Clustering e K significa: definizione e analisi del cluster in Excel
Definizioni statistiche > Clustering / Analisi cluster
Che cos’è il Clustering?
Il clustering nelle statistiche si riferisce al modo in cui i dati vengono raccolti (“clustered”) da fattori come:
- Età.
- Dimensione delle famiglie.
- Reddito.
- O livello di istruzione.
L’ordinamento dei dati in cluster a volte porta a ulteriori indagini sui dati. Ad esempio, i cluster di cancro possono indicare qualche problema nell’ambiente. Oppure, possono essere solo il risultato della natura casuale. L’analisi del cluster tende ad essere soggettiva in molti casi; dipende da ciò che percepisci come thread comuni nei dati. La tecnica non è davvero nulla di nuovo nelle statistiche; se hai mai creato un grafico a barre, probabilmente hai già creato cluster (anche se non l’hai chiamato così). Ad esempio, un grafico a barre che mostra le razze di cani richiede di raggruppare per razza (Siberian Husky, Border Collie, Pastore tedesco…) o un grafico dei livelli di reddito potrebbe essere raggruppato per livelli di reddito bassi, medi e alti.
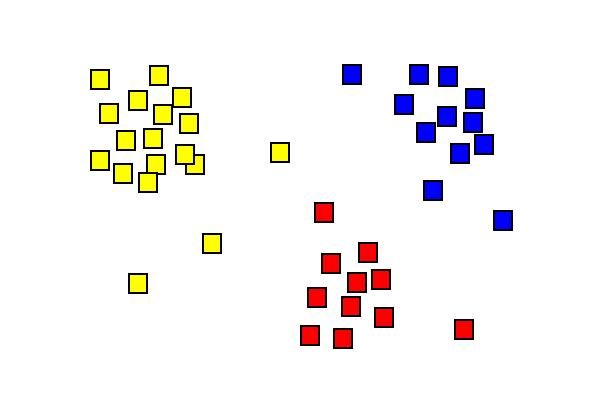
Risultati dell’analisi dei cluster che mostrano tre diversi cluster colorati.
I cluster possono essere basati su fattori come:
- Clustering basato sulla distanza. Gli articoli sono ordinati in base alla loro vicinanza (o distanza). Ad esempio, i casi di cancro potrebbero essere raggruppati se si trovano nella stessa posizione geografica.
- Clustering concettuale. Gli elementi sono raggruppati in base a fattori che gli elementi hanno in comune. Ad esempio, i cluster di cancro potrebbero essere raggruppati da “persone che lavorano nella produzione.”
Tipi di clustering
- Clustering esclusivo. Ogni elemento può appartenere solo a un singolo cluster. Non può appartenere a un altro cluster.
- Fuzzy clustering: ai punti dati viene assegnata una probabilità di appartenenza a uno o più cluster.
- Clustering sovrapposto. Ogni elemento può appartenere a più di un cluster.
- Clustering gerarchico. Questo è un approccio più complesso al clustering utilizzato nel data mining. Fondamentalmente, ad ogni elemento viene dato il proprio cluster. Una coppia di cluster viene unita in base alle somiglianze, dando un cluster in meno. Questo processo viene ripetuto fino a quando tutti gli elementi sono raggruppati. Il dendrogramma è un grafico che mostra cluster gerarchici.
- Clustering probabilistico. I dati vengono raggruppati utilizzando algoritmi che collegano gli elementi utilizzando distanze o densità. Questo di solito viene eseguito da un computer.
- Metodo di Ward: utilizza la varianza minima in ogni passaggio per creare cluster relativamente piccoli e di dimensioni uniformi.
K Significa Clustering
Il clustering è solo un modo per raggruppare un insieme di dati in insiemi più piccoli. I due modi in cui è possibile raggruppare un insieme di dati sono quantitativamente (usando i numeri) e qualitativamente (usando le categorie). Ad esempio, libri su Amazon.com sono elencati sia per categoria (qualitativa) che per best seller (quantitativo). K-Means clustering è uno dei più semplici algoritmi di apprendimento non supervisionato che risolve i problemi di clustering utilizzando un metodo quantitativo: si pre-definire un numero di cluster e utilizzare un semplice algoritmo per ordinare i dati. Detto questo, “semplice” nel mondo dell’informatica non equivale a semplice nella vita reale. Questo è in realtà un problema NP-difficile, quindi ti consigliamo di utilizzare il software per K-means clustering. Alcuni programmi che eseguiranno questo per te (fai clic sul link per la procedura) sono:
- SPS.
- r
- MATLAB
I passaggi generali dietro l’algoritmo di clustering K-means sono:
- Decidere quanti cluster (k).
- Posiziona k punti centrali in posizioni diverse (di solito distanti l’uno dall’altro).
- Prendere ogni punto dati e posizionarlo vicino al punto centrale appropriato. Ripetere fino a quando tutti i punti dati sono stati assegnati.
- Ricalcola k nuovi punti centrali come baricentri.
- Ripetere l’assegnazione dei punti dati, questa volta al nuovo punto centrale (il baricentro).
- Ripetere 4 e 5 fino a quando i punti centrali (baricentri) non si muovono più.
K-Means Clustering: Una definizione più formale
Un modo più formale per definire K-Means clustering è classificare n oggetti in gruppi predefiniti k(k> 1). L’obiettivo è ridurre al minimo la distanza da ciascun punto dati al cluster. In altre parole, per trovare:
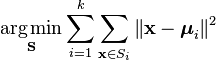
dove:
X è un punto dati
k è il numero di cluster
ui è la media dei punti in Si.
Analisi cluster vs. Analisi discriminante
L’analisi cluster è molto simile all’analisi discriminante. Entrambi i metodi comportano la separazione in gruppi. Tuttavia, l’analisi cluster è un modo per identificare i gruppi, mentre l’analisi discriminante richiede di conoscere i gruppi prima di iniziare l’analisi. Ad esempio, diciamo che hai avuto un gruppo di pazienti psichiatrici con comportamenti anormali. L’analisi dei cluster potrebbe aiutarti a trovare gruppi distinti, come i pazienti con una storia di abuso, quelli con PTSD o quelli che hanno allucinazioni. Se si dovesse eseguire l’analisi discriminante sullo stesso gruppo di persone, è necessario conoscere le diagnosi dei pazienti prima di iniziare a metterli in gruppi.
Clustering in Excel
Microsoft Excel dispone di un componente aggiuntivo di data mining per creare cluster. Puoi trovare le istruzioni qui. La procedura guidata funziona con tabelle di Excel, intervalli o query di indagine di analisi. Questo componente aggiuntivo può essere personalizzato, a differenza dello strumento Rileva categorie. Inoltre, lo strumento Rileva categorie è limitato ai dati delle tabelle.
Da usare:
- Scarica e installa il componente aggiuntivo di Data Mining.
- Fai clic su” Data Mining”, quindi su” Cluster”, quindi su ” Avanti.”
- Indica a Excel dove si trovano i tuoi dati. Ad esempio, selezionare un intervallo di dati. La pagina di clustering sarà disponibile.
- Clustering: lasciare come è per il raggruppamento automatico, oppure è possibile specificare un numero di gruppi.
- Segmenti: lasciare così com’è per il raggruppamento automatico o specificare un numero di categorie.
Stephanie Glen. “Clustering e K significa: Definizione & Analisi cluster in Excel” Da StatisticsHowTo.com: Statistiche elementari per il resto di noi! https://www.statisticshowto.com/clustering/
——————————————————————————
Hai bisogno di aiuto con un compito a casa o una domanda di prova? Con Chegg Studio, è possibile ottenere soluzioni passo-passo alle vostre domande da un esperto del settore. I tuoi primi 30 minuti con un tutor Chegg sono gratuiti!