremel lehetővé teszi a szervezetek számára, hogy egyszerre több tízezer szerveren futtassanak lekérdezéseket. A Google szerint a Dremel tíz másodperc alatt index nélkül 35 milliárd sort képes beolvasni.
adatmegosztás
a Google BigQuery szerver nélküli architektúrája lehetővé teszi a vállalatok számára, hogy egyszerűen megosszák az adatokat más szervezetekkel anélkül, hogy ezeknek a szervezeteknek befektetniük kellene a saját tárhelyükbe.
a megosztott adatokat lekérdezni kívánó szervezetek ezt megtehetik, és csak a lekérdezésekért fizetnek. Nincs szükség költséges megosztott adat silók létrehozására, a szervezet adatinfrastruktúráján kívül, és az adatok másolására ezekre a silókra.
Streaming és Batch Lenyelés
lehetőség van adatok betöltésére a BigQuery-be a Google Cloud Storage-ból, beleértve a CSV, JSON (newline-delimited) és Avro fájlokat, valamint a Google Cloud Datastore biztonsági mentéseit. Az adatokat közvetlenül olvasható adatforrásból is betöltheti.
a BigQuery egy Streaming API-t is kínál az adatok betöltésére másodpercenként több millió sor sebességgel terhelés nélkül. Az adatok szinte azonnal rendelkezésre állnak elemzésre.
Cloud Data Warehouse Concepts – Panoply
Panoply egy all-in-one raktár, amely egyesíti ETL egy erős adattárház. Ez a legegyszerűbb módja a vállalat adatainak szinkronizálásának, tárolásának és elérésének azáltal, hogy megszünteti a big data átalakításával, integrálásával és kezelésével kapcsolatos fejlesztést és kódolást.
az alábbiakban bemutatjuk a Panoply adattárház néhány fő koncepcióját az adatmodellezéssel és az adatvédelemmel kapcsolatban.
elsődleges kulcsok
az elsődleges kulcsok biztosítják, hogy a táblázatok minden sora egyedi legyen. Minden táblának van egy vagy több elsődleges kulcsa, amelyek meghatározzák, hogy mi képviseli az adatbázis egyetlen egyedi sorát. Minden API-nak van alapértelmezett elsődleges kulcsa a táblákhoz.
növekményes kulcsok
a Panoply egy növekményes kulcsot használ az attribútumok vezérléséhez az adatok fokozatos betöltéséhez az adattárházba a forrásokból, ahelyett, hogy minden alkalommal újratöltené a teljes adatkészletet, amikor valami megváltozik. Ez a funkció nagyobb adatkészletek esetén hasznos, amelyek többnyire változatlan adatok olvasása hosszú időt vehet igénybe. Az inkrementális kulcs az adatforrás sorainak utolsó frissítési pontját jelzi.
beágyazott adatok
a beágyazott adatok nem teljesen kompatibilisek a BI—csomagokkal és a szabványos SQL-lekérdezésekkel-a Panoply a beágyazott adatokkal erősen relációs modellt használ, amely nem engedélyezi a beágyazott értékeket. A Panoply a beágyazott adatokat a következő módon alakítja át:
- Altáblák: alapértelmezés szerint a Panoply a beágyazott adatokat sok-sok vagy egy-sok kapcsolattáblák halmazává alakítja, amelyek lapos relációs táblák.
- egyengetés: ha ez a mód engedélyezve van, a Panoply egyengeti a beágyazott struktúrát az azt tartalmazó rekordra.
Előzménytáblák
néha elemeznie kell az adatokat az adatok időbeli változásának nyomon követésével, hogy pontosan lássa, hogyan változnak az adatok (például az emberek címei).
az ilyen elemzések elvégzéséhez a Panoply Előzménytáblákat használ, amelyek idősoros táblák, amelyek az eredeti statikus táblázat minden sorának történelmi pillanatképeit tartalmazzák. Ezután egyszerű lekérdezést hajthat végre az eredeti tábláról vagy a táblázat módosításairól, ha visszatekeri az időpontot.
transzformációk
a Panoply az ELT-t használja, amely az eredeti ETL adatintegrációs folyamat változata. Miután beadta az adatokat a forrásból az adattárházba, a Panoply azonnal átalakítja azokat. Ez a folyamat valós idejű adatelemzést és optimális teljesítményt nyújt a standard ETL folyamathoz képest.
Karakterláncformátumok
a Panoply elemzi a karakterláncformátumokat, és úgy kezeli őket, mintha beágyazott objektumok lennének az eredeti adatokban. A támogatott karakterláncformátumok a CSV, TSV, JSON, JSON-Line, Ruby objektumformátum, URL lekérdezési karakterláncok és webes terjesztési naplók.
Adatvédelem
a Panoply az AWS tetejére épül, így rendelkezik az AWS által biztosított legújabb biztonsági javításokkal és titkosítási képességekkel, beleértve a hardveresen gyorsított RSA titkosítást és az Amazon Redshift speciális biztonsági funkcióit.
az extra védelem az oszlopos titkosításból származik, amely lehetővé teszi a panoply szerverein nem tárolt privát kulcsok használatát.
hozzáférés-vezérlés
a Panoply kétlépcsős ellenőrzést használ a jogosulatlan hozzáférés megakadályozására, az engedélyrendszer pedig lehetővé teszi, hogy korlátozza a hozzáférést bizonyos táblákhoz, nézetekhez vagy oszlopokhoz. Az anomáliadetektálás azonosítja az új számítógépekről vagy egy másik országból érkező lekérdezéseket, lehetővé téve, hogy blokkolja ezeket a lekérdezéseket, hacsak nem kapnak kézi jóváhagyást.
IP Engedélyezőlista
javasoljuk, hogy tűzfal vagy AWS biztonsági csoport használatával blokkolja a fel nem ismert forrásokból származó kapcsolatokat, és engedélyezze azoknak az IP-címeknek a listáját, amelyeket a Panoply adatforrásai mindig használnak az adatbázis elérésekor.
következtetés: hagyományos vs.adattárház fogalmak röviden
a lezáráshoz összefoglaljuk a dokumentumban bevezetett fogalmakat.
hagyományos adattárház fogalmak
- tények és intézkedések: a mérték olyan tulajdonság, amelyen számításokat lehet végezni. Az intézkedések gyűjteményére tényként hivatkozunk, de néha a kifejezéseket felcserélhetően használják.
- normalizálás: az ismétlődő adatok mennyiségének csökkentése, ami egy memória-hatékonyabb adattárházhoz vezet, amelyet lassabban lehet lekérdezni.
- dimenzió: a tények és intézkedések kategorizálására és kontextualizálására szolgál, lehetővé téve ezen intézkedések elemzését és jelentését.
- fogalmi adatmodell: meghatározza a kritikus magas szintű adat entitásokat és a köztük lévő kapcsolatokat.
- logikai adatmodell: Az adatkapcsolatokat, entitásokat és attribútumokat egyszerű angol nyelven írja le, anélkül, hogy aggódna a kódban történő megvalósítás miatt.
- fizikai adatmodell: az adattervezés megvalósításának ábrázolása egy adott adatbázis-kezelő rendszerben.
- Csillagséma: egy ténytáblát vesz fel, és annak információit denormalizált dimenziótáblákra osztja.
- hópehely séma: a ténytáblát normalizált dimenziós táblákra osztja. A normalizálás csökkenti az adatok redundanciájával kapcsolatos problémákat és javítja az adatok integritását, de a lekérdezések összetettebbek.
- OLTP: Az Online tranzakciófeldolgozó rendszerek megkönnyítik a gyors, tranzakció-orientált feldolgozást egyszerű lekérdezésekkel.
- OLAP: az online analitikai feldolgozás lehetővé teszi összetett olvasási lekérdezések futtatását,és így a múltbeli tranzakciós adatok részletes elemzését.
- Data mart: egy adott témára vagy szervezeti egységre összpontosító adatok archívuma.
- Inmon megközelítés: Bill Inmon adattárház megközelítése az adattárházat a teljes vállalkozás központi adattáraként határozza meg. A Data marts az adattárházból építhető, hogy kiszolgálja a különböző osztályok analitikai igényeit.
- Kimball megközelítés: Ralph Kimball az adattárházat a küldetés szempontjából kritikus adatpiacok egyesítéseként írja le, amelyeket először a különböző osztályok elemzési igényeinek kielégítésére hoztak létre.
- ETL: integrálja az adatokat az adattárházba azáltal, hogy kivonja azokat különböző tranzakciós forrásokból, átalakítja az adatokat, hogy optimalizálja az elemzéshez, majd végül betölti az adattárházba.
- ELT: Az ETL olyan változata, amely nyers adatokat nyer ki a szervezet adatforrásaiból, és betölti azokat az adattárházba. Ha szükséges, analitikai célokra átalakul.
- vállalati adattárház: az EDW konszolidálja a vállalkozáshoz kapcsolódó összes tárgyterület adatait.
Cloud Data Warehouse Concepts – Amazon Redshift példaként
- Klaszter: a felhőben található megosztott számítási erőforrások csoportja.
- csomópont: egy fürtben található számítási erőforrás. Minden csomópont saját CPU-val, RAM-mal és merevlemez-területtel rendelkezik.
- oszlopos Tárolás: Ez a táblázat értékeit oszlopokban, nem pedig sorokban tárolja, ami optimalizálja az összesített lekérdezések adatait.
- tömörítés: technikák a tárolt adatok méretének csökkentésére.
- Adattöltés: adatok beszerzése forrásokból a felhőalapú adattárházba. A Redshift alkalmazásban használhatja a Másolás parancsot vagy egy adatfolyam-szolgáltatást.
Cloud Data Warehouse Concepts – BigQuery példaként
- szerver nélküli szolgáltatás: a felhőszolgáltató dinamikusan kezeli a gépi erőforrások elosztását a felhasználó által felhasznált mennyiség alapján. A felhőszolgáltató elrejti a kiszolgálókezelési és kapacitástervezési döntéseket a szolgáltatás felhasználói elől.
- Colossus fájlrendszer: elosztott fájlrendszer, amely oszlopos tárolási és adattömörítési algoritmusokat használ az adatok elemzéséhez.
- Dremel execution engine: olyan lekérdező motor, amely nagymértékben párhuzamos feldolgozást és oszlopos tárolást használ a lekérdezések gyors végrehajtásához.
- adatmegosztás: egy szerver nélküli szolgáltatásban célszerű lekérdezni egy másik szervezet megosztott adatait anélkül, hogy az adattárolóba fektetne—egyszerűen fizet a lekérdezésekért.
- adatfolyam: adatok valós idejű beszúrása az adattárházba terhelés nélkül. Az adatokat kötegelt kérésekben is továbbíthatja, amelyek több API-hívás egy HTTP-kérésbe egyesítve.
hagyományos vs. felhő költség-haszon elemzés
| költség / haszon | hagyományos | felhő |
| költség | nagy előzetes költség az on-prem rendszer megvásárlásához és telepítéséhez. hardverre, szerverszobákra és speciális személyzetre van szüksége (amelyeket folyamatosan fizet). ha nem biztos abban, hogy mennyi tárhelyre van szüksége, fennáll a magas elsüllyedt költségek kockázata, amelyeket nehéz megtéríteni. |
nem kell vásárolni hardver, szerver szoba, vagy felvenni szakemberek. nincs kockázat az elsüllyedt költségek – vásárol több tároló a jövőben könnyű. ráadásul a tárolási költségek és a számítási teljesítmény idővel csökken. |
| méretezhetőség | miután maximalizálta a jelenlegi szerverszobákat vagy hardverkapacitást, előfordulhat, hogy új hardvert kell vásárolnia, és több helyet kell építenie/vásárolnia annak elhelyezéséhez. Plusz, meg kell vásárolni elég tároló megbirkózni csúcsidőben; így az idő nagy részében a tárhely nagy részét nem használják. |
könnyedén vásárolhat több tárhelyet, amikor és amikor szüksége van rá. gyakran csak fizetnie kell azért, amit használ, így kevés vagy egyáltalán nem áll fenn a túlfizetés kockázata. |
| integrációk | mivel a felhőalapú számítástechnika a norma, a legtöbb integrációt felhőalapú szolgáltatásokra kívánja végrehajtani. az egyéni adattárház hozzájuk való csatlakoztatása kihívást jelenthet. |
mivel a felhőalapú adattárházak már a felhőben vannak, a többi felhőszolgáltatáshoz való csatlakozás egyszerű. |
| biztonság | az adattárház teljes ellenőrzése alatt áll. ha összehasonlítjuk az Amazon vagy a Google által tárolt adatmennyiséget, akkor kisebb a tolvajok célpontja. Így, nagyobb valószínűséggel marad egyedül. |
a Cloud data warehouse szolgáltatóknak magasan képzett biztonsági mérnökökből álló csapataik vannak, akiknek egyetlen célja, hogy terméküket a lehető legbiztonságosabbá tegyék. a világ legkiemelkedőbb vállalatai kezelik ezeket, és ezért világszínvonalú biztonsági gyakorlatokat alkalmaznak. |
| irányítás | pontosan tudja, hol vannak az adatai, és helyben is hozzáférhet hozzájuk. kisebb a kockázata annak, hogy a rendkívül érzékeny adatok véletlenül megsértik a törvényt, például felhőszerveren utazva a világot. |
a felhőalapú adattárházak vezető szolgáltatói biztosítják, hogy megfelelnek az irányítási és biztonsági törvényeknek, például a GDPR-nak. Plusz, segítenek vállalkozásának abban, hogy megfeleljen. problémák merültek fel azzal kapcsolatban, hogy pontosan tudjuk-e az adatait, és hol mozog. Ezeket a problémákat aktívan kezelik és megoldják. vegye figyelembe, hogy hatalmas mennyiségű, rendkívül érzékeny adat tárolása a felhőben ellentétes lehet bizonyos törvényekkel. Ez egy olyan eset, amikor a felhőalapú számítástechnika nem megfelelő az Ön vállalkozása számára. |
| megbízhatóság | ha az on-prem adattárház meghibásodik, az Ön felelőssége kijavítani. az informatikai csapat hozzáférhet a fizikai hardverhez, és minden szoftverréteghez hozzáférhet a hibaelhárításhoz. Ez a gyors hozzáférés sokkal gyorsabbá teheti a problémák megoldását. azonban nincs garancia arra, hogy a raktárának évente meghatározott mennyiségű üzemideje lesz. |
a Cloud data warehouse szolgáltatók garantálják megbízhatóságukat és üzemidejüket SLA-Jaikban. tömegesen elosztott rendszereken működnek az egész világon, így ha az egyik meghibásodik, akkor nagyon valószínűtlen, hogy befolyásolja Önt. |
| Control | az adattárház egyedi felépítésű, hogy megfeleljen az Ön igényeinek. Elméletileg azt teszi, amit akarsz, amikor akarod, olyan módon, amit megértesz. | nincs teljes ellenőrzése az adattárház felett. azonban az idő nagy részében a kontroll több mint elég. |
| sebesség | ha Ön egy földrajzi helyen lévő kis vállalat, kis mennyiségű adattal, az adatfeldolgozás gyorsabb lesz. azonban milliszekundum vs. másodperc néhány folyamat befejezéséhez. egy több országban működő nagyvállalat valószínűleg nem fog jelentős sebességnövekedést elérni egy on-prem rendszerrel. |
a felhőszolgáltatók olyan rendszerekbe fektettek be és hoztak létre, amelyek tömeges párhuzamos feldolgozást (MPP), egyedi architektúrájú és végrehajtó motorokat, valamint intelligens adatfeldolgozó algoritmusokat valósítanak meg. a felhőalapú adattárházak több éves kutatás és tesztelés eredménye, melynek célja a sebességre és teljesítményre optimalizált erőforrások létrehozása. bizonyos esetekben kissé lassabb lehet, mint az on-prem, de ezek a késések gyakran elhanyagolhatóak az emberek számára (másodperc vs.milliszekundum). |
a Panoply biztonságos hely az üzleti adatok tárolására, szinkronizálására és elérésére. A Panoply percek alatt beállítható, nulla folyamatos karbantartást igényel, és online támogatást nyújt, beleértve a tapasztalt adatépítészek hozzáférését. Próbálja ki a Panoply free alkalmazást 14 napig.
Tudjon meg többet az Adattárházakról
- adattárház architektúra: hagyományos vs. felhő
- Adatbázis vs. adattárház
- adattárház vs. adattárház