Common Search: a nyílt forráskódú projekt visszahozza a Pagerankot
iratkozzon fel a folyamatosan változó keresési marketing táj napi összefoglalóira.
Megjegyzés: Az űrlap elküldésével elfogadja a Third Door Media feltételeit. Tiszteletben tartjuk a magánéletét.

az elmúlt néhány évben a Google lassan csökkentette a SEO szakemberek számára elérhető adatok mennyiségét. Először kulcsszóadatok voltak, majd PageRank pontszám. Most ez az AdWords adott keresési mennyisége (hacsak nem költ némi moola-t). Erről többet olvashat Russ Jones kiváló cikkében, amely részletezi cége kutatásának hatását és betekintést nyújt a kattintási adatokba a kötet pontosításához.
az egyik elem, amelyben a közelmúltban valóban részt vettünk, a közös feltérképezési adatok. Iparágunkban több csapat is használja ezeket az adatokat egy ideje, így kissé későn éreztem magam a játékban. A Common Crawl data egy nyílt forráskódú projekt, amely rendszeres időközönként lekaparja az egész internetet. Szerencsére, Amazon, hogy a nagy cég ez, hangú, hogy tárolja az adatokat, hogy azok sokak számára elérhetővé anélkül, hogy a magas tárolási költségek.
a közös feltérképezési adatok mellett létezik egy Common Search nevű nonprofit szervezet is, amelynek feladata egy alternatív nyílt forráskódú és átlátható keresőmotor létrehozása-sok szempontból a Google ellentéte. Ez felkeltette az érdeklődésemet, mert ez azt jelenti, hogy mindannyian játszhatunk, csíphetünk és megcsíphetjük a jeleket, hogy megtanuljuk, hogyan működnek a keresőmotorok anélkül, hogy hatalmas időbefektetés lenne a ground zero-ból kiindulva.
közös keresési adatok
jelenleg a közös Keresés a következő adatforrásokat használja a keresési rangsor kiszámításához (ez közvetlenül a weboldalukról származik):
- közös feltérképezés: a webes feltérképezési adatok legnagyobb nyitott tárháza. Ez jelenleg a nyers oldaladatok egyedülálló forrása.
- Wikidata: Egy ingyenes, összekapcsolt adatbázis, amely számos Wikimédia-projekt, például a Wikipédia, a Wikivoyage és a Wikiforrás strukturált adatainak központi tárolójaként működik.
- UT1 Feketelista: Fabrice Prigent, a Toulouse 1 Capitole Egyetem munkatársa tartja fenn, ez a feketelista a domaineket és URL-eket több kategóriába sorolja, beleértve a “felnőtt” és az “adathalászat” kategóriákat.”
- DMOZ: más néven Az Open Directory Project, ez a legrégebbi és legnagyobb web könyvtár még mindig él. Bár az adatok nem olyan megbízhatóak, mint a múltban, még mindig jel-és metaadatforrásként használjuk őket.
- Web Data Commons Hyperlink Graphs: az összes hiperhivatkozás grafikonja egy 2012-es közös feltérképezési archívumból. Jelenleg a harmonikus központi fájlját ideiglenes rangsorolási jelként használjuk a domaineken. A közeljövőben tervezzük a webes grafikon saját elemzését.
- Alexa top 1M webhelyek: az Alexa rangsorolja a webhelyeket az oldalmegtekintések és az egyedi webhely-felhasználók együttes mérése alapján. Ismert, hogy demográfiai szempontból elfogult. Ideiglenes rangsorolási jelként használjuk a domaineken.
Common Search ranking
ezen adatforrások mellett a kód vizsgálatakor az URL hosszát, az elérési út hosszát és a domain pagerankot is rangsorolási jelként használja algoritmusában. Íme, július óta a Common Search saját adatokkal rendelkezik a gazdagép szintű PageRank-on, és mindannyian hiányoltuk.
egy pillanat alatt eljutok a PageRank (PR) – hez, de érdekes áttekinteni a közös feltérképezés kódját, különösen a rankert.py rész itt található, mert valóban bejuthat a vezetőülésbe az oldalak rangsorolásához használt jelek súlyának módosításával:
signal_weights = {"url_total_length": 0.01,"url_path_length": 0.01,"url_subdomain": 0.1,"alexa_top1m": 5,"wikidata_url": 3,"dmoz_domain": 1,"dmoz_url": 1,"webdatacommons_hc": 1,"commonsearch_host_pagerank": 1}
különös figyelmet érdemel az is, hogy a Common Search a BM25-öt használja a kulcsszó hasonlóságának mértékeként a test és a metaadatok dokumentálásához. A BM25 jobb intézkedés, mint a TF-IDF, mert figyelembe veszi a dokumentum hosszát, vagyis egy 200 szavas dokumentum, amely ötször tartalmazza a kulcsszót, valószínűleg relevánsabb, mint egy 1500 szavas dokumentum, amely ugyanannyi alkalommal rendelkezik.
azt is érdemes megemlíteni, hogy a jelek száma itt nagyon kezdetleges, és nyilvánvalóan hiányzik sok finomítás (és adat), amelyet a Google beépített a keresési rangsorolási algoritmusába. Az egyik legfontosabb dolog, amin dolgozunk, az, hogy a közös feltérképezésben rendelkezésre álló adatokat és a közös keresés infrastruktúráját használjuk a témavektor keresésére a szemantika alapján releváns tartalomhoz, nem csak a kulcsszóillesztéshez.
on to PageRank
itt az oldalon a 2016.júniusi Általános feltérképezés gazdagépszintű Pagerankjára mutató linkeket talál. A jogosultat használom pagerank-top1m.txt.gz (top 1 millió), mert a másik fájl 3GB és több mint 112 millió domain. Még R, nincs elég gép betölteni anélkül, hogy lezárja.
a letöltés után be kell vinnie a fájlt a munkakönyvtárba az R-ben. A közös Keresés a “max(0, min(1, float(rang) / 244660.58)) ” — alapvetően egy domain rangja osztva a Facebook rangjával-mint az adatok 0 és 1 közötti eloszlásra történő fordításának módszere. De ez bizonyos határozott hiányosságokat hagy maga után, mivel ez a Linkedin PageRank-jét 1.4-ként hagyja el, ha 10-re méretezik.

a következő kód betölti az adatkészletet, és hozzáfűz egy PR oszlopot egy közelítőbb PR-vel:
#Grab the datadf <- read.csv("pagerank-top1m.txt", header = F, sep = " ")#Log NormalizelogNorm <- function(x){ #Normalize x <- (x-min(x))/(max(x)-min(x)) 10 / (1 - (log10(x)*.25))}#Append a Column named PR to the datasetdf$pr <- (round(logNorm(df$V2),digits = 0))
kicsit játszanunk kellett a számokkal, hogy valahol közel kerüljünk (több domainmintához, amelyekre emlékeztem a PR-re) a régi Google PR-hez. Az alábbiakban néhány példa PageRank eredmények:
- en.wikipedia.org (8)
- searchengineland.com (6)
- consultwebs.com (5)
- youtube.com (9)
- moz.com (6)
itt van egy 100 000 véletlenszerű minta. A számított PageRank pontszám az Y tengely mentén, az eredeti közös Keresési pontszám pedig az X tengely mentén van.
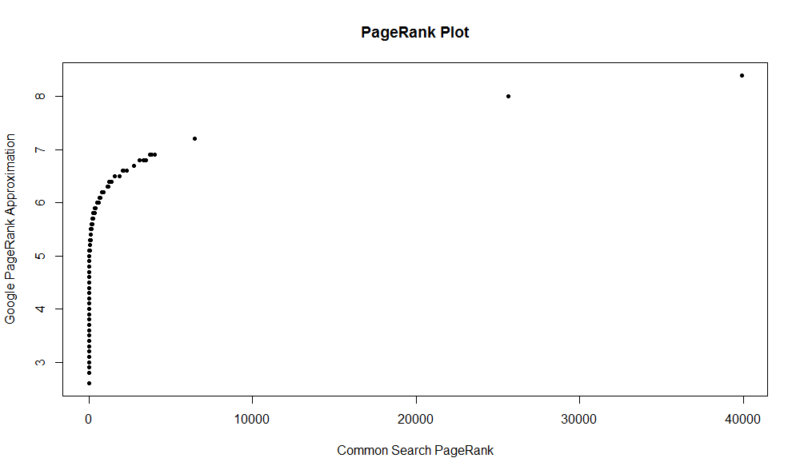
a saját eredmények megragadásához futtathatja a következő parancsot az R-ben (csak cserélje ki a saját domainjét):
df

ne feledje, hogy ennek az adatkészletnek csak a PageRank egymillió domainje van, így a 112 millió domainből, amelyet a közös keresés indexelt, jó esély van arra, hogy webhelye nem lesz ott, ha nincs elég jó linkprofilja. Ez a mutató nem tartalmazza a linkek káros hatását, csak a webhely népszerűségének közelítését a linkek tekintetében.
a közös keresés nagyszerű eszköz és nagyszerű alap. Alig várom, hogy jobban bekapcsolódjak az ottani közösségbe, és remélhetőleg megtanulom jobban megérteni a keresőmotorok mögötti anyákat és csavarokat azáltal, hogy ténylegesen dolgozom rajta. Az R és egy kis kód segítségével gyorsan ellenőrizheti a PR-t egy millió domainre másodpercek alatt. Remélem tetszett!
iratkozzon fel a folyamatosan változó keresési marketing táj napi összefoglalóira.
Megjegyzés: Az űrlap elküldésével elfogadja a Third Door Media feltételeit. Tiszteletben tartjuk a magánéletét.
A szerzőről

JR Oakes a Locomotive MŰSZAKI SEO kutatásának vezető igazgatója. Korábban az Adapt Partners ügynökség műszaki SEO igazgatója volt. Számos fronton dolgozik az ügyfelekkel, beleértve a technikai kérdéseket, a teljesítményt, a CTR-t, a feltérképezési képességet, a tartalmat és az adatelemzést. JR szereti a tesztelést, kódolást és prototípus-megoldásokat a nehéz keresési marketing problémákra. Amikor nem dolgozik, szívesen olvas a feltörekvő technológiákról, basszusgitározik, egyetemi kosárlabdát néz, szakácskodik, és időt tölt a barátaival és családjával. Ő is az egyik társszervezője a Raleigh SEO Meetup, Raleigh SEO konferencia, RTP SEO Meetup.