Ceph
Benchmark Ceph Cluster Performance¶
jednym z najczęstszych pytań, które słyszymy, jest “jak sprawdzić, czy mój klaster działa z maksymalną wydajnością?”. Nie zastanawiaj się więcej – w tym przewodniku przedstawimy Ci kilka narzędzi, których możesz użyć do testowania klastra Ceph.
Uwaga: pomysły w tym artykule są oparte na blogu Sebastiana Hana, blogu TelekomCloud i wejściach od programistów i inżynierów Ceph.
uzyskaj podstawowe statystyki wydajności¶
zasadniczo benchmarking polega na porównywaniu. Nie będziesz wiedzieć, czy Klaster Ceph działa poniżej par, chyba że najpierw określisz jego maksymalną możliwą wydajność. Dlatego przed rozpoczęciem analizy porównawczej klastra należy uzyskać podstawowe statystyki wydajności dla dwóch głównych komponentów infrastruktury Ceph: dysków i sieci.
Benchmark Twoich dysków¶
najprostszym sposobem na benchmark Twojego dysku jest użycie dd. Użyj następującego polecenia do odczytu i zapisu pliku, pamiętając o dodaniu parametru oflag, aby ominąć pamięć podręczną strony dysku:shell> dd if=/dev/zero of=here bs=1G count=1 oflag=direct
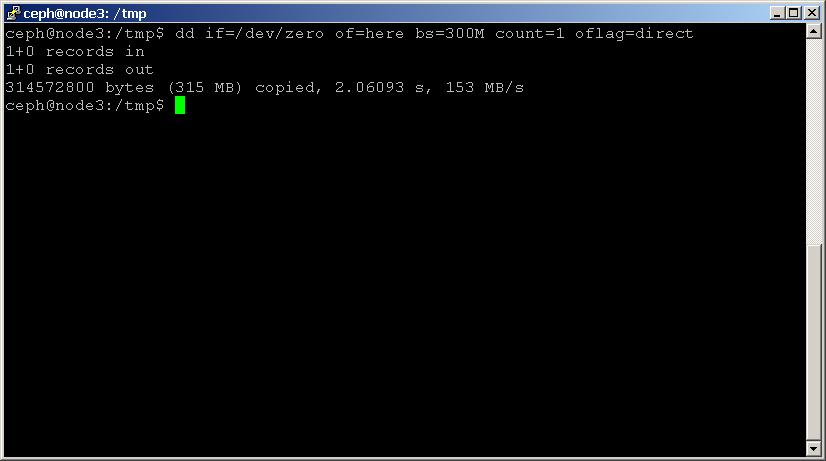
zwróć uwagę na ostatnią dostarczoną statystykę, która wskazuje wydajność dysku w MB / sek. wykonaj ten test dla każdego dysku w klastrze, zwracając uwagę na wyniki.
Benchmark Twojej sieci¶
kolejnym kluczowym czynnikiem wpływającym na wydajność klastra Ceph jest przepustowość sieci. Dobrym narzędziem do tego jest iperf, który wykorzystuje połączenie klient-serwer do pomiaru przepustowości TCP i UDP.
możesz zainstalować iperf używając apt-get install iperf lub yum install iperf.
iperf musi być zainstalowany na co najmniej dwóch węzłach w klastrze. Następnie, na jednym z węzłów, uruchom serwer iperf za pomocą następującego polecenia:
shell> iperf -s
na innym węźle uruchom klienta następującym poleceniem, pamiętając o użyciu adresu IP węzła hostującego serwer iperf:
shell> iperf -c 192.168.1.1
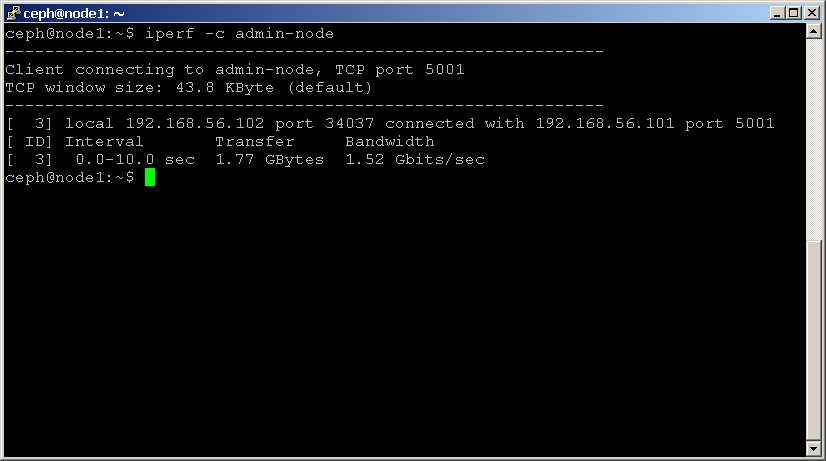
zwróć uwagę na statystyki przepustowości w Mbits / sec, ponieważ wskazuje to maksymalną przepustowość obsługiwaną przez sieć.
teraz, gdy masz już pewne wartości bazowe, możesz rozpocząć testowanie klastra Ceph, aby sprawdzić, czy zapewnia on podobną wydajność. Benchmarking może być przeprowadzany na różnych poziomach: można przeprowadzić benchmarking niskiego poziomu samego klastra pamięci masowej lub można przeprowadzić benchmarking wyższego poziomu kluczowych interfejsów, takich jak urządzenia blokowe i bramy obiektów. Poniższe sekcje omawiają każde z tych podejść.
UWAGA: Przed uruchomieniem któregokolwiek z benchmarków w kolejnych sekcjach upuść wszystkie pamięci podręczne za pomocą polecenia takiego jak ta:shell> sudo echo 3 | sudo tee /proc/sys/vm/drop_caches && sudo sync
testowanie klastra pamięci masowej Ceph¶
Ceph zawiera polecenie rados bench, zaprojektowane specjalnie do testowania klastra pamięci masowej RADOSS. Aby go użyć, Utwórz pulę pamięci, a następnie użyj rados bench do przeprowadzenia testu porównawczego zapisu, jak pokazano poniżej.
polecenie rados jest dołączone do Ceph.
shell> ceph osd pool create scbench 128 128
shell> rados bench -p scbench 10 write --no-cleanup
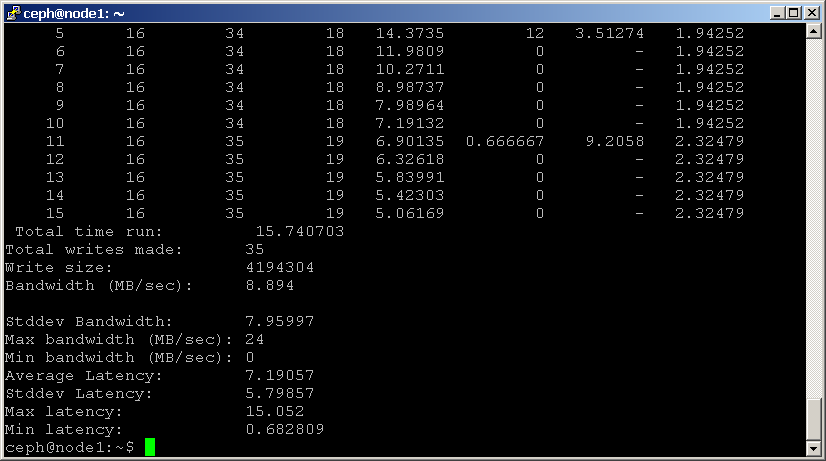
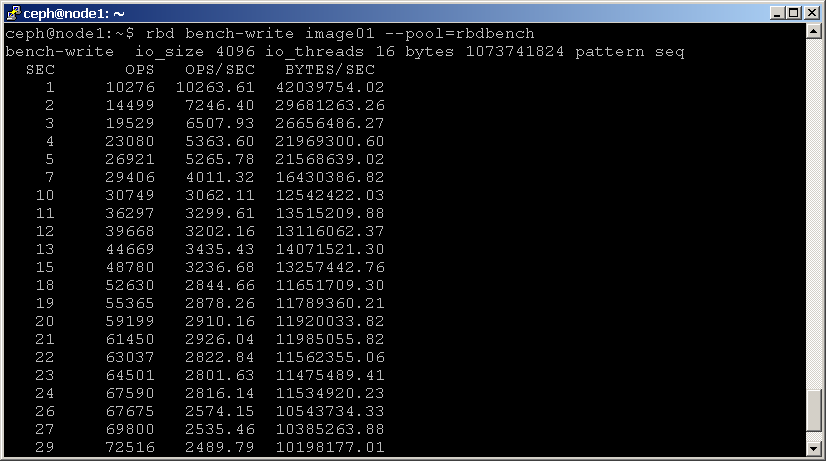
tworzy to nową pulę o nazwie “scbench”, a następnie wykonuje test zapisu przez 10 sekund. Zwróć uwagę na opcję — no-cleanup, która pozostawia pewne dane. Wynik daje dobry wskaźnik tego, jak szybko klaster może zapisywać dane.
dostępne są dwa typy wzorców odczytu: seq dla odczytów sekwencyjnych i rand dla odczytów losowych. Aby wykonać test porównawczy odczytu, użyj poniższych poleceń:shell> rados bench -p scbench 10 seq
shell> rados bench -p scbench 10 rand
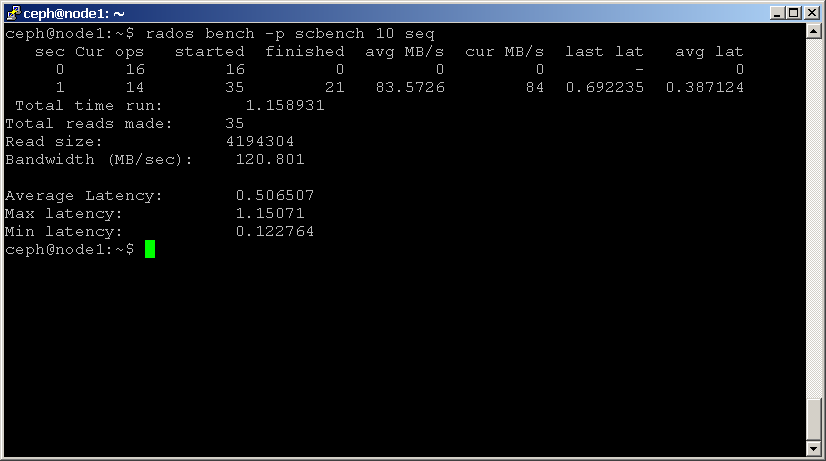
można również dodać parametr-T, aby zwiększyć współbieżność odczytów i zapisów (domyślnie 16 wątków), lub parametr-b, aby zmienić rozmiar zapisywanego obiektu (domyślnie 4 MB). Dobrym pomysłem jest również uruchomienie wielu kopii tego testu porównawczego z różnymi pulami, aby zobaczyć, jak zmienia się wydajność w przypadku wielu klientów.
po uzyskaniu danych możesz zacząć porównywać statystyki odczytu i zapisu klastra z wcześniej wykonanymi benchmarkami tylko na dysku, określić, ile luki w wydajności istnieje (jeśli istnieje) i zacząć szukać przyczyn.
możesz wyczyścić dane benchmarku pozostawione przez write benchmark za pomocą tego polecenia:
shell> rados -p scbench cleanup
testowanie urządzenia blokowego Ceph¶
jeśli jesteś fanem urządzeń blokowych Ceph, możesz użyć dwóch narzędzi do testowania ich wydajności. Ceph zawiera już polecenie RBD bench, ale możesz również użyć popularnego narzędzia do analizy porównawczej We/Wy fio, które teraz jest wyposażone w wbudowaną obsługę urządzeń blokujących RADOS.
polecenie RBD jest dołączone do Ceph. Obsługa RBD w fio jest stosunkowo nowa, dlatego trzeba ją pobrać z repozytorium, a następnie skompilować i zainstalować używając: configure &&make & make install_. Zauważ, że musisz zainstalować pakiet programistyczny librbd-dev za pomocą apt-get install librbd-dev lub yum install librbd-dev przed kompilacją fio, aby aktywować jego obsługę RBD.
Zanim jednak użyjesz jednego z tych dwóch narzędzi, Utwórz urządzenie blokowe za pomocą poniższych poleceń:shell> ceph osd pool create rbdbench 128 128
shell> rbd create image01 --size 1024 --pool rbdbench
shell> sudo rbd map image01 --pool rbdbench --name client.admin
shell> sudo /sbin/mkfs.ext4 -m0 /dev/rbd/rbdbench/image01
shell> sudo mkdir /mnt/ceph-block-device
shell> sudo mount /dev/rbd/rbdbench/image01 /mnt/ceph-block-device
polecenie RBD bench-write generuje serię sekwencyjnych zapisów do obrazu i mierzy przepustowość zapisu i opóźnienie. Oto przykład:
shell> rbd bench-write image01 --pool=rbdbench
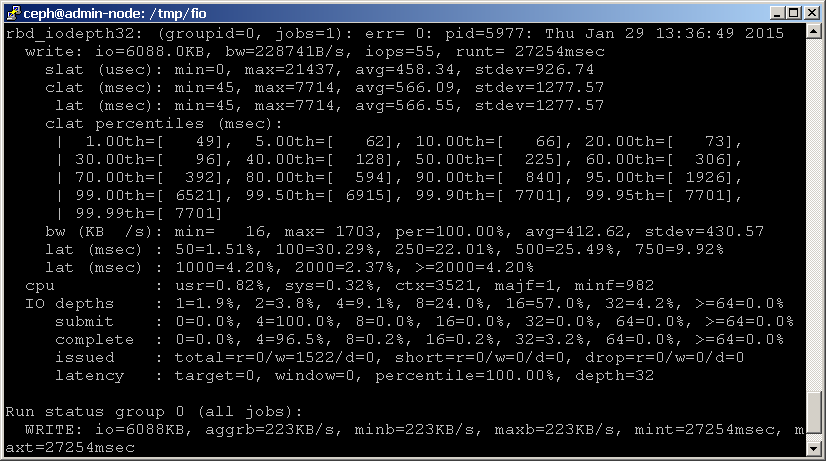
możesz też użyć fio do benchmarku urządzenia blokowego. Przykład rbd.szablon fio jest dołączony do kodu źródłowego fio, który wykonuje test losowego zapisu 4K na urządzeniu blokującym RADOS za pośrednictwem librbd. Pamiętaj, że będziesz musiał zaktualizować szablon o poprawne nazwy Puli i urządzenia, jak pokazano poniżej.
ioengine=rbd
clientname=admin
pool=rbdbench
rbdname=image01
rw=randwrite
bs=4k
iodepth=32
następnie uruchom fio w następujący sposób:shell> fio examples/rbd.fio
testowanie bramy obiektu Ceph¶
jeśli chodzi o testowanie bramy obiektu Ceph, nie szukaj dalej niż swift-bench, narzędzie do testowania dołączone do OpenStack Swift. Narzędzie swift-bench testuje wydajność klastra Ceph, symulując żądania klientów PUT I GET oraz mierząc ich wydajność.
możesz zainstalować swift-bench za pomocą pip install swift && pip install swift-bench.
aby używać swift-bench, musisz najpierw utworzyć użytkownika bramy i subusera, jak pokazano poniżej:shell> sudo radosgw-admin user create --uid="benchmark" --display-name="benchmark"
shell> sudo radosgw-admin subuser create --uid=benchmark --subuser=benchmark:swift
--access=full
shell> sudo radosgw-admin key create --subuser=benchmark:swift --key-type=swift
--secret=guessme
shell> radosgw-admin user modify --uid=benchmark --max-buckets=0
następnie utwórz plik konfiguracyjny dla swift-bench na hoście klienta, jak poniżej. Pamiętaj, aby zaktualizować adres URL uwierzytelniania tak, aby odzwierciedlał adres bramy obiektu Ceph oraz aby używać prawidłowej nazwy użytkownika i poświadczeń.
auth = http://gateway-node/auth/v1.0
user = benchmark:swift
key = guessme
auth_version = 1.0
możesz teraz uruchomić benchmark jak poniżej. Użyj parametru-c, aby dostosować liczbę jednoczesnych połączeń (w tym przykładzie używa się 64), a parametru-s, aby dostosować rozmiar zapisywanego obiektu (w tym przykładzie używa się obiektów 4K). Parametry-n I-g określają odpowiednio liczbę obiektów do umieszczenia i pobrania.shell> swift-bench -c 64 -s 4096 -n 1000 -g 100 /tmp/swift.conf
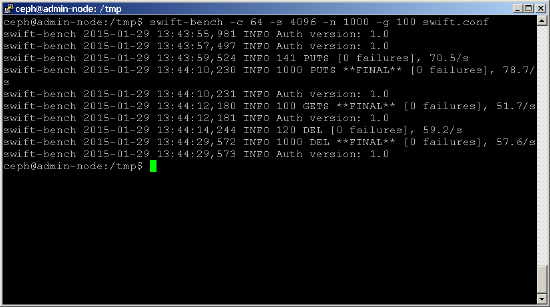
chociaż swift-bench mierzy wydajność w liczbie obiektów / sek, łatwo jest to przekształcić w MB / sek, mnożąc przez rozmiar każdego obiektu. Należy jednak uważać, aby nie porównywać tego bezpośrednio ze statystykami wydajności dysku bazowego uzyskanymi wcześniej, ponieważ na te statystyki wpływa również wiele innych czynników, takich jak:
- poziom replikacji (i narzut opóźnienia)
- pełne zapisy danych w dzienniku danych (w niektórych sytuacjach kompensowane przez łączenie danych w dzienniku)
- fsync na OSD w celu zagwarantowania bezpieczeństwa danych
- narzut metadanych do przechowywania danych w Dzienniku Rados
- opóźnienie napowietrzne (sieć, ceph, itp) sprawia, że czytnik jest ważniejszy
wskazówka: Jeśli chodzi o wydajność object gateway, nie ma twardej i szybkiej reguły, której można użyć do łatwej poprawy wydajności. W niektórych przypadkach inżynierowie Ceph byli w stanie uzyskać lepszą wydajność niż wyjściowa dzięki sprytnym strategiom buforowania i koalescencji, podczas gdy w innych przypadkach wydajność bramy obiektowej była niższa niż wydajność dysku ze względu na opóźnienia, fsync i narzuty metadanych.
wnioski¶
dostępnych jest wiele narzędzi do testowania klastra Ceph na różnych poziomach: dysk, sieć, klaster, urządzenie i Brama. Teraz powinieneś mieć wgląd w to, jak podejść do procesu benchmarkingu i rozpocząć generowanie danych dotyczących wydajności klastra. Powodzenia!