Scalable, Distributed Secondary Indicizzazione in Scylla

Il modello di dati in Scylla e Apache Cassandra partizioni dati tra i nodi del cluster utilizzando una chiave di partizione, che è definito dallo schema del database. L’utilizzo di una chiave di partizione fornisce un modo efficace per cercare le righe utilizzando la chiave di partizione perché è possibile trovare il nodo che possiede la riga eseguendo l’hash della chiave di partizione. Sfortunatamente, questo significa anche che trovare una riga utilizzando una chiave non di partizione richiede una scansione completa della tabella che è inefficiente. Gli indici secondari sono un meccanismo in Apache Cassandra che consente ricerche efficienti su chiavi non divisorie creando un indice.
In questo post del blog imparerai:
- Come Apache Cassandra implementa gli Indici Secondari utilizzo di locali di indicizzazione
- Perché abbiamo deciso di adottare una diversa strategia di attuazione per Scilla utilizzo globale di indicizzazione
- Come globale di indicizzazione colpisce come si dovrebbe usare Secondaria di Indicizzazione
- Come creare il vostro proprio Indici Secondari e loro utilizzo nell’applicazione CQL query
Sfondo
La dimensione di un indice è direttamente proporzionale alla dimensione dei dati indicizzati. Poiché i dati in Scylla e Apache Cassandra sono distribuiti su più nodi, non è pratico memorizzare l’intero indice su un singolo nodo. Apache Cassandra implementa indici secondari come indici locali, il che significa che l’indice è memorizzato sullo stesso nodo dei dati che vengono indicizzati da quel nodo. Il vantaggio di un indice locale è che le scritture sono molto veloci, ma il rovescio della medaglia è che le letture devono potenzialmente interrogare ogni nodo per trovare l’indice su cui eseguire una ricerca, il che rende gli indici locali non scalabili a cluster di grandi dimensioni. Oltre agli indici secondari nativi, Apache Cassandra ha anche un altro schema di indicizzazione locale, Sstable Attached Secondary Index (SASI), che supporta query e ricerche complesse. Tuttavia, dal punto di vista della scalabilità, ha esattamente le stesse caratteristiche degli indici secondari originali.
Le viste materializzate in Scylla e Apache Cassandra sono un meccanismo per denormalizzare automaticamente i dati da una tabella di base a una tabella di visualizzazione utilizzando una chiave di partizione diversa. Questo risolve il problema di scalabilità degli indici locali ma ha un costo di archiviazione perché è necessario duplicare l’intera tabella nel peggiore dei casi. Le viste materializzate non sostituiscono quindi gli indici secondari per tutti i casi d’uso. Tuttavia, le viste materializzate forniscono l’infrastruttura necessaria per implementare indici secondari utilizzando l’indicizzazione globale, che è l’approccio di implementazione adottato per Scylla.
Indicizzazione globale
Scylla adotta un approccio diverso da Apache Cassandra e implementa indici secondari utilizzando l’indicizzazione globale. Con l’indicizzazione globale, viene creata una vista materializzata per ciascun indice. La vista Materializzata ha la colonna indicizzata come chiave di partizione e la chiave primaria (chiave di partizione e chiavi di clustering) della riga indicizzata come chiavi di clustering. Scylla interrompe le query indicizzate in due parti: (1) una query sulla tabella indice per recuperare le chiavi di partizione per la tabella indicizzata e (2) una query alla tabella indicizzata utilizzando le chiavi di partizione recuperate. Il vantaggio di questo approccio è che possiamo utilizzare il valore della colonna indicizzata per trovare la riga della tabella indice corrispondente nel cluster in modo che le letture siano scalabili. Lo svantaggio dell’approccio è che le scritture sono più lente rispetto all’indicizzazione locale a causa di tutto il sovraccarico dovuto al mantenimento della visualizzazione dell’indice aggiornata.
L’interrogazione su una colonna indicizzata appare come segue. Supponiamo un tavolo che assomiglia a questo:
E una query sulla colonna email, che non è una chiave di partizione, ma ha un indice:
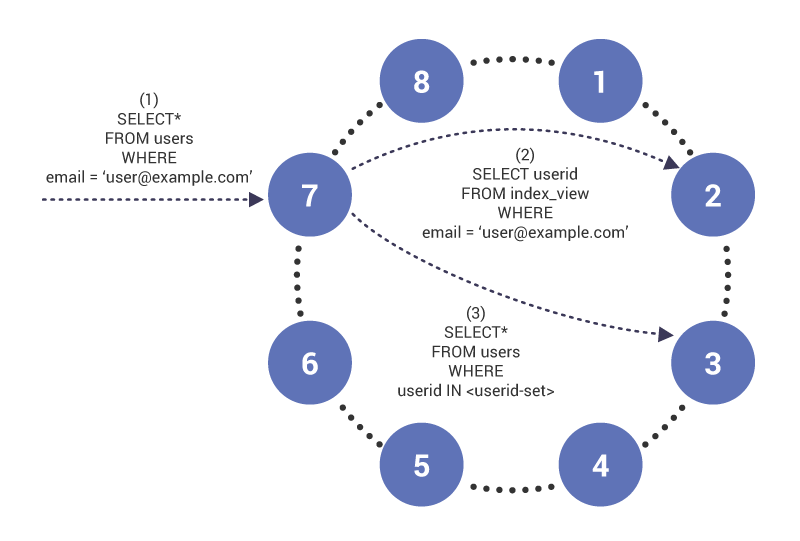
Nella fase (1), la query arriva sul nodo 7, che funge da coordinatore per la query. Il nodo nota che stiamo interrogando su una colonna indicizzata e quindi in fase (2), emette una tabella read to index sul nodo 2, che ha la riga della tabella index per “”. La query restituisce un set di ID utente utilizzati nella fase (3) per recuperare il contenuto della tabella indicizzata.
Esempio
Dobbiamo prima creare uno schema. In questo esempio, abbiamo una tabella che rappresenta le informazioni utente con userid come chiave di partizione e nome, email e paese come colonne regolari:
Quindi popoliamo la tabella con alcuni dati di test generati con Mockaroo:
Gli indici secondari sono progettati per consentire l’interrogazione efficiente di colonne chiave non divisorie. Mentre Apache Cassandra supporta anche query su colonne di chiavi non di partizione utilizzando ALLOW FILTERING, questo è molto inefficiente (richiede la scansione dell’intera tabella) e attualmente non supportato da Scylla (vedere il numero 2200 per i dettagli).
È possibile indicizzare le colonne della tabella utilizzando l’istruzione CREATE INDEX. Ad esempio, per creare indici per le colonne e-mail e paese, eseguire le seguenti istruzioni CQL:
Scylla crea automaticamente una vista materializzata che ha la colonna indicizzata come chiave di partizione e la chiave primaria della tabella di destinazione (chiave di partizione e chiavi di clustering) come chiavi di clustering.
Ad esempio, la vista Materializzata per l’indice nella colonna email appare come segue:
Se la vista sopra sarebbe stata creata come una tabella normale, sarebbe effettivamente simile a quanto segue:
La colonna email viene utilizzata come chiave di partizione per la tabella indice e useridè inclusa come chiave di clustering, che ci consente di trovare in modo efficiente le chiavi di partizione per la tabella di destinazione utilizzando solo email.
È possibile utilizzare il comando DESCRIBE per visualizzare l’intero schema per la tabella ks.users, inclusi gli indici e le viste creati:
Ora con l’indice secondario in posizione, puoi interrogare le colonne indicizzate come se fossero chiavi di partizione:
Abbiamo finito con l’esempio!
Quando usare gli indici secondari?
Gli indici secondari sono (per lo più) trasparenti per l’applicazione. Le query hanno accesso a tutte le colonne della tabella ed è possibile aggiungere e rimuovere gli indici senza modificare l’applicazione. Gli indici secondari possono anche avere meno overhead di archiviazione rispetto alle viste materializzate perché gli indici secondari devono solo duplicare la colonna indicizzata e la chiave primaria, non le colonne interrogate come con una vista materializzata. Inoltre, per lo stesso motivo, gli aggiornamenti possono essere più efficienti con gli indici secondari perché solo le modifiche alla chiave primaria e alla colonna indicizzata causano un aggiornamento nella vista indice. Nel caso di una vista Materializzata, un aggiornamento a una qualsiasi delle colonne visualizzate nella vista richiede l’aggiornamento della vista di supporto.
Come sempre, la decisione se utilizzare indici secondari o Viste materializzate dipende in realtà dai requisiti della tua applicazione. Se è necessario il massimo delle prestazioni e è probabile che si esegua una query su un set specifico di colonne, è necessario utilizzare le viste materializzate. Tuttavia, se l’applicazione deve interrogare diversi set di colonne, gli indici secondari sono una scelta migliore perché possono essere aggiunti e rimossi con meno overhead di archiviazione a seconda delle esigenze dell’applicazione.
Vuoi saperne di più sugli indici secondari? Scopri la mia presentazione da Scylla Summit 2017 su SlideShare. Se vuoi provare questa funzione, ci si aspetta che sia nella prossima versione di Scylla 2.2.