Cloud Data Warehouse vs Traditional Data Warehouse Concepts
Cloud-based data warehouse sono la nuova norma. Sono finiti i giorni in cui la tua azienda doveva acquistare hardware, creare sale server e assumere, addestrare e mantenere un team dedicato di personale per eseguirlo. Ora, con pochi clic sul tuo laptop e una carta di credito, puoi accedere a potenza di calcolo e spazio di archiviazione praticamente illimitati.
Tuttavia, questo non significa che le idee tradizionali di data warehouse siano morte. La teoria classica del data warehouse è alla base della maggior parte di ciò che fanno i data warehouse basati su cloud.
In questo articolo, spiegheremo i concetti tradizionali di data warehouse che devi conoscere e quelli cloud più importanti da una selezione dei migliori fornitori: Amazon, Google e Panoply. Infine, concluderemo con un’analisi costi-benefici dei data warehouse tradizionali rispetto al cloud, in modo da sapere quale è giusto per te.
Iniziamo.
- Concetti tradizionali di Data Warehouse
- Fatti, dimensioni e misure
- Normalizzazione e denormalizzazione
- Modelli di Dati
- Tabella dei fatti
- Schema a stella vs Schema a fiocco di neve
- OLAP vs. OLTP
- Architettura a tre livelli
- Virtual Data Warehouse / Data Mart
- Kimball vs. Inmon
- ETL vs. ELT
- Enterprise Data Warehouse
- Cloud Data Warehouse Concetti
- Concetti di Cloud Data Warehouse – Amazon Redshift
- Cluster
- Nodi
- Partizioni/Sezioni
- Archiviazione colonnare
- Compressione
- Caricamento dei dati
- Cloud Database Warehouse – Google BigQuery
- Servizio serverless
- Colossus File System
- Dremel Execution Engine
- Condivisione dei dati
- Streaming e Batch Ingestion
- Cloud Data Warehouse Concepts – Panoply
- Chiavi primarie
- Chiavi incrementali
- Dati nidificati
- Tabelle di cronologia
- Trasformazioni
- Formati stringa
- Protezione dei dati
- Controllo accessi
- Whitelist IP
- Conclusione: Concetti tradizionali vs Data Warehouse in breve
- Concetti di data Warehouse tradizionali
- Cloud Data Warehouse Concepts – Amazon Redshift come esempio
- Cloud Data Warehouse Concepts – BigQuery come esempio
- Tradizionale vs. Cloud Analisi Costi-Benefici
- Ulteriori informazioni sui Data Warehouse
Concetti tradizionali di Data Warehouse
Un data warehouse è un qualsiasi sistema che raccoglie dati da un’ampia gamma di origini all’interno di un’organizzazione. I data warehouse sono utilizzati come archivi di dati centralizzati per scopi analitici e di reporting.
Un data warehouse tradizionale si trova in loco presso i vostri uffici. Si acquista l’hardware, le sale server e assumere il personale per eseguirlo. Sono anche chiamati data warehouse on-prem, on-prem o (grammaticalmente errati) on-premise.
Fatti, dimensioni e misure
I principali elementi costitutivi delle informazioni in un data warehouse sono fatti, dimensioni e misure.
Un fatto è la parte dei tuoi dati che indica un evento o una transazione specifica. Ad esempio, se la tua azienda vende fiori, alcuni fatti che vedresti nel tuo data warehouse sono:
- Venduto 30 rose in negozio per $19.99
- Ordinato 500 nuovi vasi di fiori dalla Cina per $1500
- Pagato stipendio di cassiere per questo mese $1000
Diversi numeri possono descrivere ogni fatto, e noi chiamiamo questi numeri misure. Alcune misure per descrivere il fatto ‘ordinato 500 nuovi vasi di fiori dalla Cina per $1500’ sono:
- Quantità ordinata-500
- Costo – $1500
Quando gli analisti lavorano con i dati, eseguono calcoli sulle misure (ad esempio, somma, massimo, media) per raccogliere informazioni. Ad esempio, potresti voler conoscere il numero medio di vasi da fiori che ordini ogni mese.
Una dimensione categorizza fatti e misure e fornisce informazioni di etichettatura strutturate per loro – altrimenti, sarebbero solo una raccolta di numeri non ordinati! Alcune dimensioni per descrivere il fatto e ‘ordinato 500 nuovi vasi di fiori dalla Cina per $1500’ sono:
- Paese acquistati dalla Cina
- Volta acquistato – 1 pm
- data Prevista di arrivo al 6 giugno
non È possibile eseguire calcoli sulle dimensioni in modo esplicito, e così facendo, probabilmente, non sarebbe molto utile, come si può trovare la ” media data di arrivo per ordini? Tuttavia, è possibile creare nuove misure dalle dimensioni e queste sono utili. Ad esempio, se si conosce il numero medio di giorni tra la data dell’ordine e la data di arrivo, è possibile pianificare meglio gli acquisti di magazzino.
Normalizzazione e denormalizzazione
La normalizzazione è il processo di organizzazione efficiente dei dati in un data warehouse (o in qualsiasi altro luogo che memorizza i dati). Gli obiettivi principali sono ridurre la ridondanza dei dati, ovvero rimuovere i dati duplicati, e migliorare l’integrità dei dati, ovvero migliorare l’accuratezza dei dati. Ci sono diversi livelli di normalizzazione e nessun consenso per il metodo “migliore”. Tuttavia, tutti i metodi comportano la memorizzazione di informazioni separate ma correlate in tabelle diverse.
Ci sono molti vantaggi per la normalizzazione, come ad esempio:
- più Veloce la ricerca e l’ordinamento della tabella
- più Semplici tabelle di dati comandi per la modifica veloce da scrivere ed eseguire
- Meno ridondante di dati consente di risparmiare spazio su disco, e quindi è in grado di raccogliere e memorizzare più dati
la denormalizzazione è il processo di deliberatamente aggiunta di copie ridondanti o gruppi di dati già dati normalizzati. Non è lo stesso dei dati non normalizzati. La denormalizzazione migliora le prestazioni di lettura e rende molto più facile manipolare le tabelle nei moduli desiderati. Quando gli analisti lavorano con data warehouse, in genere eseguono solo letture sui dati. Pertanto, i dati denormalizzati possono far risparmiare loro grandi quantità di tempo e mal di testa.
i Vantaggi di la denormalizzazione:
- Meno tavoli ridurre al minimo la necessità di join della tabella che accelera i dati degli analisti di flusso di lavoro e li porta alla scoperta di ulteriori approfondimenti utili in data
- Meno tavoli semplificare la query portando a un minor numero di bug
Modelli di Dati
sarebbe selvaggiamente inefficiente per memorizzare tutti i vostri dati in un tavolo massicci. Pertanto, il data warehouse contiene molte tabelle che è possibile unire per ottenere informazioni specifiche. La tabella principale è chiamata tabella dei fatti e le tabelle delle dimensioni la circondano.
Il primo passo nella progettazione di un data warehouse consiste nel creare un modello di dati concettuale che definisca i dati desiderati e le relazioni di alto livello tra di essi.
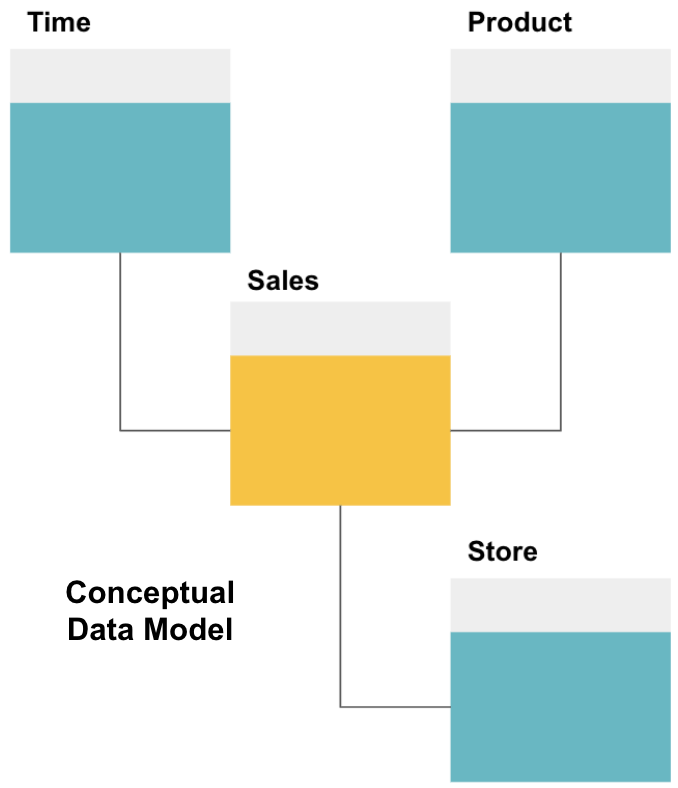
Qui, abbiamo definito il modello concettuale. Stiamo memorizzando i dati di vendita e abbiamo tre tabelle aggiuntive-Tempo, Prodotto e Negozio – che forniscono informazioni extra e più granulari su ogni vendita. La tabella dei fatti è Vendite e le altre sono tabelle di dimensione.
Il passo successivo è definire un modello di dati logici. Questo modello descrive i dati in dettaglio in inglese semplice senza preoccuparsi di come implementarli nel codice.
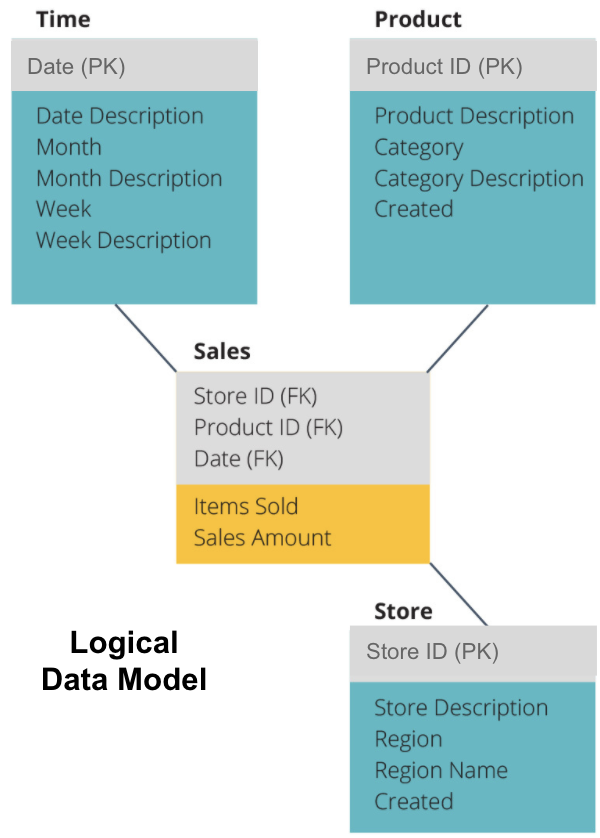
Ora abbiamo compilato quali informazioni ogni tabella contiene in inglese semplice. Ciascuna delle tabelle Time, Product e Store Dimension mostra la chiave primaria (PK) nella casella grigia e i dati corrispondenti nelle caselle blu. La tabella di vendita contiene tre chiavi esterne (FK) in modo che possa unirsi rapidamente con le altre tabelle.
La fase finale consiste nella creazione di un modello di dati fisici. Questo modello indica come implementare il data warehouse nel codice. Definisce le tabelle, la loro struttura e la relazione tra loro. Specifica anche i tipi di dati per le colonne e tutto è denominato come sarà nel data warehouse finale, cioè tutti i tappi e collegati con caratteri di sottolineatura. Infine, ogni tabella delle dimensioni inizia con DIM_ e ogni tabella dei fatti inizia con FACT_.
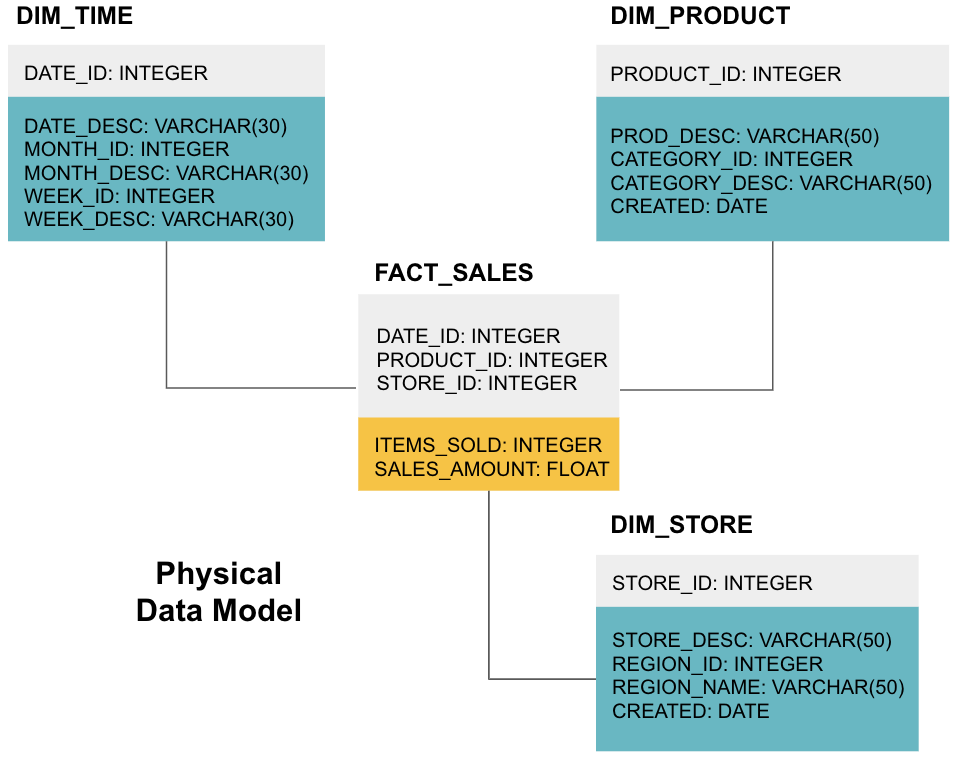
Ora sai come progettare un data warehouse, ma ci sono alcune sfumature nelle tabelle di fatto e dimensione che spiegheremo di seguito.
Tabella dei fatti
Ogni funzione aziendale, ad esempio vendite, marketing, finanza, ha una tabella dei fatti corrispondente.
Le tabelle dei fatti hanno due tipi di colonne: colonne dimensionali e colonne dei fatti. Le colonne di dimensione, di colore grigio nei nostri esempi, contengono chiavi esterne (FK) che si utilizzano per unire una tabella dei fatti a una tabella delle dimensioni. Queste chiavi esterne sono le chiavi primarie (PK) per ciascuna delle tabelle delle dimensioni. Le colonne Fact – colorate di giallo nei nostri esempi-contengono i dati effettivi e le misure da analizzare, ad esempio il numero di articoli venduti e il valore totale in dollari delle vendite.
Una tabella dei fatti senza fattezze è un particolare tipo di tabella dei fatti che ha solo colonne di dimensione. Tali tabelle sono utili per monitorare gli eventi, come la frequenza degli studenti o il congedo dei dipendenti, poiché le dimensioni ti dicono tutto ciò che devi sapere sugli eventi.
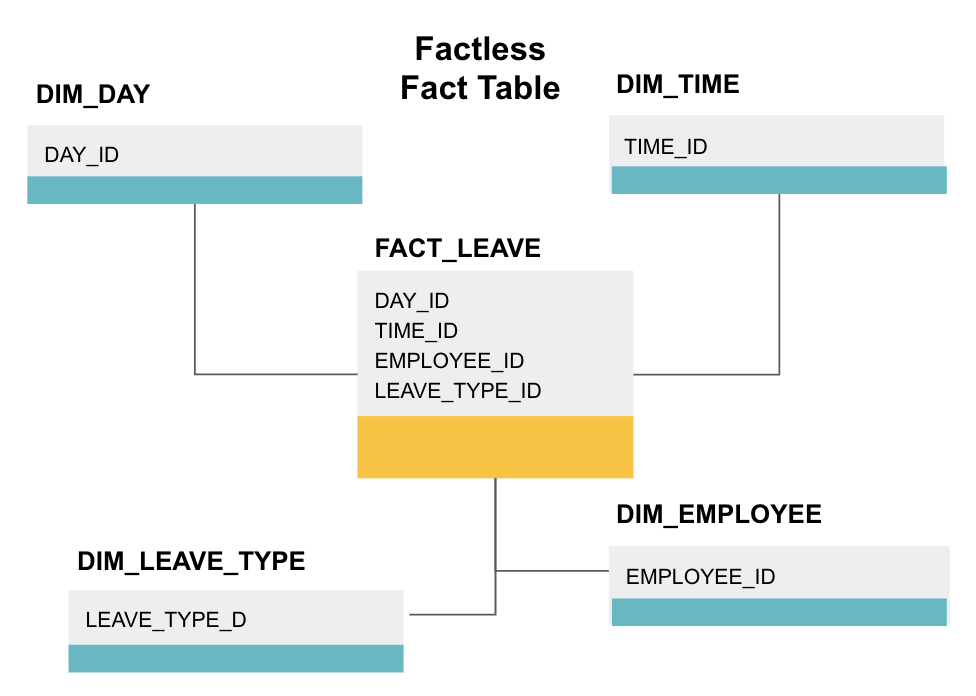
La tabella dei fatti di cui sopra tiene traccia delle ferie dei dipendenti. Non ci sono fatti dal momento che hai solo bisogno di sapere:
- Che giorno erano fuori (DAY_ID).
- Per quanto tempo erano spenti (TIME_ID).
- Chi era in congedo (EMPLOYEE_ID).
- La loro ragione di essere in congedo, ad esempio, malattia, vacanza, appuntamento del medico, ecc. (LEAVE_TIPE_ID).
Schema a stella vs Schema a fiocco di neve
I data warehouse di cui sopra hanno tutti un layout simile. Tuttavia, questo non è l’unico modo per organizzarli.
I due schemi più comuni utilizzati per organizzare i data warehouse sono star e snowflake. Entrambi i metodi utilizzano tabelle di dimensioni che descrivono le informazioni contenute in una tabella dei fatti.
Lo schema a stella prende le informazioni dalla tabella dei fatti e le divide in tabelle di dimensioni denormalizzate. L’enfasi per lo schema stella è sulla velocità di query. È necessario un solo join per collegare le tabelle dei fatti a ciascuna dimensione, quindi interrogare ogni tabella è facile. Tuttavia, poiché le tabelle sono denormalizzate, spesso contengono dati ripetuti e ridondanti.
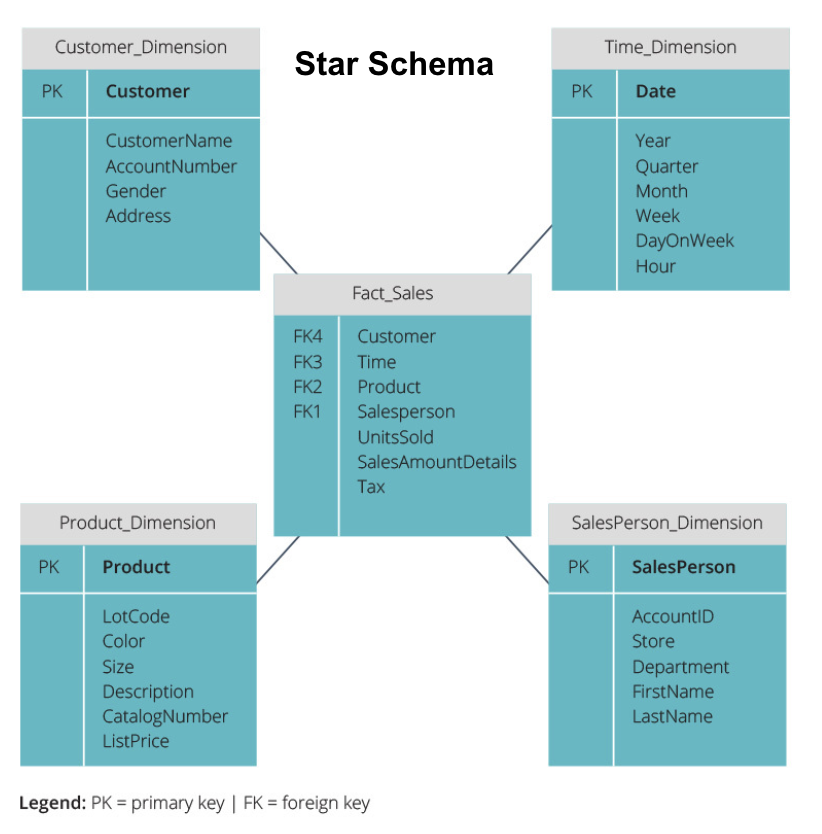
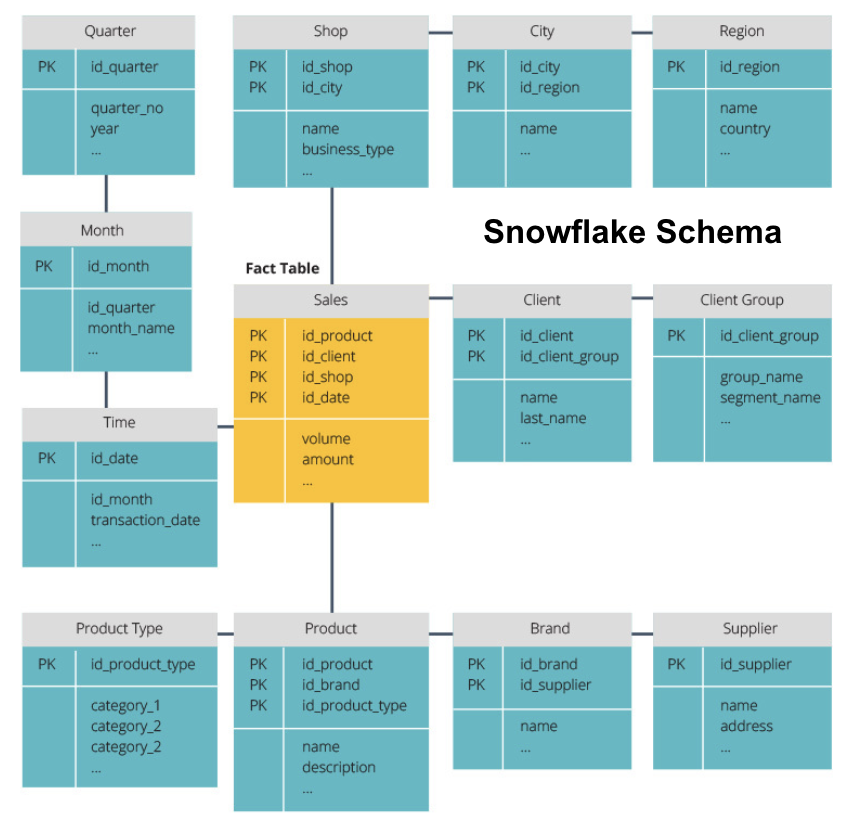
Lo schema snowflake suddivide la tabella dei fatti in una serie di tabelle di dimensioni normalizzate. La normalizzazione crea più tabelle di dimensioni e riduce quindi i problemi di integrità dei dati. Tuttavia, l’interrogazione è più impegnativa utilizzando lo schema snowflake perché sono necessari più join di tabelle per accedere ai dati rilevanti. Quindi, hai meno dati ridondanti, ma è più difficile accedervi.
Ora spiegheremo alcuni concetti di data warehouse più fondamentali.
OLAP vs. OLTP
L’elaborazione delle transazioni online (OLTP) è caratterizzata da transazioni di scrittura brevi che coinvolgono le applicazioni front-end dell’architettura dati di un’azienda. I database OLTP enfatizzano l’elaborazione rapida delle query e trattano solo i dati correnti. Le aziende li utilizzano per acquisire informazioni per i processi aziendali e fornire dati di origine per il data warehouse.
L’elaborazione analitica online (OLAP) consente di eseguire query di lettura complesse e quindi eseguire un’analisi dettagliata dei dati transazionali storici. I sistemi OLAP aiutano ad analizzare i dati nel data warehouse.
Architettura a tre livelli
I data warehouse tradizionali sono in genere strutturati su tre livelli:
- Livello inferiore: un server di database, in genere un RDBMS, che estrae dati da origini diverse utilizzando un gateway. Le origini dati inserite in questo livello includono database operativi e altri tipi di dati front-end come file CSV e JSON.
- Livello intermedio: un server OLAP che
- implementa direttamente le operazioni o
- Mappa le operazioni su dati multidimensionali a operazioni relazionali standard, ad esempio, appiattimento dei dati XML o JSON in righe all’interno delle tabelle.
- Top Tier: gli strumenti di query e reporting per l’analisi dei dati e la business intelligence.
Virtual Data Warehouse / Data Mart
Virtual data warehousing utilizza query distribuite su più database, senza integrare i dati in un unico data warehouse fisico.
I data mart sono sottoinsiemi di data warehouse orientati a specifiche funzioni aziendali, come vendite o finanza. Un data warehouse in genere combina informazioni da diversi data mart in più funzioni aziendali. Tuttavia, un data mart contiene dati provenienti da un insieme di sistemi di origine per una funzione aziendale.
Kimball vs. Inmon
Esistono due approcci alla progettazione del data warehouse, proposti da Bill Inmon e Ralph Kimball. Bill Inmon è uno scienziato informatico americano riconosciuto come il padre del data warehouse. Ralph Kimball è uno degli architetti originali del data warehousing e ha scritto diversi libri sull’argomento.
I due esperti avevano opinioni contrastanti su come strutturare i data warehouse. Questo conflitto ha dato origine a due scuole di pensiero.
L’approccio Inmon è un design top-down. Con la metodologia Inmon, il data warehouse viene creato per primo ed è visto come la componente centrale dell’ambiente analitico. I dati vengono quindi riepilogati e distribuiti dal magazzino centralizzato a uno o più data mart dipendenti.
L’approccio Kimball prende una vista dal basso verso l’alto della progettazione del data warehouse. In questa architettura, un’organizzazione crea data mart separati, che forniscono viste in singoli reparti all’interno di un’organizzazione. Il data warehouse è la combinazione di questi data mart.
ETL vs. ELT
Extract, Transform, Load (ETL) descrive il processo di estrazione dei dati dai sistemi di origine (tipicamente sistemi transazionali), la conversione dei dati in un formato o una struttura adatta per l’interrogazione e l’analisi e infine il caricamento nel data warehouse. ETL sfrutta un database di staging separato e applica una serie di regole o funzioni ai dati estratti prima del caricamento.
Extract, Load, Transform (ELT) è un approccio diverso al caricamento dei dati. ELT preleva i dati da fonti diverse e li carica direttamente nel sistema di destinazione, come il data warehouse. Il sistema trasforma quindi i dati caricati su richiesta per consentire l’analisi.
ELT offre un caricamento più rapido di ETL, ma richiede un sistema potente per eseguire le trasformazioni dei dati su richiesta.
Enterprise Data Warehouse
Un data warehouse aziendale è inteso come un magazzino centralizzato e unificato contenente tutte le informazioni transazionali nell’organizzazione, sia attuali che storiche. Un data warehouse aziendale dovrebbe incorporare i dati di tutte le aree tematiche relative al business, come marketing, vendite, finanza e risorse umane.
Queste sono le idee fondamentali che compongono i data warehouse tradizionali. Ora, diamo un’occhiata a ciò che cloud data warehouse hanno aggiunto sopra di loro.
Cloud Data Warehouse Concetti
Cloud data warehouse sono nuovi e in continua evoluzione. Per comprendere al meglio i loro concetti fondamentali, è meglio conoscere le principali soluzioni di data warehouse cloud.
Tre soluzioni di data warehouse cloud leader sono Amazon Redshift, Google BigQuery e Panoply. Di seguito, spieghiamo i concetti fondamentali di ciascuno di questi servizi per fornire una comprensione generale di come funzionano i moderni data warehouse.
Concetti di Cloud Data Warehouse – Amazon Redshift
I seguenti concetti sono esplicitamente utilizzati in Amazon Redshift cloud Data Warehouse, ma potrebbero applicarsi in futuro a soluzioni di data warehouse aggiuntive basate sull’infrastruttura Amazon.
Cluster
Amazon Redshift basa la sua architettura sui cluster. Un cluster è semplicemente un gruppo di risorse di calcolo condivise, chiamate nodi.
Nodi
I nodi sono risorse di calcolo che dispongono di CPU, RAM e spazio su disco rigido. Un cluster contenente due o più nodi è composto da un nodo leader e nodi di calcolo.
I nodi Leader comunicano con i programmi client e compilano codice per eseguire query, assegnandolo ai nodi di calcolo. I nodi di calcolo eseguono le query e restituiscono i risultati al nodo leader. Un nodo di calcolo esegue solo query che fanno riferimento alle tabelle memorizzate su quel nodo.
Partizioni/Sezioni
Amazon suddivide ogni nodo di calcolo in sezioni. Una sezione riceve un’allocazione di memoria e spazio su disco sul nodo. Più sezioni operano in parallelo per accelerare i tempi di esecuzione delle query.
Archiviazione colonnare
Redshift utilizza l’archiviazione colonnare, consentendo migliori prestazioni di query analitiche. Invece di memorizzare i record in righe, memorizza i valori da una singola colonna per più righe. I seguenti diagrammi rendono questo più chiaro:
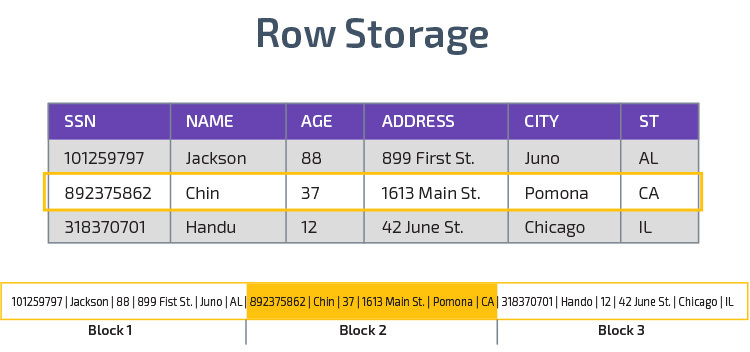
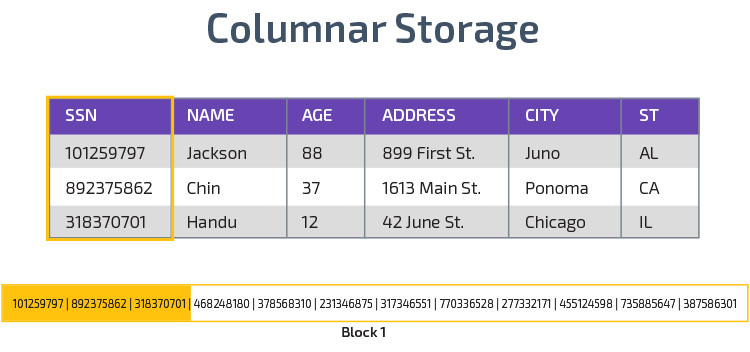
L’archiviazione colonnare consente di leggere i dati più velocemente, il che è fondamentale per le query analitiche che si estendono su molte colonne in un set di dati. L’archiviazione colonnare occupa anche meno spazio su disco, poiché ogni blocco contiene lo stesso tipo di dati, il che significa che può essere compresso in un formato specifico.
Compressione
La compressione riduce la dimensione dei dati memorizzati. In Redshift, a causa del modo in cui i dati vengono memorizzati, la compressione avviene a livello di colonna. Redshift consente di comprimere le informazioni manualmente durante la creazione di una tabella o automaticamente utilizzando il comando COPIA.
Caricamento dei dati
È possibile utilizzare il comando COPIA di Redshift per caricare grandi quantità di dati nel data warehouse. Il comando COPIA sfrutta l’architettura MPP di Redshift per leggere e caricare i dati in parallelo da file su Amazon S3, da una tabella DynamoDB o da output di testo da uno o più host remoti.
È anche possibile eseguire lo streaming di dati in Redshift, utilizzando il servizio Amazon Kinesis Firehose.
Cloud Database Warehouse – Google BigQuery
I seguenti concetti sono esplicitamente utilizzati nel Google BigQuery cloud data warehouse, ma potrebbero applicarsi a soluzioni aggiuntive in futuro basate sull’infrastruttura di Google.
Servizio serverless
BigQuery utilizza l’architettura serverless. Con BigQuery, le aziende non hanno bisogno di gestire unità server fisiche per eseguire i loro data warehouse. Invece, BigQuery gestisce dinamicamente l’allocazione delle sue risorse di calcolo. Le aziende che utilizzano il servizio pagano semplicemente l’archiviazione dei dati per gigabyte e le query per terabyte.
Colossus File System
BigQuery utilizza l’ultima versione del file system distribuito di Google, nome in codice Colossus. Il file system Colossus utilizza algoritmi di archiviazione e compressione colonnari per archiviare i dati a fini analitici in modo ottimale.
Dremel Execution Engine
Il motore di esecuzione Dremel utilizza un layout colonnare per interrogare vasti archivi di dati rapidamente. Il motore di esecuzione di Dremel può eseguire query ad hoc su miliardi di righe in pochi secondi perché utilizza un’elaborazione massicciamente parallela sotto forma di architettura ad albero.
L’architettura ad albero distribuisce le query tra diversi server intermedi da un server root. I server intermedi spingono la query verso i server leaf (contenenti dati memorizzati), che scansionano i dati in parallelo. Durante il backup dell’albero, ogni server leaf invia i risultati della query e i server intermedi eseguono un’aggregazione parallela di risultati parziali.
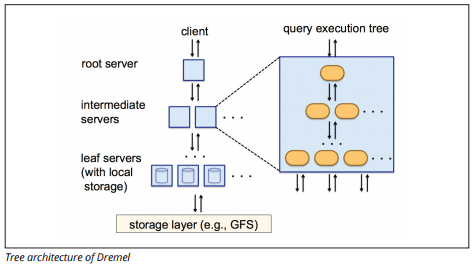
Image source
Dremel consente alle organizzazioni di eseguire query su un massimo di decine di migliaia di server contemporaneamente. Secondo Google, Dremel può eseguire la scansione di 35 miliardi di righe senza un indice in decine di secondi.
Condivisione dei dati
L’architettura serverless di Google BigQuery consente alle aziende di condividere facilmente i dati con altre organizzazioni senza richiedere a tali organizzazioni di investire nel proprio storage.
Le organizzazioni che desiderano interrogare i dati condivisi possono farlo e pagheranno solo per le query. Non è necessario creare costosi silos di dati condivisi, esterni all’infrastruttura dati dell’organizzazione, e copiare i dati in tali silos.
Streaming e Batch Ingestion
È possibile caricare dati su BigQuery da Google Cloud Storage, inclusi file CSV, JSON (delimitati da nuova riga) e Avro, nonché backup di Google Cloud Datastore. È inoltre possibile caricare i dati direttamente da un’origine dati leggibile.
BigQuery offre anche un’API di streaming per caricare i dati nel sistema a una velocità di milioni di righe al secondo senza eseguire un carico. I dati sono disponibili per l’analisi quasi immediatamente.
Cloud Data Warehouse Concepts – Panoply
Panoply è un magazzino all-in-one che combina ETL con un potente data warehouse. È il modo più semplice per sincronizzare, archiviare e accedere ai dati di un’azienda eliminando lo sviluppo e la codifica associati alla trasformazione, all’integrazione e alla gestione dei big data.
Di seguito sono riportati alcuni dei concetti principali del data warehouse Panoply relativi alla modellazione dei dati e alla protezione dei dati.
Chiavi primarie
Le chiavi primarie assicurano che tutte le righe delle tabelle siano univoche. Ogni tabella ha una o più chiavi primarie che definiscono ciò che rappresenta una singola riga univoca nel database. Tutte le API hanno una chiave primaria predefinita per le tabelle.
Chiavi incrementali
Panoply utilizza una chiave incrementale per controllare gli attributi per il caricamento incrementale dei dati nel data warehouse dalle origini anziché ricaricare l’intero set di dati ogni volta che qualcosa cambia. Questa funzione è utile per set di dati più grandi, che possono richiedere molto tempo per leggere i dati per lo più invariati. La chiave incrementale indica l’ultimo punto di aggiornamento per le righe in quell’origine dati.
Dati nidificati
I dati nidificati non sono completamente compatibili con le suite BI e le query SQL standard: Panoply tratta i dati nidificati utilizzando un modello fortemente relazionale che non consente valori nidificati. Panoply trasforma i dati nidificati in questi modi:
- Subtables: Per impostazione predefinita, Panoply trasforma i dati annidati in un insieme di tabelle di relazione molti-a-molti o uno-a-molti, che sono tabelle relazionali piatte.
- Appiattimento: con questa modalità abilitata, Panoply appiattisce la struttura nidificata sul record che la contiene.
Tabelle di cronologia
A volte è necessario analizzare i dati tenendo traccia delle modifiche dei dati nel tempo per vedere esattamente come cambiano i dati (ad esempio, gli indirizzi delle persone).
Per eseguire tali analisi, Panoply utilizza tabelle di cronologia, che sono tabelle di serie temporali che contengono istantanee storiche di ogni riga nella tabella statica originale. È quindi possibile eseguire una semplice interrogazione della tabella originale o delle revisioni della tabella riavvolgendo in qualsiasi momento.
Trasformazioni
Panoply utilizza ELT, che è una variazione del processo di integrazione dei dati ETL originale. Dopo aver iniettato i dati dall’origine nel data warehouse, Panoply li trasforma immediatamente. Questo processo offre analisi dei dati in tempo reale e prestazioni ottimali rispetto al processo ETL standard.
Formati stringa
Panoply analizza i formati stringa e li gestisce come se fossero oggetti annidati nei dati originali. I formati di stringa supportati sono CSV, TSV, JSON, JSON-Line, Ruby object format, stringhe di query URL e log di distribuzione Web.
Protezione dei dati
Panoply è basato su AWS, quindi ha le ultime patch di sicurezza e funzionalità di crittografia fornite da AWS, inclusa la crittografia RSA con accelerazione hardware e il set specifico di funzionalità di sicurezza di Amazon Redshift.
La protezione extra proviene dalla crittografia colonnare, che consente di utilizzare le chiavi private che non sono memorizzate sui server di Panoply.
Controllo accessi
Panoply utilizza la verifica in due passaggi per impedire l’accesso non autorizzato e un sistema di autorizzazioni consente di limitare l’accesso a tabelle, viste o colonne specifiche. Il rilevamento delle anomalie identifica le query provenienti da nuovi computer o da un paese diverso, consentendo di bloccare tali query a meno che non ricevano l’approvazione manuale.
Whitelist IP
Si consiglia di bloccare le connessioni da origini non riconosciute utilizzando un firewall o un gruppo di sicurezza AWS e di inserire nella whitelist l’intervallo di indirizzi IP che le origini dati di Panoply utilizzano sempre quando si accede al database.
Conclusione: Concetti tradizionali vs Data Warehouse in breve
Per concludere, riassumeremo i concetti introdotti in questo documento.
Concetti di data Warehouse tradizionali
- Fatti e misure: una misura è una proprietà su cui è possibile effettuare calcoli. Ci riferiamo a una raccolta di misure come fatti, ma a volte i termini sono usati in modo intercambiabile.
- Normalizzazione: il processo di riduzione della quantità di dati duplicati, che porta a un data warehouse più efficiente della memoria che è più lento da interrogare.
- Dimensione: utilizzato per categorizzare e contestualizzare fatti e misure, consentendo l’analisi e la segnalazione di tali misure.
- Modello di dati concettuale: definisce le entità di dati di alto livello critiche e le relazioni tra di esse.
- Modello di dati logici: Descrive relazioni di dati, entità e attributi in inglese semplice senza preoccuparsi di come implementarlo nel codice.
- Modello di dati fisici: una rappresentazione di come implementare la progettazione dei dati in un sistema di gestione di database specifico.
- Schema a stella: prende una tabella dei fatti e divide le sue informazioni in tabelle di dimensioni denormalizzate.
- Schema fiocco di neve: divide la tabella dei fatti in tabelle di dimensioni normalizzate. La normalizzazione riduce i problemi di ridondanza dei dati e migliora l’integrità dei dati, ma le query sono più complesse.
- OLTP: I sistemi di elaborazione delle transazioni online facilitano l’elaborazione veloce e orientata alle transazioni con semplici query.
- OLAP: L’elaborazione analitica online consente di eseguire query di lettura complesse e quindi eseguire un’analisi dettagliata dei dati transazionali storici.
- Data mart: un archivio di dati focalizzati su un soggetto o reparto specifico all’interno di un’organizzazione.
- Approccio Inmon: l’approccio data warehouse di Bill Inmon definisce il data warehouse come repository di dati centralizzato per l’intera azienda. I data mart possono essere costruiti dal data warehouse per soddisfare le esigenze analitiche di diversi reparti.
- Approccio Kimball: Ralph Kimball descrive un data warehouse come la fusione di data mart mission-critical, che vengono inizialmente creati per soddisfare le esigenze analitiche di diversi reparti.
- ETL: Integra i dati nel data warehouse estraendoli da varie fonti transazionali, trasformando i dati per ottimizzarli per l’analisi e infine caricandoli nel data warehouse.
- ELT: Una variazione su ETL che estrae i dati grezzi dalle origini dati di un’organizzazione e li carica nel data warehouse. Quando necessario, viene trasformato per scopi analitici.
- Data Warehouse aziendale: EDW consolida i dati di tutte le aree tematiche relative all’azienda.
Cloud Data Warehouse Concepts – Amazon Redshift come esempio
- Cluster: un gruppo di risorse di calcolo condivise basate nel cloud.
- Nodo: una risorsa di calcolo contenuta all’interno di un cluster. Ogni nodo ha la propria CPU, RAM e spazio su disco rigido.
- Colonnare di stoccaggio: Memorizza i valori di una tabella in colonne anziché in righe, ottimizzando i dati per le query aggregate.
- Compressione: Tecniche per ridurre la dimensione dei dati memorizzati.
- Caricamento dei dati: ottenere i dati dalle origini nel data warehouse basato su cloud. In Redshift, è possibile utilizzare il comando COPIA o un servizio di streaming dati.
Cloud Data Warehouse Concepts – BigQuery come esempio
- Servizio serverless: il provider cloud gestisce dinamicamente l’allocazione delle risorse della macchina in base alla quantità consumata dall’utente. Il provider cloud nasconde le decisioni di gestione del server e di pianificazione della capacità agli utenti del servizio.
- Colossus file system: un file system distribuito che utilizza algoritmi di archiviazione colonnare e compressione dei dati per ottimizzare i dati per l’analisi.
- Motore di esecuzione Dremel: un motore di query che utilizza l’elaborazione massiva parallela e l’archiviazione colonnare per eseguire rapidamente le query.
- Condivisione dei dati: in un servizio serverless, è pratico interrogare i dati condivisi di un’altra organizzazione senza investire nell’archiviazione dei dati: è sufficiente pagare per le query.
- Dati in streaming: inserimento dei dati in tempo reale nel data warehouse senza eseguire un carico. È possibile eseguire lo streaming dei dati nelle richieste batch, ovvero più chiamate API combinate in un’unica richiesta HTTP.
Tradizionale vs. Cloud Analisi Costi-Benefici
| Costi/Benefici | Tradizionale | Cloud |
| Costo | Grande costo iniziale per l’acquisto e l’installazione di un prem sistema. Hai bisogno di hardware, sale server e personale specializzato (che paghi su base continuativa). Se non siete sicuri di quanto spazio di archiviazione è necessario, c’è il rischio di costi elevati affondati che sono difficili da recuperare. |
Non è necessario acquistare hardware, sale server o assumere specialisti. Nessun rischio di costi irrisolti-acquistare più spazio di archiviazione in futuro è facile. Inoltre, il costo di archiviazione e la potenza di calcolo stanno diminuendo nel tempo. |
| Scalabilità | Una volta esaurite le sale server o la capacità hardware corrente, potrebbe essere necessario acquistare nuovo hardware e costruire/acquistare più posti per ospitarlo. Inoltre, è necessario acquistare spazio sufficiente per far fronte alle ore di punta; pertanto, la maggior parte delle volte, la maggior parte del tuo spazio di archiviazione non viene utilizzata. |
Si può facilmente acquistare più di stoccaggio come e quando ne avete bisogno. Spesso devi solo pagare per quello che usi, quindi c’è poco o nessun rischio di pagare troppo. |
| Integrazioni | Poiché il cloud computing è la norma, la maggior parte delle integrazioni che si desidera effettuare saranno i servizi cloud. Collegare il tuo data warehouse personalizzato a loro può rivelarsi impegnativo. |
Poiché i data warehouse cloud sono già nel cloud, la connessione a una serie di altri servizi cloud è semplice. |
| Sicurezza | Hai il controllo totale del tuo data warehouse. Confrontando la quantità di dati che ospita su Amazon o Google, sei un bersaglio più piccolo per i ladri. Così, si può essere più probabilità di essere lasciato solo. |
I fornitori di Cloud data warehouse dispongono di team di ingegneri di sicurezza altamente qualificati il cui unico scopo è rendere il loro prodotto il più sicuro possibile. Le aziende più importanti al mondo li gestiscono e quindi implementano pratiche di sicurezza di livello mondiale. |
| Governance | Sai esattamente dove si trovano i tuoi dati e puoi accedervi localmente. Meno rischio di dati altamente sensibili infrangendo inavvertitamente la legge, ad esempio, viaggiando in tutto il mondo su un server cloud. |
I principali fornitori di cloud data warehouse assicurano di essere conformi alle leggi sulla governance e sulla sicurezza, come il GDPR. Inoltre, aiutano la tua azienda a garantire la conformità. Ci sono stati problemi per quanto riguarda la conoscenza esattamente i dati è e dove si muove. Questi problemi sono attivamente affrontati e risolti. Si noti che la memorizzazione di grandi quantità di dati altamente sensibili sul cloud può essere contraria a leggi specifiche. Questo è un caso in cui il cloud computing può essere inappropriato per la tua azienda. |
| Affidabilità | Se il data warehouse on-prem non riesce, è vostra responsabilità di risolvere il problema. Il tuo team IT ha accesso all’hardware fisico e può accedere a tutti i livelli software per risolvere i problemi. Questo accesso rapido può rendere la risoluzione dei problemi molto più veloce. Tuttavia, non vi è alcuna garanzia che il vostro magazzino avrà una particolare quantità di uptime ogni anno. |
I fornitori di cloud data warehouse garantiscono la loro affidabilità e uptime nei loro SLA. Operano su sistemi distribuiti in modo massiccio in tutto il mondo, quindi se c’è un errore su uno, è altamente improbabile che ti influenzi. |
| Controllo | Il tuo data warehouse è costruito su misura per soddisfare le vostre esigenze. In teoria, fa quello che vuoi che faccia, quando vuoi, in un modo che capisci. | Non hai il controllo totale sul tuo data warehouse. Tuttavia, la maggior parte delle volte, il controllo che hai è più che sufficiente. |
| Velocità | Se sei una piccola azienda in una posizione geografica con una piccola quantità di dati, l’elaborazione dei dati sarà più veloce. Tuttavia, stiamo parlando di millisecondi rispetto ai secondi per il completamento di alcuni processi. È improbabile che una grande azienda che opera in più paesi veda significativi guadagni di velocità con un sistema on-prem. |
I fornitori di cloud hanno investito e creato sistemi che implementano l’elaborazione Massively Parallel Processing (MPP), motori di esecuzione e architettura personalizzati e algoritmi di elaborazione dati intelligenti. I data warehouse cloud sono il risultato di anni di ricerca e test per creare risorse ottimizzate per velocità e prestazioni. Può essere leggermente più lento di on-prem in alcuni casi, ma questi ritardi sono spesso trascurabili per gli esseri umani (secondi vs millisecondi). |
Panoply è un luogo sicuro per archiviare, sincronizzare e accedere a tutti i dati aziendali. Panoply può essere impostato in pochi minuti, richiede zero manutenzione in corso e fornisce supporto online, incluso l’accesso a data architect esperti. Prova Panoply gratis per 14 giorni.
Ulteriori informazioni sui Data Warehouse
- Architettura Data Warehouse: tradizionale vs. Cloud
- Database vs. Data Warehouse
- Data Mart vs. Data Warehouse