Cloud Data Warehouse vs traditionele Data Warehouse Concepten
Cloud-based Data Warehouse zijn de nieuwe norm. Voorbij zijn de dagen waar uw bedrijf had om hardware te kopen, serverruimtes te creëren en huren, trainen, en onderhouden van een toegewijd team van medewerkers om het te runnen. Nu, met een paar klikken op uw laptop en een creditcard, kunt u toegang krijgen tot vrijwel onbeperkte rekenkracht en opslagruimte.
dit betekent echter niet dat traditionele Data warehouse ideeën dood zijn. Klassieke Data warehouse theorie onderbouwt het meeste van wat cloud-based data warehouses doen.
In dit artikel leggen we u de traditionele concepten voor datawarehouses uit die u moet kennen en de belangrijkste cloud-concepten uit een selectie van de toproviders: Amazon, Google en Panoply. Tot slot zullen we afsluiten met een kosten-batenanalyse van traditionele vs.cloud Data warehouses, zodat u weet welke voor u geschikt is.
laten we beginnen.
- traditionele concepten voor datawarehouses
- feiten, dimensies en maatregelen
- normalisatie en denormalisatie
- gegevensmodellen
- Fact Table
- Star Schema vs. Snowflake Schema
- OLAP vs. OLTP
- three Tier Architecture
- Virtual Data Warehouse / Data Mart
- Kimball vs. Inmon
- ETL vs. ELT
- Enterprise Data Warehouse
- Cloud Data Warehouse Concepten
- Cloud Data Warehouse Concepts-Amazon Redshift
- Clusters
- knooppunten
- partities / Slices
- zuilvormige opslag
- compressie
- gegevens laden
- Cloud Database Warehouse-Google BigQuery
- serverloze Service
- Colossus bestandssysteem
- Dremel Execution Engine
- Delen van gegevens
- Streaming en batch inname
- Cloud Data Warehouse Concepts-Panoply
- primaire sleutels
- incrementele sleutels
- geneste gegevens
- Geschiedenistabellen
- transformaties
- String formaten
- gegevensbescherming
- Toegangscontrole
- IP Whitelisting
- conclusie: traditionele Versus Data Warehouse concepten in het kort
- traditionele concepten voor datawarehouses
- Cloud Data Warehouse Concepts-Amazon Redshift als voorbeeld
- Cloud Data Warehouse Concepts-BigQuery als voorbeeld
- traditionele kosten-batenanalyse in de Cloud
- meer informatie over datawarehouses
traditionele concepten voor datawarehouses
een datawarehouse is een systeem dat gegevens uit een breed scala van bronnen binnen een organisatie verzamelt. Datawarehouses worden gebruikt als gecentraliseerde dataopslagplaatsen voor analytische en rapportagedoeleinden.
een traditioneel datawarehouse bevindt zich ter plaatse bij uw kantoren. Je koopt de hardware, de serverruimtes en huurt het personeel in om het te runnen. Ze worden ook on-premise, on-prem of (grammaticaal incorrect) on-premise data warehouses genoemd.
feiten, dimensies en maatregelen
de belangrijkste bouwstenen van informatie in een datawarehouse zijn feiten, dimensies en maatregelen.
een feit is het deel van uw gegevens dat een specifieke gebeurtenis of transactie aangeeft. Bijvoorbeeld, als uw bedrijf verkoopt bloemen, sommige feiten die u zou zien in uw data warehouse zijn:
- Verkocht 30 Rozen in de winkel voor $ 19.99
- bestelde 500 nieuwe bloempotten uit China voor $ 1500
- betaald salaris van kassier voor deze maand $1000
verschillende getallen kunnen elk feit beschrijven, en we noemen deze getallen maten. Sommige maatregelen om het feit te beschrijven ‘bestelde 500 nieuwe bloempotten uit China voor $ 1500’ zijn:
- bestelde hoeveelheid-500
- kosten – $1500
wanneer analisten met gegevens werken, voeren ze berekeningen uit op metingen (bijvoorbeeld Som, maximum, gemiddelde) om inzichten te verzamelen. U wilt bijvoorbeeld het gemiddelde aantal bloempotten weten dat u elke maand bestelt.
een dimensie categoriseert feiten en maten en biedt gestructureerde etiketteringsinformatie voor hen – anders zouden ze gewoon een verzameling van ongeordende getallen zijn! Sommige afmetingen om het feit te beschrijven ‘bestelde 500 nieuwe bloempotten uit China voor $ 1500’ zijn:
- land gekocht in-China
- tijd gekocht-13: 00
- verwachte aankomstdatum-6 juni
u kunt geen berekeningen uitvoeren op afmetingen expliciet, en dit zou waarschijnlijk niet erg nuttig zijn-hoe kunt u de ‘gemiddelde aankomstdatum voor bestellingen’vinden? Het is echter mogelijk om vanuit dimensies nieuwe maatregelen te creëren, en deze zijn nuttig. Als u bijvoorbeeld het gemiddelde aantal dagen tussen de orderdatum en de aankomstdatum kent, kunt u beter voorraadaankopen plannen.
normalisatie en denormalisatie
normalisatie is het proces van het efficiënt organiseren van gegevens in een datawarehouse (of een andere plaats waar gegevens worden opgeslagen). De belangrijkste doelen zijn het verminderen van gegevensredundantie-dat wil zeggen, het verwijderen van dubbele gegevens – en het verbeteren van de integriteit van gegevens – dat wil zeggen, het verbeteren van de nauwkeurigheid van gegevens. Er zijn verschillende niveaus van normalisatie en er is geen consensus voor de’ beste ‘ methode. Echter, alle methoden omvatten het opslaan van afzonderlijke, maar verwante stukken van informatie in verschillende tabellen.
normalisatie heeft vele voordelen, zoals::
- sneller zoeken en sorteren op elke tabel
- eenvoudiger tabellen maken opdrachten voor het wijzigen van gegevens sneller om
- te schrijven en uit te voeren Minder redundante gegevens betekent dat u schijfruimte bespaart en dus meer gegevens kunt verzamelen en opslaan
denormalisatie is het proces van het opzettelijk toevoegen van redundante kopieën of groepen gegevens aan reeds genormaliseerde gegevens. Het is niet hetzelfde als niet-genormaliseerde gegevens. Denormalisatie verbetert de leesprestaties en maakt het veel gemakkelijker om tabellen te manipuleren in formulieren die u wilt. Wanneer analisten werken met datawarehouses, ze meestal alleen uit te voeren leest op de gegevens. Aldus, denormalized gegevens kunnen hen enorme hoeveelheden tijd en hoofdpijn besparen.
voordelen van denormalisatie:
- minder tabellen minimaliseren de behoefte aan tabelkoppelingen, wat de workflow van data-analisten versnelt en hen leidt tot het ontdekken van meer nuttige inzichten in de data
- minder tabellen vereenvoudigen query’ s die leiden tot minder bugs
gegevensmodellen
het zou enorm inefficiënt zijn om al uw gegevens in één grote tabel op te slaan. Zo, uw data warehouse bevat veel tabellen die u kunt samenvoegen om specifieke informatie te krijgen. De hoofdtabel heet een fact table, en dimensietafels omringen het.
de eerste stap in het ontwerpen van een datawarehouse is het bouwen van een conceptueel datamodel dat de gegevens definieert die u wilt en de high-level relaties tussen hen.
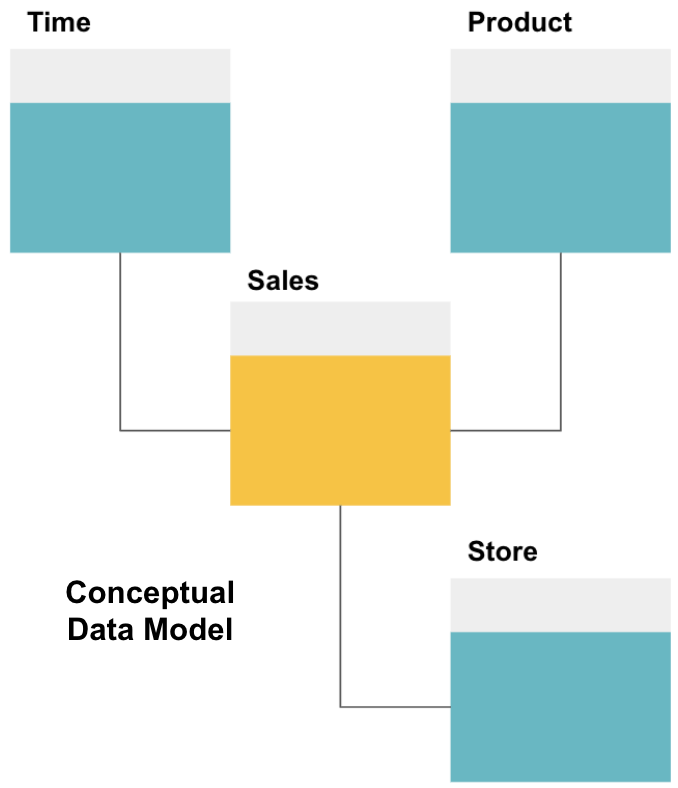
hier hebben we het conceptuele model gedefinieerd. We slaan verkoopgegevens op en hebben drie extra tabellen-tijd, Product en winkel – die extra, meer gedetailleerde informatie over elke verkoop bieden. De feittabel is Verkoop, en de anderen zijn dimensietabellen.
de volgende stap is het definiëren van een logisch datamodel. Dit model beschrijft de gegevens in detail in gewoon Engels zonder zich zorgen te maken over hoe het in code te implementeren.
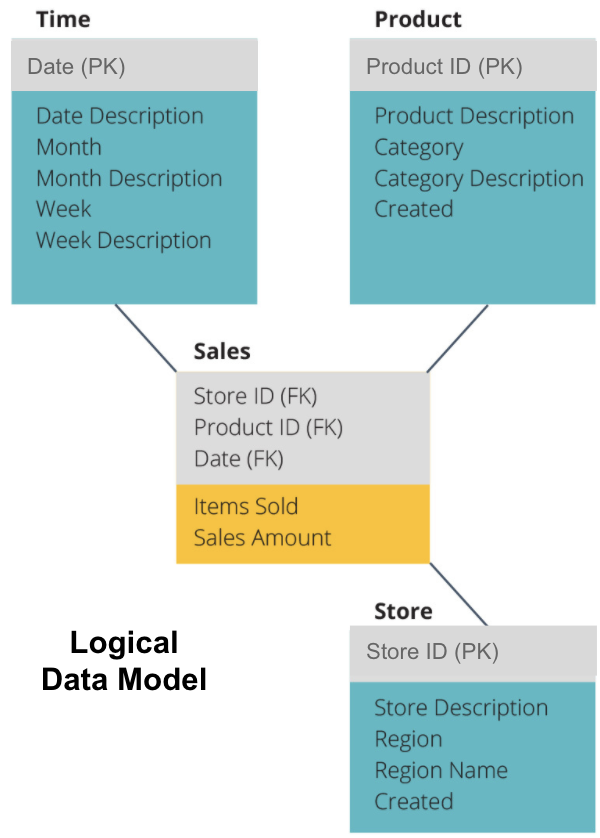
nu hebben we ingevuld welke informatie elke tabel bevat in gewoon Engels. Elk van de dimensietabellen van tijd, Product en Opslag toont de primaire sleutel (PK) in het grijze kader en de overeenkomstige gegevens in de blauwe kader. De verkoop tabel bevat drie buitenlandse sleutels (FK), zodat het snel kan aansluiten bij de andere tabellen.
de laatste fase is het maken van een fysiek gegevensmodel. Dit model vertelt u hoe u het datawarehouse in code kunt implementeren. Het definieert tabellen, hun structuur, en de relatie tussen hen. Het specificeert ook gegevenstypen voor kolommen, en alles wordt genoemd zoals het zal zijn in de definitieve datawarehouse, dat wil zeggen, alle caps en verbonden met underscores. Tot slot begint elke dimensietabel met DIM_, en elke feittabel begint met FACT_.
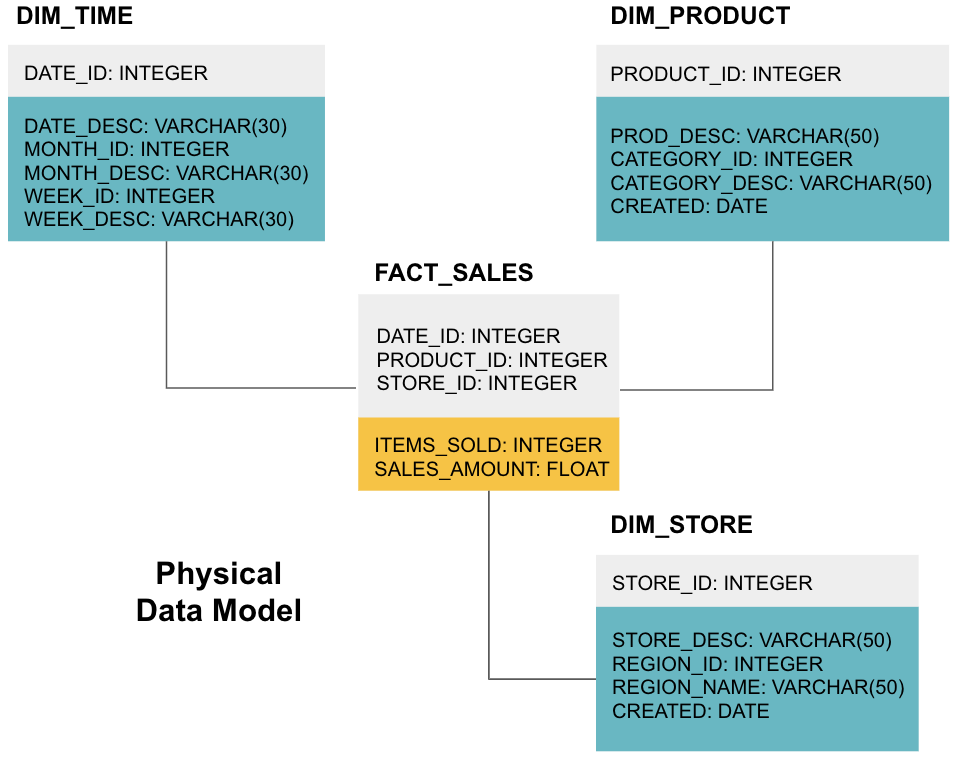
nu weet je hoe je een datawarehouse ontwerpt, maar er zijn een paar nuances aan feiten en dimensietabellen die we hierna zullen uitleggen.
Fact Table
elke zakelijke functie-zoals verkoop, marketing, financiën-heeft een overeenkomstige fact table.
Fact tables hebben twee soorten kolommen: dimension columns en fact columns. Dimensiekolommen – grijs gekleurd in onze voorbeelden-bevatten buitenlandse sleutels (FK) die u gebruikt om een feittabel aan te sluiten bij een dimensietabel. Deze vreemde sleutels zijn de primaire sleutels (PK) voor elk van de dimensietabellen. Fact columns – geel gekleurd in onze voorbeelden-bevatten de werkelijke gegevens en maatregelen die moeten worden geanalyseerd, bijvoorbeeld het aantal verkochte items en de totale waarde van de omzet in dollar.
een factless fact table is een specifiek type fact table dat alleen dimensiekolommen heeft. Dergelijke tabellen zijn handig voor het bijhouden van gebeurtenissen, zoals student aanwezigheid of werknemer verlof, als de afmetingen vertellen u alles wat u moet weten over de gebeurtenissen.
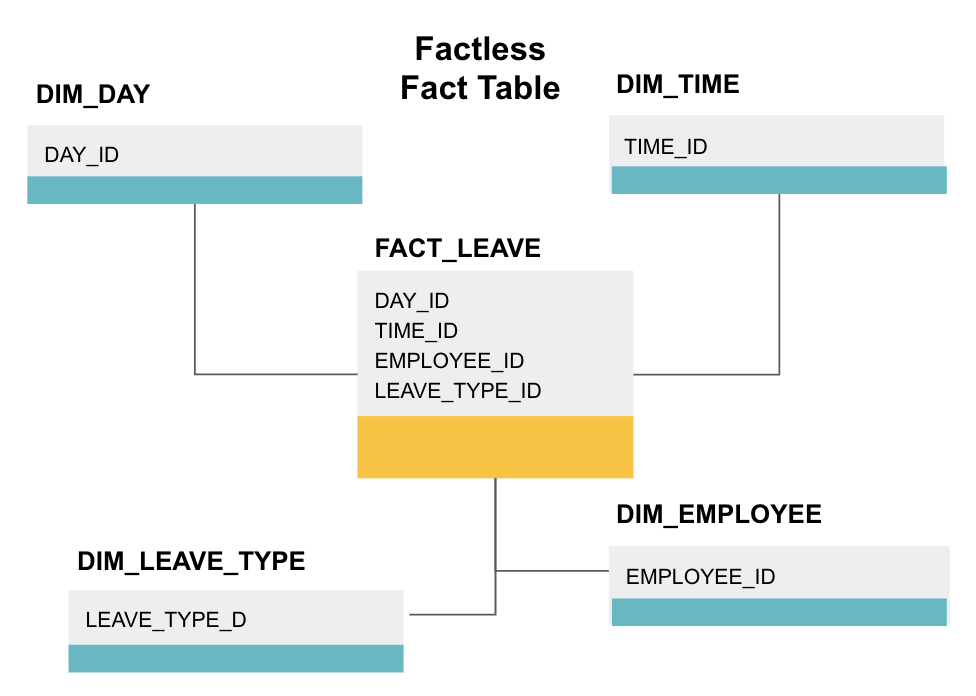
de bovenstaande factless fact table tracks werknemer verlof. Er zijn geen feiten omdat je gewoon moet weten:
- welke dag ze vrij waren (DAY_ID).
- hoe lang ze uit waren (TIME_ID).
- die met verlof was (EMPLOYEE_ID).
- hun reden om met verlof te zijn, bijv., ziekte, vakantie, doktersafspraak, enz. (LEAVE_TYPE_ID).
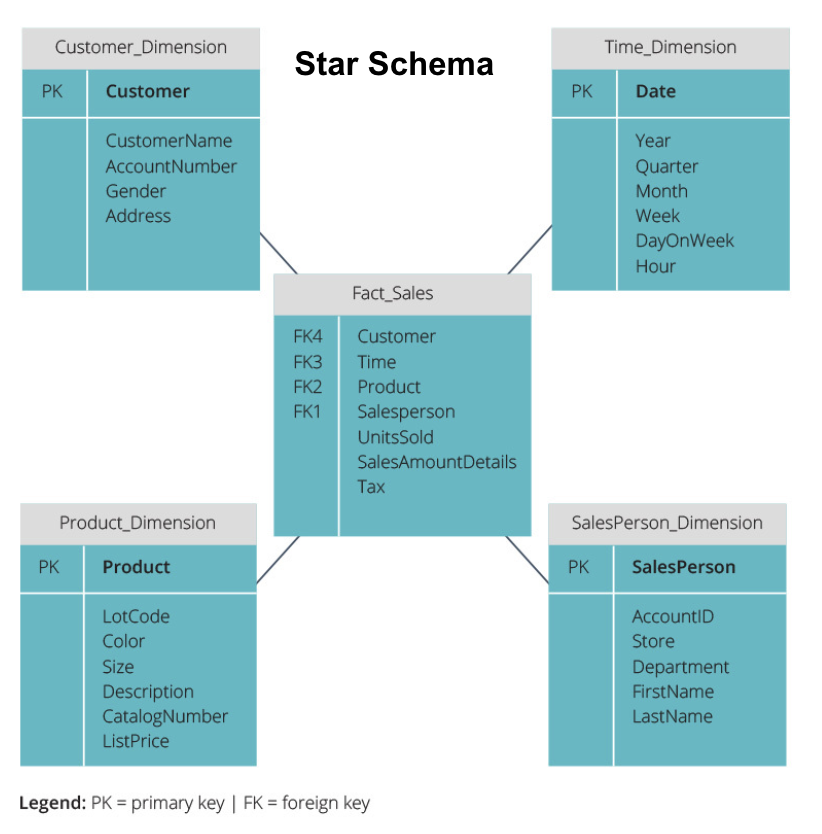
Star Schema vs. Snowflake Schema
de bovenstaande datawarehouses hebben allemaal een vergelijkbare lay-out. Dit is echter niet de enige manier om ze te regelen.
de twee meest gebruikte schema ‘ s voor het organiseren van datawarehouses zijn star en snowflake. Beide methoden gebruiken dimensietabellen die de informatie in een feittabel beschrijven.
het sterschema neemt de informatie uit de fact-tabel en splitst deze in gedenormaliseerde dimensietabellen. De nadruk voor het sterschema ligt op query snelheid. Slechts één join is nodig om feiten tabellen te koppelen aan elke dimensie, dus het opvragen van elke tabel is eenvoudig. Omdat de tabellen echter gedenormaliseerd zijn, bevatten ze vaak herhaalde en redundante gegevens.
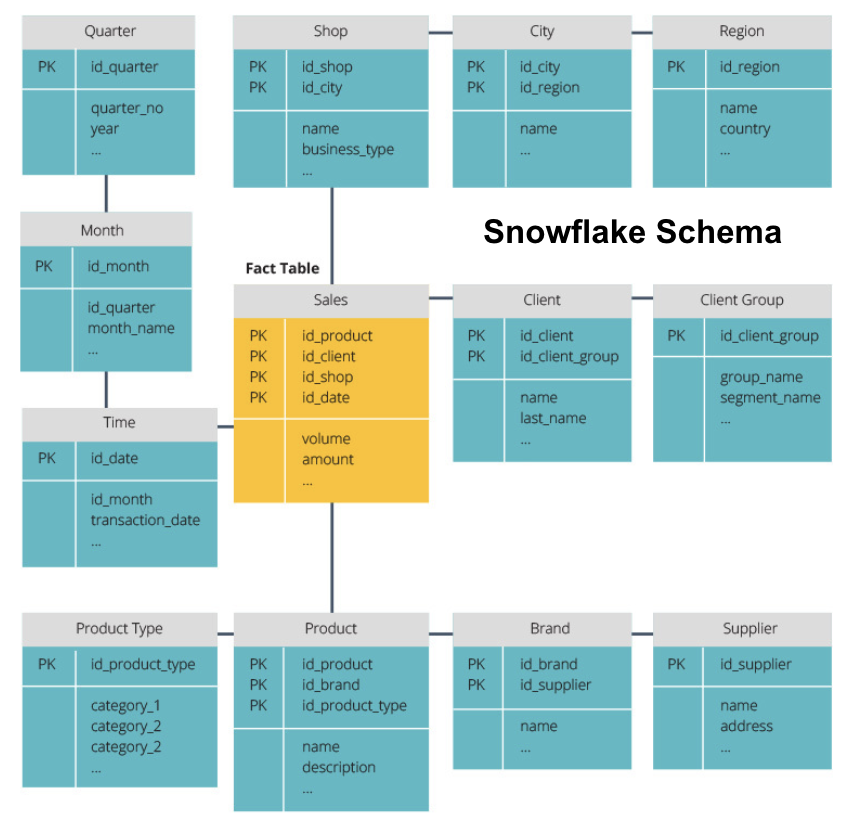
het Sneeuwvlok schema splitst de feittabel in een reeks genormaliseerde dimensietafels. Normaliseren creëert meer dimensietabellen en vermindert zo problemen met gegevensintegriteit. Echter, querying is meer uitdagend met behulp van de sneeuwvlok schema omdat je meer tabel joins nodig hebt om toegang te krijgen tot de relevante gegevens. Zo, je hebt minder redundante gegevens, maar het is moeilijker om toegang te krijgen.
nu zullen we uitleggen wat meer fundamentele data warehouse Concepten.
OLAP vs. OLTP
on-line transaction processing (OLTP) wordt gekenmerkt door short write transacties die de front-end toepassingen van de gegevensarchitectuur van een onderneming omvatten. OLTP databases benadrukken snelle query verwerking en alleen omgaan met de huidige gegevens. Bedrijven gebruiken deze om informatie voor bedrijfsprocessen vast te leggen en brongegevens te leveren voor het datawarehouse.
Online analytical processing (OLAP) stelt u in staat om complexe leesquery ‘ s uit te voeren en zo een gedetailleerde analyse van historische transactiegegevens uit te voeren. OLAP-systemen helpen bij het analyseren van de gegevens in het datawarehouse.
three Tier Architecture
traditionele datawarehouses zijn doorgaans gestructureerd in drie niveaus:
- onderste laag: een databaseserver, meestal een RDBMS, die gegevens uit verschillende bronnen extraheert met behulp van een gateway. Gegevensbronnen ingevoerd in dit niveau omvatten operationele databases en andere soorten front-end gegevens zoals CSV en JSON-bestanden.
- Middle Tier: een OLAP-server die ofwel
- de bewerkingen direct implementeert, ofwel
- de bewerkingen op multidimensionale gegevens koppelt aan standaard relationele bewerkingen, bijvoorbeeld het afvlakken van XML-of JSON-gegevens in rijen binnen tabellen.
- Top Tier: de querying en rapportage tools voor data-analyse en business intelligence.
Virtual Data Warehouse / Data Mart
Virtual data warehousing maakt gebruik van gedistribueerde query ‘ s op verschillende databases, zonder de gegevens te integreren in één fysiek Data warehouse.
datamart ‘ s zijn subsets van datawarehouses die gericht zijn op specifieke bedrijfsfuncties, zoals verkoop of financiën. Een datawarehouse combineert doorgaans informatie van verschillende data marts in meerdere zakelijke functies. Toch, een data mart bevat gegevens uit een set van bronsystemen voor een zakelijke functie.
Kimball vs. Inmon
er zijn twee benaderingen voor datawarehouse design, voorgesteld door Bill Inmon en Ralph Kimball. Bill Inmon is een Amerikaanse computerwetenschapper die wordt erkend als de vader van het Data warehouse. Ralph Kimball is een van de oorspronkelijke architecten van data warehousing en heeft verschillende boeken over het onderwerp geschreven.
de twee deskundigen waren het oneens over de structuur van datawarehouses. Dit conflict heeft geleid tot twee denkrichtingen.
de Inmon-benadering is een top-down-ontwerp. Met de Inmon methodologie wordt het datawarehouse als eerste gecreëerd en wordt het gezien als het centrale onderdeel van de analytische omgeving. Data wordt vervolgens samengevat en gedistribueerd vanuit het gecentraliseerde magazijn naar een of meer afhankelijke data marts.
de Kimball-benadering is gebaseerd op het ontwerp van datawarehouses. In deze architectuur creëert een organisatie aparte data marts, die inzicht bieden in afzonderlijke afdelingen binnen een organisatie. Het Data warehouse is de combinatie van deze data marts.
ETL vs. ELT
Extract, Transform, Load (ETL) beschrijft het proces van het extraheren van de gegevens uit bronsystemen (meestal transactionele systemen), het converteren van de gegevens naar een formaat of structuur die geschikt is voor querying en analyse, en uiteindelijk het laden van de gegevens in het datawarehouse. ETL maakt gebruik van een aparte staging database en past een reeks regels of functies toe op de geëxtraheerde gegevens vóór het laden.
Extract, Load, Transform (ELT) is een andere benadering van het laden van gegevens. ELT neemt de gegevens uit verschillende bronnen en laadt deze rechtstreeks in het doelsysteem, zoals het datawarehouse. Het systeem transformeert vervolgens de geladen gegevens on-demand om analyse mogelijk te maken.
ELT biedt sneller laden dan ETL, maar het vereist een krachtig systeem om de datatransformaties op aanvraag uit te voeren.
Enterprise Data Warehouse
een enterprise data warehouse is bedoeld als een uniform, gecentraliseerd warehouse dat alle transactionele informatie in de organisatie bevat, zowel actuele als historische. Een enterprise Data warehouse moet gegevens bevatten uit alle vakgebieden die verband houden met het bedrijf, zoals marketing, verkoop, financiën en human resources.
dit zijn de kernideeën van de traditionele datawarehouses. Nu, laten we eens kijken naar wat cloud Data warehouses hebben toegevoegd op de top van hen.
Cloud Data Warehouse Concepten
Cloud Data warehouses zijn nieuw en veranderen voortdurend. Om hun fundamentele concepten het beste te begrijpen, is het het beste om te leren over de toonaangevende cloud data warehouse-oplossingen.
drie toonaangevende cloud data warehouse-oplossingen zijn Amazon Redshift, Google BigQuery en Panoply. Hieronder leggen we fundamentele concepten uit van elk van deze services om u een algemeen inzicht te geven in hoe moderne datawarehouses werken.
Cloud Data Warehouse Concepts-Amazon Redshift
de volgende concepten worden expliciet gebruikt in het Amazon Redshift cloud Data warehouse, maar kunnen in de toekomst van toepassing zijn op aanvullende data warehouse-oplossingen op basis van Amazon infrastructure.
Clusters
Amazon Redshift baseert zijn architectuur op clusters. Een cluster is gewoon een groep gedeelde computing resources, genaamd nodes.
knooppunten
knooppunten zijn computerbronnen die CPU -, RAM-en harde schijfruimte hebben. Een cluster dat twee of meer knooppunten bevat, bestaat uit een leader-knooppunt en knooppunten berekenen.
Leader-knooppunten communiceren met clientprogramma ‘s en compileren code om query’ s uit te voeren, door deze toe te wijzen aan het berekenen van knooppunten. Compute nodes voer de query ‘ s uit en retourneer de resultaten naar het leader-knooppunt. Een compute-knooppunt voert alleen query ‘ s uit die verwijzen naar tabellen die op dat knooppunt zijn opgeslagen.
partities / Slices
Amazon partities elk knooppunt berekenen in slices. Een slice ontvangt een toewijzing van geheugen en schijfruimte op het knooppunt. Meerdere slices werken parallel om de uitvoeringstijd van de query te versnellen.
zuilvormige opslag
Redshift maakt gebruik van zuilvormige opslag, wat een betere analytische query-prestaties mogelijk maakt. In plaats van records in rijen op te slaan, slaat het waarden op uit één kolom voor meerdere rijen. De volgende diagrammen maken dit duidelijker:
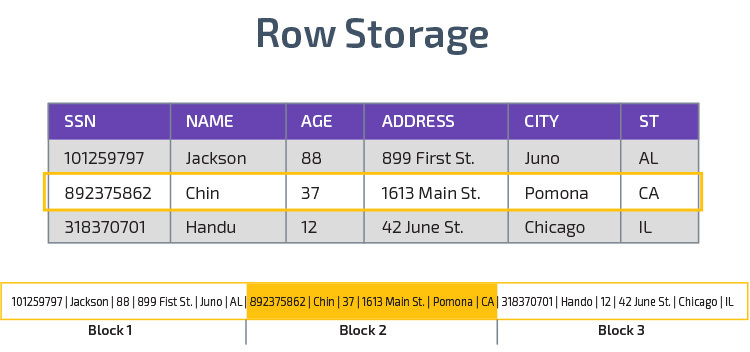
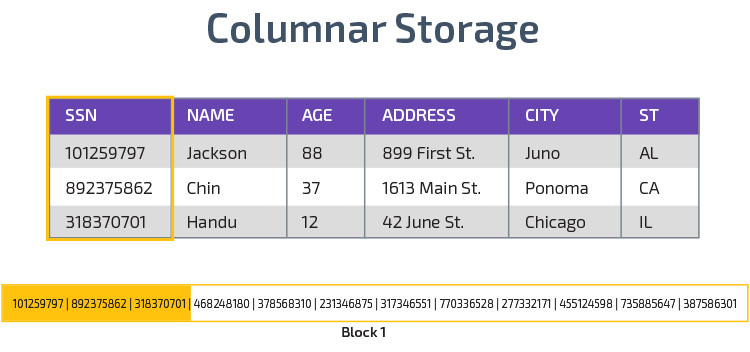
zuilvormige opslag maakt het mogelijk om gegevens sneller te lezen, wat cruciaal is voor analytische query ‘ s die veel kolommen in een dataset overspannen. Zuilvormige opslag neemt ook minder schijfruimte in beslag, omdat elk blok hetzelfde type gegevens bevat, wat betekent dat het kan worden gecomprimeerd in een specifiek formaat.
compressie
compressie vermindert de grootte van de opgeslagen gegevens. In roodverschuiving, vanwege de manier waarop gegevens worden opgeslagen, vindt compressie plaats op kolomniveau. Met Redshift kunt u informatie handmatig comprimeren wanneer u een tabel maakt, of automatisch met de opdracht Kopiëren.
gegevens laden
u kunt Redshift ‘ s COPY command gebruiken om grote hoeveelheden gegevens in het datawarehouse te laden. Het COPY commando maakt gebruik van Redshift ‘ s MPP architectuur te lezen en te laden gegevens in parallel uit bestanden op Amazon S3, van een DynamoDB tabel, of tekstuitvoer van een of meer externe hosts.
het is ook mogelijk om gegevens te streamen naar roodverschuiving, met behulp van de Amazon Kinesis Firehose service.
Cloud Database Warehouse-Google BigQuery
de volgende concepten worden expliciet gebruikt in het Google BigQuery cloud Data warehouse, maar kunnen in de toekomst van toepassing zijn op aanvullende oplossingen op basis van Google-infrastructuur.
serverloze Service
BigQuery gebruikt serverloze architectuur. Met BigQuery hoeven bedrijven geen fysieke servereenheden te beheren om hun datawarehouses uit te voeren. In plaats daarvan beheert BigQuery dynamisch de toewijzing van haar computerbronnen. Bedrijven die gebruik maken van de dienst gewoon betalen voor gegevensopslag per gigabyte en vragen per terabyte.
Colossus bestandssysteem
BigQuery gebruikt de nieuwste versie van het gedistribueerde bestandssysteem van Google, met de codenaam Colossus. Het Colossus-bestandssysteem gebruikt zuilvormige opslag-en compressie-algoritmen om gegevens optimaal op te slaan voor analytische doeleinden.
Dremel Execution Engine
de Dremel execution engine gebruikt een zuilvormige lay-out om grote opslagplaatsen van gegevens snel te bevragen. Dremel ‘s execution engine kan ad-hoc query’ s uitvoeren op miljarden rijen in seconden omdat het massaal parallelle verwerking gebruikt in de vorm van een boomarchitectuur.
de boomarchitectuur verdeelt query ‘ s over verschillende tussenliggende servers van een rootserver. De tussenliggende servers duwen de query omlaag naar leaf servers (die opgeslagen gegevens bevatten), die de gegevens parallel scannen. Op de weg back – up van de boom, elke leaf server stuurt query resultaten, en de tussenliggende servers voeren een parallelle aggregatie van gedeeltelijke resultaten.
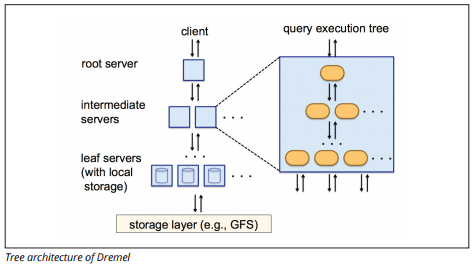
Afbeeldingsbron
Dremel stelt organisaties in staat om query ‘ s op tienduizenden servers tegelijk uit te voeren. Volgens Google kan Dremel in tientallen seconden 35 miljard rijen scannen zonder index.
Delen van gegevens
de serverloze architectuur van Google BigQuery stelt ondernemingen in staat eenvoudig gegevens met andere organisaties te delen zonder dat deze organisaties in hun eigen opslag moeten investeren.
organisaties die gedeelde gegevens willen opvragen, kunnen dit doen, en ze betalen alleen voor de vragen. Het is niet nodig om dure gedeelde datasilo ‘s te maken, buiten de datainfrastructuur van de organisatie, en de gegevens naar die silo’ s te kopiëren.
Streaming en batch inname
het is mogelijk om gegevens te laden naar BigQuery vanuit Google Cloud Storage, waaronder CSV, JSON (newline-delimited), en Avro-bestanden, evenals Google Cloud Datastore back-ups. U kunt ook gegevens rechtstreeks vanuit een leesbare gegevensbron Laden.
BigQuery biedt ook een Streaming API om gegevens in het systeem te laden met een snelheid van miljoenen rijen per seconde zonder een belasting uit te voeren. De gegevens zijn vrijwel onmiddellijk beschikbaar voor analyse.
Cloud Data Warehouse Concepts-Panoply
Panoply is een alles-in-één magazijn dat ETL combineert met een krachtig datawarehouse. Het is de gemakkelijkste manier om te synchroniseren, op te slaan en toegang te krijgen tot de gegevens van een bedrijf door het elimineren van de ontwikkeling en codering in verband met het transformeren, integreren en beheren van big data.
hieronder staan enkele van de belangrijkste concepten in het Panoply data warehouse met betrekking tot datamodellering en gegevensbescherming.
primaire sleutels
primaire sleutels zorgen ervoor dat alle rijen in uw tabellen uniek zijn. Elke tabel heeft een of meer primaire sleutels die bepalen wat een enkele unieke rij in de database vertegenwoordigt. Alle API ‘ s hebben een standaard primaire sleutel voor tabellen.
incrementele sleutels
Panoply gebruikt een incrementele sleutel om attributen te beheren voor het stapsgewijs laden van gegevens naar het datawarehouse vanuit bronnen in plaats van de hele dataset telkens opnieuw te laden wanneer er iets verandert. Deze functie is nuttig voor grotere datasets, die lang kunnen duren om grotendeels ongewijzigde gegevens te lezen. De incrementele sleutel geeft het laatste updatepunt voor de rijen in die gegevensbron aan.
geneste gegevens
geneste gegevens zijn niet volledig compatibel met BI suites en standaard SQL—queries-Panoply behandelt geneste gegevens met behulp van een sterk relationeel model dat geneste waarden niet toestaat. Panoply transformeert geneste gegevens op deze manieren:
- Subtables: standaard transformeert Panoply geneste gegevens in een set van veel-tot-veel of een-tot-veel relatietabellen, die platte relationele tabellen zijn.
- afvlakking: met deze modus ingeschakeld, vlakt Panoply de geneste structuur af op het record dat het bevat.
Geschiedenistabellen
soms moet u gegevens analyseren door bij te houden hoe gegevens in de loop van de tijd veranderen om precies te zien hoe de gegevens veranderen (bijvoorbeeld adressen van mensen).
om dergelijke analyses uit te voeren, gebruikt Panoply Geschiedenistabellen, dit zijn tijdreekstabellen die historische momentopnamen van elke rij in de oorspronkelijke statische tabel bevatten. U kunt vervolgens eenvoudige querying van de oorspronkelijke tabel of revisies van de tabel uitvoeren door terug te spoelen naar elk punt in de tijd.
transformaties
Panoply gebruikt ELT, een variatie op het oorspronkelijke ETL-gegevensintegratieproces. Zodra u gegevens uit de bron in uw datawarehouse hebt geïnjecteerd, transformeert Panoply deze onmiddellijk. Dit proces biedt u real-time gegevensanalyse en optimale prestaties in vergelijking met het standaard ETL-proces.
String formaten
Panoply ontleedt string formaten en behandelt ze alsof ze geneste objecten in de oorspronkelijke gegevens zijn. Ondersteunde string formaten zijn CSV, TSV, JSON, JSON-Line, Ruby object formaat, URL query strings, en web distributie logs.
gegevensbescherming
Panoply is gebouwd bovenop AWS, dus het heeft de nieuwste beveiligingspatches en versleutelingsmogelijkheden die AWS biedt, waaronder hardwareversnelde RSA-versleuteling en de specifieke set beveiligingsfuncties van Amazon Redshift.
Extra bescherming komt van zuilvormige encryptie, waarmee u uw privésleutels kunt gebruiken die niet op de servers van Panoply zijn opgeslagen.
Toegangscontrole
Panoply gebruikt verificatie in twee stappen om ongeautoriseerde toegang te voorkomen, en een machtigingssysteem laat u de toegang tot specifieke tabellen, weergaven of kolommen beperken. Anomaly detection identificeert query ‘s die afkomstig zijn van nieuwe computers of een ander land, zodat u deze query’ s kunt blokkeren, tenzij ze handmatig worden goedgekeurd.
IP Whitelisting
we raden u aan verbindingen van niet-herkende bronnen te blokkeren met behulp van een firewall of een AWS-beveiligingsgroep en het bereik van IP-adressen dat Panoply ‘ s gegevensbronnen altijd gebruiken op de witte lijst te zetten bij het openen van uw database.
conclusie: traditionele Versus Data Warehouse concepten in het kort
om af te ronden, zullen we de concepten in dit document samenvatten.
traditionele concepten voor datawarehouses
- feiten en maatstaven: een maatstaf is een eigenschap waarop berekeningen kunnen worden gemaakt. We verwijzen naar een verzameling van maatregelen als feiten, maar soms worden de termen door elkaar gebruikt.
- normalisatie: het proces om de hoeveelheid dubbele gegevens te verminderen, wat leidt tot een meer geheugenefficiënt datawarehouse dat langzamer kan worden opgevraagd.
- dimensie: wordt gebruikt voor het categoriseren en contextualiseren van feiten en maatregelen, waardoor analyse van en rapportage over die maatregelen mogelijk is.
- conceptueel gegevensmodel: definieert de kritieke gegevensentiteiten op hoog niveau en de onderlinge relaties.
- logisch gegevensmodel: Beschrijft gegevensrelaties, entiteiten en attributen in gewoon Engels zonder zich zorgen te maken over hoe het in code te implementeren.
- fysiek gegevensmodel: een weergave van hoe het gegevensontwerp moet worden geïmplementeerd in een specifiek databasebeheersysteem.
- Sterschema: neemt een feittabel en splitst de informatie ervan in gedenormaliseerde dimensietabellen.
- Snowflake schema: splitst de fact tabel in genormaliseerde dimensietabellen. Normaliseren vermindert de redundantie van gegevens en verbetert de integriteit van gegevens, maar query ‘ s zijn complexer.
- OLTP: Online transactieverwerkingssystemen vergemakkelijken een snelle, transactiegerichte verwerking met eenvoudige query ‘ s.
- OLAP: met Online analytische verwerking kunt u complexe leesquery ‘ s uitvoeren en zo een gedetailleerde analyse van historische transactiegegevens uitvoeren.
- Data mart: een archief van data gericht op een specifiek onderwerp of afdeling binnen een organisatie.
- Inmon-aanpak: Bill Inmon ‘ s data warehouse-aanpak definieert het datawarehouse als de gecentraliseerde dataopslag voor de gehele onderneming. Data marts kunnen vanuit het datawarehouse worden gebouwd om te voldoen aan de analytische behoeften van verschillende afdelingen.
- Kimball aanpak: Ralph Kimball beschrijft een datawarehouse als het samenvoegen van missiekritische datamartsâ die voor het eerst zijn gemaakt om te voldoen aan de analytische behoeften van verschillende afdelingen.
- ETL: integreert gegevens in het datawarehouse door ze uit verschillende transactionele bronnen te extraheren, de gegevens te transformeren om ze voor analyse te optimaliseren en ze uiteindelijk in het datawarehouse te laden.
- ELT: Een variant op ETL die ruwe gegevens uit de gegevensbronnen van een organisatie haalt en in het datawarehouse laadt. Wanneer nodig wordt het getransformeerd voor analytische doeleinden.
- Enterprise Data Warehouse: de EDW consolideert gegevens van alle vakgebieden die verband houden met de onderneming.
Cloud Data Warehouse Concepts-Amazon Redshift als voorbeeld
- Cluster: een groep gedeelde computing resources gebaseerd in de cloud.
- knooppunt: een computerbron binnen een cluster. Elk knooppunt heeft zijn eigen CPU, RAM en harde schijfruimte.
- zuilvormige opslag: Dit slaat de waarden van een tabel op in kolommen in plaats van rijen, waardoor de gegevens voor geaggregeerde query ‘ s worden geoptimaliseerd.
- compressie: technieken om de grootte van opgeslagen gegevens te verkleinen.
- laden van gegevens: Gegevens uit bronnen ophalen in het cloudgebaseerde datawarehouse. In Redshift kunt u de opdracht Kopiëren of een datastreamingservice gebruiken.
Cloud Data Warehouse Concepts-BigQuery als voorbeeld
- serverloze service: de cloudprovider beheert dynamisch de toewijzing van machinebronnen op basis van de hoeveelheid die de gebruiker verbruikt. De cloudprovider verbergt beslissingen over serverbeheer en capaciteitsplanning voor de gebruikers van de service.
- Colossus file system: een gedistribueerd bestandssysteem dat zuilvormige opslag-en datacompressiealgoritmen gebruikt om gegevens voor analyse te optimaliseren.
- Dremel execution engine: een query engine die massaal parallelle verwerking en zuilvormige opslag gebruikt om query ‘ s snel uit te voeren.
- delen van gegevens: in een serverloze dienst is het praktisch om de gedeelde gegevens van een andere organisatie te bevragen zonder te investeren in gegevensopslag—u betaalt gewoon voor de query ‘ s.
- Streaming-gegevens: Gegevens in real-time invoegen in het datawarehouse zonder een belasting uit te voeren. U kunt gegevens streamen in batchverzoeken, dat zijn meerdere API-oproepen gecombineerd in één HTTP-verzoek.
traditionele kosten-batenanalyse in de Cloud
| kosten / baten | traditioneel | Cloud |
| kosten | Grote voorafkosten voor de aankoop en installatie van een on-prem-systeem. u hebt hardware, serverruimtes en gespecialiseerd personeel nodig (dat u continu betaalt). als u niet zeker weet hoeveel opslagruimte u nodig hebt, bestaat het risico van hoge verzonken kosten die moeilijk te herstellen zijn. |
het is niet nodig hardware, serverruimtes of specialisten aan te schaffen. geen risico van verzonken kosten – het is gemakkelijk om in de toekomst meer opslag te kopen. Plus, de kosten van opslag en rekenkracht dalen in de tijd. |
| schaalbaarheid | zodra u uw huidige serverruimtes of hardware-capaciteit maximaal benut, moet u mogelijk nieuwe hardware kopen en meer plaatsen bouwen/kopen om deze te huisvesten. Plus, u moet voldoende opslagruimte kopen om piekuren aan te kunnen; dus, de meeste van de tijd, de meeste van uw opslag wordt niet gebruikt. |
u kunt eenvoudig meer opslagruimte kopen als en wanneer u het nodig hebt. moet vaak alleen betalen voor wat u gebruikt, dus er is weinig tot geen risico van te veel betalen. |
| integraties | aangezien cloud computing de norm is, zullen de meeste integraties die u wilt maken naar cloud services zijn. het verbinden van uw aangepaste datawarehouse met hen kan een uitdaging zijn. |
omdat clouddatawarehouses al in de cloud zijn, is het eenvoudig om verbinding te maken met een reeks andere clouddiensten. |
| beveiliging | u hebt volledige controle over uw datawarehouse. door de hoeveelheid gegevens die u huisvest te vergelijken met Amazon of Google, bent u een kleiner doelwit voor dieven. Dus, je hebt meer kans om alleen te worden gelaten. |
leveranciers van Clouddatawarehouses hebben teams vol hooggekwalificeerde beveiligingsingenieurs die uitsluitend tot doel hebben hun product zo veilig mogelijk te maken. de meest prominente bedrijven ter wereld beheren ze en implementeren daarom beveiligingspraktijken van wereldklasse. |
| Governance | u weet precies waar uw gegevens zijn en kunt deze lokaal benaderen. minder risico van zeer gevoelige gegevens die per ongeluk de wet overtreden door bijvoorbeeld over de hele wereld te reizen op een cloudserver. |
de top Cloud Data warehouse providers zorgen ervoor dat ze voldoen aan governance-en beveiligingswetten, zoals GDPR. Bovendien helpen ze uw bedrijf ervoor te zorgen dat u compliant bent. er zijn problemen met betrekking tot het precies weten van uw gegevens is en waar het beweegt. Deze problemen worden actief aangepakt en opgelost. merk op dat het opslaan van grote hoeveelheden zeer gevoelige gegevens in de cloud tegen specifieke wetten kan zijn. Dit is een geval waar cloud computing kan ongepast zijn voor uw bedrijf. |
| betrouwbaarheid | als uw on-prem datawarehouse faalt, is het uw verantwoordelijkheid om het te repareren. uw IT-team heeft toegang tot de fysieke hardware en heeft toegang tot elke softwarelaag om problemen op te lossen. Deze snelle toegang kan problemen veel sneller oplossen. er is echter geen garantie dat uw magazijn elk jaar een bepaalde hoeveelheid uptime zal hebben. |
Cloud Data warehouse providers garanderen hun betrouwbaarheid en uptime in hun SLA ‘ s. ze werken op massaal gedistribueerde systemen over de hele wereld, dus als er een storing is, is het hoogst onwaarschijnlijk dat u daar last van krijgt. |
| controle | uw datawarehouse is op maat gebouwd om aan uw behoeften te voldoen. In theorie doet het wat je wilt, wanneer je wilt, op een manier die je begrijpt. | u heeft geen volledige controle over uw datawarehouse. echter, de meeste van de tijd, de controle die je hebt is meer dan genoeg. |
| snelheid | als u een klein bedrijf bent op één geografische locatie met een kleine hoeveelheid gegevens, zal uw gegevensverwerking sneller verlopen. echter, we hebben het over milliseconden vs. seconden voor sommige processen te voltooien. een grote onderneming die in meerdere landen actief is, zal waarschijnlijk geen aanzienlijke snelheidswinst zien met een on-prem-systeem. |
cloudproviders hebben geïnvesteerd in systemen die Massively Parallel Processing (MPP), custom-built architecture en execution engines en intelligente algoritmen voor gegevensverwerking implementeren. Cloud Data warehouses zijn het resultaat van jarenlang onderzoek en testen om middelen te creëren die geoptimaliseerd zijn voor snelheid en prestaties. het kan in sommige gevallen iets langzamer zijn dan on-prem, maar deze vertragingen zijn vaak verwaarloosbaar voor mensen (seconden vs.milliseconden). |
Panoply is een veilige plek om al uw bedrijfsgegevens op te slaan, te synchroniseren en te openen. Panoply kan binnen enkele minuten worden ingesteld, vereist geen continu onderhoud en biedt online ondersteuning, inclusief toegang tot ervaren dataarchitecten. Probeer Panoply 14 dagen gratis uit.
meer informatie over datawarehouses
- datawarehouse-architectuur: traditioneel vs. Cloud
- Database vs. datawarehouse
- Data Mart vs. datawarehouse