Evolution of cluster scheduling system
Kubernetes è diventato lo standard de facto nell’area dell’orchestrazione dei container. Tutte le applicazioni saranno sviluppate ed eseguite su Kubernetes in futuro. Lo scopo di questa serie di articoli è quello di introdurre i principi di implementazione alla base di Kubernetes in modo profondo e semplice.
Kubernetes è un sistema di programmazione cluster. Questo articolo introduce principalmente alcune precedenti architetture di sistema di programmazione cluster di Kubernetes. Analizzando le loro idee progettuali e le caratteristiche dell’architettura, possiamo studiare il processo di evoluzione dell’architettura del sistema di pianificazione dei cluster e il problema principale che deve essere considerato nella progettazione dell’architettura. Questo sarà molto utile per comprendere l’architettura di Kubernetes.
Abbiamo bisogno di capire alcuni dei concetti di base del sistema di programmazione cluster, al fine di rendere chiaro, spiegherò il concetto attraverso un esempio, supponiamo che vogliamo implementare un Cron distribuito. Il sistema gestisce un insieme di host Linux. L’utente definisce il lavoro tramite l’API fornita dal sistema. il sistema eseguirà periodicamente l’attività corrispondente in base alla definizione dell’attività, in questo esempio, i concetti di base sono riportati di seguito:
- Cluster: gli host Linux gestiti da questo sistema formano un pool di risorse per eseguire le attività. Questo pool di risorse è chiamato Cluster.
- Lavoro: definisce il modo in cui il cluster svolge le sue attività. In questo esempio, Crontab è esattamente un lavoro semplice che mostra chiaramente cosa deve fare(script di esecuzione) a che ora (intervallo di tempo).La definizione di alcuni lavori è più complessa, ad esempio la definizione di un lavoro da completare in più attività e le dipendenze tra le attività, nonché i requisiti di risorse di ciascuna attività.
- Task: un lavoro deve essere programmato in specifiche attività di performance. Se definiamo un lavoro per eseguire uno script all ‘1 del mattino ogni notte, il processo di script eseguito all’ 1 del mattino ogni giorno è un’attività.
Quando si progetta il sistema di pianificazione del cluster, le attività principali del sistema sono due:
- Pianificazione attività: Dopo che i lavori sono stati inviati al sistema di pianificazione del cluster, i lavori inviati devono essere suddivisi in attività di esecuzione specifiche e i risultati di esecuzione delle attività devono essere monitorati e monitorati. Nell’esempio del Cron distribuito, il sistema di pianificazione deve avviare tempestivamente il processo in conformità con i requisiti dell’operazione. Se il processo non riesce a eseguire, è necessario riprovare ecc. Alcuni scenari complessi, come Hadoop Map Reduce, il sistema di pianificazione deve dividere l’attività Map Reduce nella corrispondente mappa multipla e Ridurre le attività e, infine, ottenere i dati dei risultati di esecuzione dell’attività.
- Pianificazione delle risorse: viene essenzialmente utilizzato per abbinare attività e risorse e vengono allocate risorse appropriate per eseguire attività in base all’utilizzo delle risorse degli host nel cluster. È simile al processo di algoritmo di scheduling del sistema operativo, l’obiettivo principale della pianificazione delle risorse è quello di migliorare l’utilizzo delle risorse, per quanto possibile, e ridurre il tempo di attesa per le attività sotto la condizione di fisso fornitura di risorse e ridurre il ritardo dell’attività o del tempo di risposta (se lotto di attività, che indica il tempo dall’inizio alla fine delle operazioni, se è in linea di risposta tipo di attività, come le applicazioni Web, che si riferisce ad ogni tempo di risposta alla richiesta), il Compito prioritario deve essere presa in considerazione, pur essendo il più equo possibile (le risorse sono equamente assegnate a tutte le attività). Alcuni di questi obiettivi sono in conflitto e devono essere bilanciati, come l’utilizzo delle risorse, i tempi di risposta, l’equità e le priorità.
Hadoop MRv1
Map Reduce è una sorta di modello di calcolo parallelo. Hadoop può eseguire questo tipo di piattaforma di gestione cluster di calcolo parallelo. MRv1 è la versione di prima generazione di Map Reduce task scheduling engine della piattaforma Hadoop. In breve, MRv1 è responsabile per la pianificazione e l’esecuzione del lavoro sul cluster, e tornare ai risultati di calcolo quando un utente definisce una mappa Ridurre il calcolo e inviarlo al Hadoop. Qui è che cosa l’architettura di MRv1 sembra:
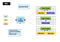
L’architettura è relativamente semplice, standard di architettura Master/Slave ha due componenti principali:
- Job Tracker è il principale componente di gestione del cluster, che è responsabile sia della pianificazione delle risorse che della pianificazione delle attività.
- Task Tracker viene eseguito su ogni macchina nel cluster, che è responsabile per l’esecuzione di attività specifiche sull’host e lo stato di reporting.
Con la popolarità di Hadoop e l’aumento di varie richieste, MRv1 ha i seguenti problemi da migliorare:
- Le prestazioni hanno un certo collo di bottiglia: il numero massimo di nodi che supportano la gestione è 5.000 e il numero massimo di attività di supporto è 40.000. C’è ancora qualche margine di miglioramento.
- Non è abbastanza flessibile per estendere o supportare altri tipi di attività. Oltre alle attività di tipo riduci mappa, ci sono molti altri tipi di attività nell’ecosistema Hadoop che devono essere pianificati, come Spark, Hive, HBase, Storm, Oozie, ecc. Pertanto, è necessario un sistema di pianificazione più generale, in grado di supportare ed estendere più tipi di attività
- Basso utilizzo delle risorse: MRv1 configura staticamente un numero fisso di slot per ogni nodo e ogni slot può essere utilizzato solo per il tipo di attività specifico (Map o Reduce), il che porta al problema dell’utilizzo delle risorse. Ad esempio, un gran numero di attività della mappa sono in coda per le risorse inattive, ma in realtà, un gran numero di slot di riduzione sono inattivi per le macchine.
- Problemi di multi-tenancy e multi-versione. Ad esempio, diversi reparti eseguono attività nello stesso cluster, ma sono logicamente isolati l’uno dall’altro o eseguono versioni diverse di Hadoop nello stesso cluster.
YARN
YARN (Yet Another Resource Negotiator) è una seconda generazione di Hadoop ,lo scopo principale è quello di risolvere tutti i tipi di problemi in MRv1. FILATO architettura simile a questo:

La semplice comprensione del FILATO è che il principale miglioramento rispetto MRv1 è quello di dividere le responsabilità dell’originale JobTrack in due diverse componenti: Gestione risorse e l’Applicazione Master
- Gestione Risorse: È responsabile della pianificazione delle risorse, gestisce tutte le risorse, assegna risorse a diversi tipi di attività ed estende facilmente l’algoritmo di pianificazione delle risorse attraverso un’architettura collegabile.
- Application Master: è responsabile della pianificazione delle attività. Ogni lavoro (chiamato Applicazione in YARN) avvia un Master dell’applicazione corrispondente, che è responsabile della suddivisione del lavoro in attività specifiche e della richiesta di risorse da Resource Manager, dell’avvio dell’attività, del monitoraggio dello stato dell’attività e della segnalazione dei risultati.
Diamo un’occhiata a come questo cambiamento di architettura ha risolto i vari problemi di MRv1:
- Dividere le responsabilità di pianificazione compito originale di Job Tracker, e con conseguente significativi miglioramenti delle prestazioni. Le responsabilità di pianificazione delle attività del Job Tracker originale sono state suddivise per essere intraprese dal Master dell’applicazione e il Master dell’applicazione è stato distribuito,ogni istanza ha gestito solo la richiesta di un lavoro, quindi ha promosso il numero massimo di nodi cluster da 5.000 a 10.000.
- I componenti della pianificazione delle attività, del master delle applicazioni e della pianificazione delle risorse vengono disaccoppiati e creati dinamicamente in base alle richieste di lavoro. Un’istanza Master dell’applicazione è responsabile di un solo lavoro di pianificazione, il che rende più facile supportare diversi tipi di lavori.
- Viene introdotta la tecnologia di isolamento del contenitore, ogni attività viene eseguita in un contenitore isolato, il che migliora notevolmente l’utilizzo delle risorse in base alla richiesta di risorse dell’attività che può essere allocata dinamicamente. Lo svantaggio di questo è la gestione delle risorse di YARN e l’allocazione hanno solo una dimensione di memoria.
Mesos architecture
L’obiettivo progettuale di YARN è ancora quello di servire la programmazione dell’ecosistema Hadoop. L’obiettivo di Mesos si avvicina, è progettato per essere un sistema di pianificazione generale, in grado di gestire il funzionamento dell’intero data center. Come si vede, la progettazione architettonica di Mesos utilizzato un sacco di filato per riferimento, la programmazione dei lavori e la pianificazione delle risorse sono a carico dei diversi moduli separatamente. Ma la più grande differenza tra Mesos e YARN è il modo di pianificare le risorse, è stato progettato un meccanismo unico chiamato offerta di risorse. La pressione della pianificazione delle risorse viene ulteriormente rilasciata e aumenta anche la scalabilità della pianificazione dei lavori.

I componenti principali di Mesos sono:
- Mesos Master: si tratta di un componente il solo responsabile per l’allocazione delle Risorse e componenti di gestione, Gestione Risorse corrispondenti all’interno del FILATO. Ma la modalità di funzionamento è leggermente diversa se sarà discusso più avanti.
- Framework: è responsabile della pianificazione dei lavori, diversi tipi di lavoro avranno un Framework corrispondente, ad esempio il framework Spark che è responsabile dei lavori Spark.
Offerta di risorse di Mesos
Può sembrare che le architetture Mesos e YARN siano abbastanza simili, ma, in realtà, sotto l’aspetto della gestione delle risorse, il Maestro di Mesos ha un meccanismo di offerta di risorse molto particolare (e un po ‘ bizzarro) :
- FILATO è tirare: Le risorse fornite da Resource Manager in YARN sono passive, quando i consumatori di risorse (Application Master) hanno bisogno di risorse, possono chiamare l’interfaccia di Resource Manager per ottenere risorse e Resource Manager risponde solo passivamente alle esigenze di Application Master.
- Mesos è Push: le risorse fornite da Master of Mesos sono proattive. Il Maestro di Mesos prenderà regolarmente l’iniziativa di spingere tutte le attuali risorse disponibili (le cosiddette offerte di risorse, la chiamerò Offerta d’ora in poi) al Framework. Se ci sono attività da eseguire per il Framework, non può richiedere attivamente le risorse, a meno che non vengano ricevute le offerte. Framework seleziona una risorsa qualificata dall’Offerta da accettare (questa mozione è chiamata Accetta in Mesos) e rifiuta le offerte rimanenti (questa mozione è chiamata Rifiuta). Se non ci sono abbastanza risorse qualificate in questo round di offerta, dobbiamo aspettare il prossimo round di Master per fornire un’offerta.
Credo che quando vedi questo meccanismo di Offerta attiva, avrai lo stesso feeling con me. Cioè, l’efficienza è relativamente bassa e si presenteranno i seguenti problemi:
- l’efficienza decisionale di qualsiasi quadro influisce sull’efficienza complessiva. Per coerenza, Master può fornire solo un’offerta a un Framework alla volta e attendere che il Framework selezioni l’offerta prima di fornire il resto al Framework successivo. In questo modo, l’efficienza decisionale di qualsiasi quadro influenzerà l’efficienza complessiva.
- “sprecare” molto tempo su framework che non richiedono risorse. Mesos non sa davvero quale framework ha bisogno di risorse. Quindi ci sarà un Framework con requisiti di risorse in coda per l’offerta, ma il Framework senza requisiti di risorse riceve spesso l’offerta.
In risposta ai problemi di cui sopra, Mesos ha fornito alcuni meccanismi per mitigare i problemi, come l’impostazione di un timeout per il Framework per prendere decisioni o consentire al Framework di rifiutare le offerte impostandolo come stato di soppressione. Dal momento che non è al centro di questa discussione, i dettagli sono trascurati qui.
In effetti, ci sono alcuni ovvi vantaggi per i Mesos che utilizzano questo meccanismo di offerta attiva:
- Le prestazioni sono evidentemente migliorate. Un cluster può supportare fino a 100.000 nodi in base al test di simulazione, per l’ambiente di produzione di Twitter, il cluster più grande può supportare 80.000 nodi. il motivo principale è che l’offerta attiva di Mesos Master mechanism semplifica ulteriormente le responsabilità del Mesos. il processo di pianificazione delle risorse, resource to task matching, in Mesos è diviso in due fasi: risorse da offrire e Offerta da attività. Il Maestro Mesos è responsabile solo del completamento della prima fase e l’abbinamento della seconda fase è lasciato al Framework.
- Più flessibile e in grado di soddisfare le politiche più responsabili di pianificazione delle attività. Ad esempio, la strategia di utilizzo delle risorse di Tutto o Nulla.
Algoritmo di pianificazione di Mesos DRF (Dominant Resource Fairness)
Per quanto riguarda l’algoritmo DRF, in realtà non ha nulla a che fare con la nostra comprensione dell’architettura Mesos, ma è molto fondamentale e importante in Mesos, quindi spiegherò un po ‘ di più qui.
Come accennato in precedenza, Mesos fornisce un’offerta al Framework a sua volta, quindi quale Framework dovrebbe essere selezionato per fornire un’offerta ogni volta? Questo è il problema principale da risolvere con l’algoritmo DRF. Il principio di base è quello di prendere in considerazione sia l’equità che l’efficienza. Pur soddisfacendo tutti i requisiti di risorse del Framework, dovrebbe essere il più equo possibile evitare che un Framework consumi troppe risorse e affami a morte altri framework.
DRF è una variante dell’algoritmo di equità min-max. In termini semplici, è quello di selezionare il quadro con il più basso utilizzo delle risorse dominante per fornire l’offerta ogni volta. Come calcolare l’utilizzo delle risorse dominante del framework? Da tutti i tipi di risorse occupati dal Framework, il tipo di risorsa con il tasso di occupazione delle risorse più basso viene selezionato come Risorsa dominante. Il suo tasso di occupazione delle risorse è esattamente l’utilizzo delle risorse dominante del Framework. Ad esempio, una CPU di Framework occupa il 20% della Risorsa complessiva, il 30% della memoria e il 10% del disco. Quindi l’utilizzo delle risorse dominanti del Framework sarà del 10%, il termine ufficiale chiama un disco come risorsa dominante e questo 10% è chiamato Utilizzo delle risorse dominanti.
L’obiettivo finale di DRF è distribuire equamente le risorse tra tutti i framework. Se un Framework X accetta troppe risorse in questo round di offerta, ci vorrà molto più tempo per ottenere l’opportunità del prossimo round di offerta. Tuttavia, i lettori attenti scopriranno che c’è un’ipotesi in questo algoritmo, cioè, dopo che il Framework accetta le risorse, le rilascerà rapidamente, altrimenti ci saranno due conseguenze:
- Altri quadri muoiono di fame. Un Framework A accetta la maggior parte delle risorse nel cluster contemporaneamente e l’attività continua a funzionare senza uscire, in modo che la maggior parte delle risorse sia occupata dal Framework A tutto il tempo e altri framework non otterranno più le risorse.
- Muori di fame. Poiché l’utilizzo delle risorse dominante di questo framework è sempre molto alto, quindi non vi è alcuna possibilità di ottenere un’offerta per un lungo periodo, quindi non è possibile eseguire più attività.
Quindi Mesos è adatto solo per la pianificazione di attività brevi e Mesos sono stati originariamente progettati per attività brevi di data center.
Riepilogo
Dalla grande architettura, tutta l’architettura del sistema di pianificazione è architettura Master / Slave, l’estremità slave viene installata su ogni macchina con requisiti di gestione, che viene utilizzata per raccogliere informazioni sull’host ed eseguire attività sull’host. Master è principalmente responsabile per la pianificazione delle risorse e la pianificazione delle attività. La pianificazione delle risorse ha requisiti più elevati in termini di prestazioni e la pianificazione delle attività ha requisiti più elevati in termini di scalabilità. La tendenza generale è quella di discutere i due tipi di disaccoppiamento del dovere e completarli con componenti diversi.
