Ricerca comune: Il progetto open source che riporta PageRank
Iscriviti per i nostri riassunti giornalieri del panorama di search marketing in continua evoluzione.
Nota: Inviando questo modulo, accetti i termini di Third Door Media. Rispettiamo la tua privacy.

Negli ultimi anni, Google ha lentamente ridotto la quantità di dati disponibili per i professionisti SEO. Prima erano i dati delle parole chiave, poi PageRank score. Ora è un volume di ricerca specifico da AdWords (a meno che tu non stia spendendo un po ‘ di moola). Puoi leggere di più su questo nell’eccellente articolo di Russ Jones che descrive in dettaglio l’impatto delle ricerche e delle intuizioni della sua azienda sui dati clickstream per la disambiguazione del volume.
Un elemento che abbiamo ottenuto veramente coinvolti in recente è dati di scansione comuni. Ci sono diverse squadre nel nostro settore che hanno utilizzato questi dati per qualche tempo, quindi mi sono sentito un po ‘ in ritardo per il gioco. Common Crawl data è un progetto open source che raschia l’intera Internet a intervalli regolari. Per fortuna, Amazon, essendo la grande azienda che è, ha lanciato per memorizzare i dati per renderli disponibili a molti senza gli alti costi di archiviazione.
Oltre ai dati di scansione comuni, c’è un non-profit chiamato Common Search la cui missione è quella di creare un open source alternativo e motore di ricerca trasparente — l’opposto, per molti aspetti, di Google. Questo ha suscitato il mio interesse perché significa che tutti noi possiamo giocare, modificare e manipolare i segnali per imparare come i motori di ricerca operano senza l’enorme investimento di tempo di partire da ground zero.
Dati di ricerca comuni
Attualmente, Common Search utilizza le seguenti fonti di dati per calcolare le loro classifiche di ricerca (Questo è preso direttamente dal loro sito web):
- Common Crawl: Il più grande repository aperto di dati web crawl. Questa è attualmente la nostra fonte unica di dati di pagina grezzi.
- Wikidata: Un database gratuito e collegato che funge da archiviazione centrale per i dati strutturati di molti progetti Wikimedia come Wikipedia, Wikivoyage e Wikisource.
- Lista nera UT1: Gestita da Fabrice Prigent dell’Université Toulouse 1 Capitole, questa lista nera categorizza domini e URL in diverse categorie, tra cui “adulto” e “phishing.”
- DMOZ: Noto anche come Open Directory Project, è la directory web più antica e più grande ancora in vita. Anche se i suoi dati non sono così affidabili come lo era in passato, lo usiamo ancora come fonte di segnali e metadati.
- Web Data Commons Hyperlink Graphs: grafici di tutti i collegamenti ipertestuali da un archivio di scansione comune del 2012. Attualmente stiamo usando il suo file di centralità armonica come segnale di classifica temporaneo sui domini. Abbiamo in programma di eseguire la nostra analisi del grafico web nel prossimo futuro.
- Alexa top 1M sites: Alexa classifica i siti Web in base a una misura combinata di visualizzazioni di pagina e utenti unici del sito. È noto per essere demograficamente di parte. Lo stiamo usando come un segnale di classifica temporaneo sui domini.
Common Search ranking
Oltre a queste fonti di dati, nell’investigare il codice, utilizza anche la lunghezza dell’URL, la lunghezza del percorso e il PageRank del dominio come segnali di classifica nel suo algoritmo. Ecco, da luglio, Common Search ha avuto i propri dati sul PageRank a livello di host, e tutti ci siamo persi.
Arriverò al PageRank (PR) in un momento, ma è interessante rivedere il codice di Common Crawl, in particolare il ranker.py porzione si trova qui, perché si può davvero entrare nel posto di guida con tweaking i pesi dei segnali che utilizza per classificare le pagine:
signal_weights = {"url_total_length": 0.01,"url_path_length": 0.01,"url_subdomain": 0.1,"alexa_top1m": 5,"wikidata_url": 3,"dmoz_domain": 1,"dmoz_url": 1,"webdatacommons_hc": 1,"commonsearch_host_pagerank": 1}
Di particolare nota, inoltre, è che Common Search utilizza BM25 come misura di somiglianza della parola chiave per documentare il corpo e i metadati. BM25 è una misura migliore di TF-IDF perché tiene conto della lunghezza del documento, il che significa che un documento di 200 parole che ha la parola chiave cinque volte è probabilmente più rilevante di un documento di 1.500 parole che ha lo stesso numero di volte.
Vale anche la pena di dire che il numero di segnali qui è molto rudimentale e ovviamente manca di molti dei perfezionamenti (e dati) che Google ha integrato nel loro algoritmo di ranking di ricerca. Una delle cose chiave su cui stiamo lavorando è utilizzare i dati disponibili in Common Crawl e l’infrastruttura di Common Search per eseguire la ricerca vettoriale degli argomenti per contenuti rilevanti in base alla semantica, non solo alla corrispondenza delle parole chiave.
Su PageRank
Nella pagina qui, puoi trovare i link al PageRank a livello host per la scansione comune di giugno 2016. Sto usando quello intitolato pagerank-top1m.txt.gz (top 1 milione) perché l’altro file è 3GB e oltre 112 milioni di domini. Anche in R, non ho abbastanza macchina per caricarlo senza tappare.
Dopo il download, dovrai portare il file nella tua directory di lavoro in R. I dati del PageRank dalla Ricerca comune non sono normalizzati e inoltre non sono nel formato 0-10 pulito in cui siamo tutti abituati a vederlo. La ricerca comune utilizza ” max (0, min(1, float (rank) / 244660.58)) ” — fondamentalmente, il rango di un dominio diviso per il rango di Facebook-come metodo per tradurre i dati in una distribuzione tra 0 e 1. Ma questo lascia alcune lacune definite, in quanto ciò lascerebbe il PageRank di Linkedin come 1.4 quando viene scalato di 10.

Il seguente codice caricherà il set di dati e aggiungerà una colonna PR con un PR approssimato meglio:
#Grab the datadf <- read.csv("pagerank-top1m.txt", header = F, sep = " ")#Log NormalizelogNorm <- function(x){ #Normalize x <- (x-min(x))/(max(x)-min(x)) 10 / (1 - (log10(x)*.25))}#Append a Column named PR to the datasetdf$pr <- (round(logNorm(df$V2),digits = 0))
Abbiamo dovuto giocare un po ‘ con i numeri per farlo da qualche parte vicino (per diversi campioni di domini che ho ricordato il PR per) al vecchio Google PR. Di seguito sono riportati alcuni risultati di PageRank di esempio:
- en.wikipedia.org (8)
- searchengineland.com (6)
- consultwebs.com (5)
- youtube.com (9)
- moz.com (6)
Ecco una trama di 100.000 campioni casuali. Il punteggio PageRank calcolato è lungo l’asse Y e il punteggio di ricerca comune originale è lungo l’asse X.
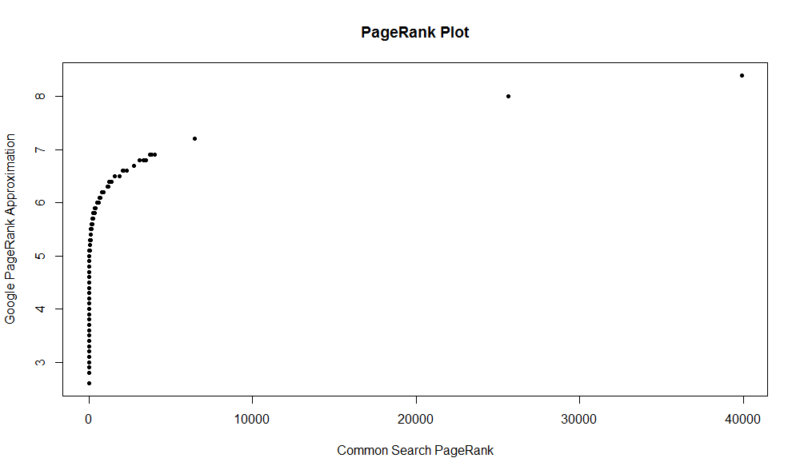
Per ottenere i tuoi risultati, puoi eseguire il seguente comando in R (basta sostituire il tuo dominio):
df

Tieni presente che questo set di dati ha solo il primo milione di domini per PageRank, quindi su 112 milioni di domini che la ricerca comune indicizza, c’è una buona probabilità che il tuo sito non sia lì se non ha un buon profilo di collegamento. Inoltre, questa metrica non include alcuna indicazione della nocività dei link, solo un’approssimazione della popolarità del tuo sito rispetto ai link.
Ricerca comune è un ottimo strumento e una grande base. Non vedo l’ora di essere più coinvolto con la comunità lì e, auspicabilmente, imparare a capire meglio i dadi e bulloni dietro i motori di ricerca lavorando effettivamente su uno. Con R e un po ‘ di codice, puoi avere un modo rapido per controllare PR per un milione di domini in pochi secondi. Spero vi sia piaciuto!
Iscriviti per i nostri riassunti giornalieri del panorama di search marketing in continua evoluzione.
Nota: Inviando questo modulo, accetti i termini di Third Door Media. Rispettiamo la tua privacy.
Circa l’autore

JR Oakes è il direttore senior della ricerca SEO tecnica presso Locomotive. In precedenza è stato direttore della SEO tecnica presso l’agenzia Adapt Partners. Lavora con i clienti su una vasta gamma di fronti, tra cui problemi tecnici, prestazioni, CTR, capacità di scansione, contenuti e analisi dei dati. JR ama testare, codificare e prototipare soluzioni a difficili problemi di search marketing. Quando non lavora, gli piace leggere sulle tecnologie emergenti, suonare il basso, guardare il basket del college, cucinare e passare il tempo con i suoi amici e familiari. Egli è anche uno dei co-organizzatori del Raleigh SEO Meetup, Raleigh SEO Conference, e RTP SEO Meetup.