skálázható, elosztott másodlagos indexelés a Scylla – ban

a Scylla és az Apache Cassandra adatmodellje partíciókulccsal osztja meg az adatokat a klasztercsomópontok között, amelyet az adatbázis séma határoz meg. A partíciós kulcs használata hatékony módja a sorok megkeresésének a partíciós kulcs segítségével, mivel a partíciós kulcs kivonatolásával megtalálhatja a sort birtokló csomópontot. Sajnos ez azt is jelenti, hogy egy sor nem partíciós kulcs használatával történő megkereséséhez teljes táblázatos vizsgálat szükséges, amely nem hatékony. A másodlagos indexek egy olyan mechanizmus az Apache Cassandra-ban, amely lehetővé teszi a nem partíciós kulcsok hatékony keresését index létrehozásával.
ebben a blogbejegyzésben megtudhatja:
- hogyan valósítja meg az Apache Cassandra a másodlagos indexeket a helyi indexelés segítségével
- miért döntöttünk úgy, hogy a Scylla számára más végrehajtási stratégiát alkalmazunk a globális indexelés használatával
- hogyan befolyásolja a globális indexelés hogyan kell használni a másodlagos indexelést
- Hogyan hozzunk létre saját másodlagos indexeket és használjuk őket az alkalmazás CQL lekérdezéseiben
háttér
az index mérete arányos az indexelt adatok méretével. Mivel a Scylla és az Apache Cassandra adatai több csomópontra vannak elosztva, nem célszerű a teljes indexet egyetlen csomóponton tárolni. Az Apache Cassandra a másodlagos indexeket helyi indexekként valósítja meg, ami azt jelenti, hogy az index ugyanazon a csomóponton tárolódik, mint az adott csomópontból indexelt adatok. A helyi index előnye, hogy az írások nagyon gyorsak, de hátránya, hogy az olvasásoknak potenciálisan lekérdezniük kell minden csomópontot, hogy megtalálják az indexet, amelyen keresést végezhetnek, ami a helyi indexeket nagy klaszterek számára nem minősíthetővé teszi. A natív másodlagos indexek mellett az Apache Cassandra rendelkezik egy másik helyi indexelési sémával is, az sstable Attached Secondary Index (SASI), amely támogatja az összetett lekérdezéseket és a keresést. Skálázhatóság szempontjából azonban pontosan ugyanazokkal a jellemzőkkel rendelkezik, mint az eredeti másodlagos indexek.
a Scylla és az Apache Cassandra materializált nézetei egy olyan mechanizmus, amely automatikusan denormalizálja az adatokat egy alaptáblából egy nézettáblába egy másik partíciós kulcs segítségével. Ez megoldja a helyi indexek skálázhatósági problémáját, de tárolási költséggel jár, mert a legrosszabb esetben az egész táblát meg kell másolnia. A materializált nézetek tehát nem helyettesítik a másodlagos indexeket minden felhasználási esetben. A materializált nézetek azonban biztosítják a szükséges infrastruktúrát a másodlagos indexek globális indexeléssel történő megvalósításához, amely a Scylla végrehajtási megközelítése.
globális indexelés
a Scylla más megközelítést alkalmaz, mint az Apache Cassandra, és másodlagos indexeket valósít meg Globális indexeléssel. A globális indexeléssel minden indexhez létrejön egy materializált nézet. A materializált nézetben az indexelt oszlop a partíciós kulcs, az indexelt sor elsődleges kulcsa (partíciós kulcs és fürtözési kulcsok) pedig fürtözési kulcsként szerepel. A Scylla két részre bontja az indexelt lekérdezéseket: (1) az indextáblán található lekérdezés az indexelt tábla partíciós kulcsainak lekérésére, valamint (2) az indexelt tábla lekérdezése a lekért partíciós kulcsok segítségével. Ennek a megközelítésnek az az előnye, hogy az indexelt oszlop értékét felhasználhatjuk a fürt megfelelő indextábla sorának megkeresésére, így az olvasások skálázhatók. A megközelítés hátránya, hogy az írások lassabbak, mint a helyi indexelésnél, mivel az indexnézet naprakészen tartásának minden költsége miatt.
az indexelt oszlop lekérdezése a következőképpen néz ki. Tegyük fel, hogy egy asztal így néz ki:
és egy lekérdezés a email oszlopban, amely nem partíciós kulcs, hanem index:
az (1) fázisban a lekérdezés a 7.csomópontra érkezik, amely a lekérdezés koordinátoraként működik. A csomópont észreveszi, hogy egy indexelt oszlopon kérdezünk, ezért a (2) fázisban kiad egy olvasási index táblát a 2.csomóponton, amelynek indextáblája a””. A lekérdezés egy olyan felhasználói Azonosítókészletet ad vissza, amelyet a (3) fázisban használnak az indexelt tábla tartalmának lekérésére.
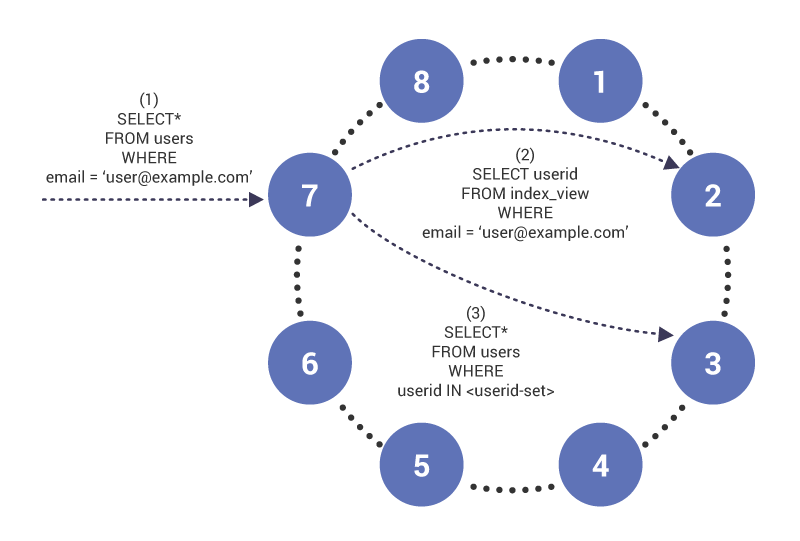
példa
először létre kell hoznunk egy sémát. Ebben a példában van egy táblázatunk, amely a felhasználói információkat ábrázolja, a UserID mint partíciós kulcs, a név, az e-mail és az ország pedig rendszeres oszlopként:
ezután feltöltjük a táblázatot néhány, a Mockaroo-val generált tesztadattal:
a másodlagos indexeket úgy tervezték, hogy lehetővé tegyék a nem partíciós kulcs oszlopok hatékony lekérdezését. Míg az Apache Cassandra támogatja a nem partíciós kulcsoszlopok lekérdezéseit a ALLOW FILTERING használatával, ez nagyon nem hatékony (a teljes táblázat beolvasását igényli), és jelenleg a Scylla nem támogatja (lásd a 2200.számot a részletekért).
a táblázat oszlopait indexelheti az INDEX létrehozása utasítás segítségével. Ha például indexeket szeretne létrehozni az e-mailekhez és az országoszlopokhoz, hajtsa végre a következő CQL utasításokat:
a Scylla automatikusan létrehoz egy materializált nézetet, amely az indexelt oszlopot tartalmazza partíciós kulcsként, a céltábla elsődleges kulcsát (partíciós kulcs és fürtkulcs) pedig fürtkulcsként.
például a email oszlop indexének materializált nézete a következőképpen néz ki:
ha a fenti nézetet normál táblázatként hoznánk létre, akkor gyakorlatilag a következőképpen nézne ki:
a email oszlopot használják az indextábla partíciós kulcsaként, a useridpedig fürtözési kulcsként, amely lehetővé teszi számunkra, hogy hatékonyan megtaláljuk a céltábla partíciós kulcsait csak email használatával.
a DESCRIBE paranccsal megtekintheti a ks.users tábla teljes sémáját, beleértve a létrehozott indexeket és nézeteket is:
most, hogy a másodlagos Index a helyén van, lekérdezheti az indexelt oszlopokat, mintha partíciós kulcsok lennének:
végeztünk a példával!
mikor kell másodlagos indexeket használni?
a másodlagos indexek (többnyire) átláthatóak az alkalmazás számára. A lekérdezések hozzáférhetnek a táblázat összes oszlopához, és az alkalmazás módosítása nélkül hozzáadhat és eltávolíthat indexeket. A másodlagos indexek is kevesebb tárhellyel rendelkeznek, mint a materializált nézetek, mert a másodlagos indexeknek csak az indexelt oszlopot és az elsődleges kulcsot kell másolniuk, nem pedig a lekérdezett oszlopokat, mint a materializált nézetnél. Továbbá ugyanezen okból a frissítések hatékonyabbak lehetnek a másodlagos indexeknél, mivel csak az elsődleges kulcs és az indexelt oszlop változásai okoznak frissítést az index nézetben. Materializált nézet esetén a nézetben megjelenő oszlopok frissítéséhez frissíteni kell a háttérnézetet.
mint mindig, a másodlagos indexek vagy a materializált nézetek használatának döntése valóban az alkalmazás követelményeitől függ. Ha maximális teljesítményre van szüksége, és valószínűleg egy adott oszlopkészletet szeretne lekérdezni, akkor materializált nézeteket kell használnia. Ha azonban az alkalmazásnak különböző oszlopkészleteket kell lekérdeznie, a másodlagos indexek jobb választás, mivel az alkalmazás igényeitől függően kevesebb tárolási költséggel adhatók hozzá és távolíthatók el.
szeretne többet megtudni a másodlagos indexekről? Nézd meg a bemutatót Scylla Summit 2017 a SlideShare. Ha ki akarja próbálni ezt a funkciót, akkor várhatóan a közelgő Scylla 2.2 kiadásban lesz.