Cloud Data Warehouse vs Traditional Data Warehouse Concepts
magazyny danych oparte na chmurze to nowa norma. Dawno minęły czasy, kiedy Twoja firma musiała kupować sprzęt, tworzyć serwerownie i wynajmować, szkolić i utrzymywać dedykowany zespół pracowników do jego obsługi. Teraz, za pomocą kilku kliknięć na laptopie i karcie kredytowej, możesz uzyskać dostęp do praktycznie nieograniczonej mocy obliczeniowej i przestrzeni dyskowej.
nie oznacza to jednak, że tradycyjne pomysły hurtowni danych są martwe. Klasyczna teoria hurtowni danych stanowi podstawę większości działań hurtowni danych opartych na chmurze.
w tym artykule wyjaśnimy tradycyjne koncepcje hurtowni danych, które musisz znać, oraz najważniejsze koncepcje chmury od najlepszych dostawców: Amazon, Google i Panoply. Na koniec przedstawimy analizę kosztów i korzyści tradycyjnych i chmurowych hurtowni danych, abyś wiedział, który z nich jest dla Ciebie odpowiedni.
zaczynajmy.
- tradycyjne koncepcje hurtowni danych
- fakty, wymiary i miary
- normalizacja i Denormalizacja
- Modele danych
- tabela faktów
- schemat Gwiazdy vs schemat Płatka Śniegu
- OLAP kontra OLTP
- Trzywarstwowa Architektura
- wirtualna Hurtownia danych / Data Mart
- Kimball vs. Inmon
- ETL vs. ELT
- Enterprise Data Warehouse
- koncepcje hurtowni danych w chmurze
- koncepcje hurtowni danych w chmurze – Amazon Redshift
- klastry
- węzły
- partycje / plasterki
- magazyn kolumnowy
- Kompresja
- Ładowanie Danych
- Cloud Database Warehouse – Google BigQuery
- usługa Bezserwerowa
- system plików Colossus
- Dremel Execution Engine
- udostępnianie danych
- przesyłanie strumieniowe i pobieranie wsadowe
- koncepcje hurtowni danych w chmurze – Panoply
- klucze podstawowe
- Klucze przyrostowe
- zagnieżdżone dane
- tabele historii
- transformacje
- formaty łańcuchów
- Ochrona danych
- Kontrola dostępu
- Biała lista IP
- podsumowanie: tradycyjne kontra koncepcje hurtowni danych w skrócie
- tradycyjne pojęcia hurtowni danych
- koncepcje Cloud Data Warehouse – Amazon Redshift jako przykład
- koncepcje hurtowni danych w chmurze – BigQuery jako przykład
- tradycyjna a analiza kosztów i korzyści w chmurze
- dowiedz się więcej o hurtowniach danych
tradycyjne koncepcje hurtowni danych
hurtownia danych to każdy system, który gromadzi dane z szerokiej gamy źródeł w organizacji. Hurtownie danych są wykorzystywane jako scentralizowane repozytoria danych do celów analitycznych i sprawozdawczych.
tradycyjna hurtownia danych znajduje się na miejscu w Twoich biurach. Kupujesz sprzęt, serwerownie i zatrudniasz pracowników do jego obsługi. Są one również nazywane on-premises, on-prem lub (niepoprawne gramatycznie) on-premises hurtowniami danych.
fakty, wymiary i miary
podstawowymi elementami składowymi informacji w hurtowni danych są fakty, wymiary i miary.
fakt to część Twoich danych, która wskazuje na określone zdarzenie lub transakcję. Na przykład, jeśli Twoja firma sprzedaje kwiaty, niektóre fakty, które zobaczysz w swojej hurtowni danych, to:
- Sprzedam 30 róż w sklepie za 19 dolarów.99
- zamówił 500 nowych doniczek z Chin za $1500
- wypłacone wynagrodzenie kasjera za Ten miesiąc $1000
kilka liczb może opisać każdy fakt, a my nazywamy te liczby miarami. Niektóre środki opisujące fakt “zamówione 500 nowych doniczek z Chin za 1500 dolarów” to:
- ilość zamówiona-500
- koszt – $1500
gdy analitycy pracują z danymi, wykonują obliczenia na miarach (np. suma, maksymalna, średnia), aby zebrać wgląd. Na przykład możesz chcieć znać średnią liczbę doniczek, które zamawiasz każdego miesiąca.
wymiar kategoryzuje fakty i miary i zapewnia im uporządkowane informacje o etykietach – w przeciwnym razie byłyby one po prostu zbiorem nieuporządkowanych liczb! Niektóre wymiary opisujące fakt “zamówione 500 nowych doniczek z Chin za 1500 dolarów” to:
- kraj zakupiony od-Chiny
- czas zakupu-13: 00
- oczekiwana data przyjazdu-6 czerwca
nie możesz wykonać obliczeń na wymiarach wyraźnie, a zrobienie tego prawdopodobnie nie byłoby zbyt pomocne – jak możesz znaleźć “średnią datę przyjazdu dla zamówień”? Możliwe jest jednak tworzenie nowych miar z wymiarów, a te są użyteczne. Na przykład, jeśli znasz średnią liczbę dni między datą zamówienia a datą przyjazdu, możesz lepiej zaplanować zakupy zapasów.
normalizacja i Denormalizacja
normalizacja to proces sprawnego organizowania danych w hurtowni danych (lub dowolnym innym miejscu, które przechowuje dane). Głównym celem jest zmniejszenie redundancji danych – tj. usunięcie duplikatów danych – oraz poprawa integralności danych – tj. poprawienie dokładności danych. Istnieją różne poziomy normalizacji i brak konsensusu dla “najlepszej” metody. Jednak wszystkie metody obejmują przechowywanie oddzielnych, ale powiązanych elementów informacji w różnych tabelach.
istnieje wiele korzyści z normalizacji, takich jak:
- Szybsze wyszukiwanie i sortowanie w każdej tabeli
- prostsze tabele sprawiają, że polecenia modyfikacji danych szybciej zapisują i wykonują
- mniej nadmiarowych danych oznacza oszczędność miejsca na dysku, dzięki czemu można zbierać i przechowywać więcej danych
Denormalizacja to proces celowo dodawania nadmiarowych kopii lub grup danych do już znormalizowanych danych. To nie to samo, co dane unormowane. Denormalizacja poprawia wydajność odczytu i znacznie ułatwia manipulowanie tabelami w formularzach. Gdy analitycy pracują z hurtowniami danych, zwykle wykonują odczyty tylko na danych. W ten sposób denormalizowane dane mogą zaoszczędzić im ogromnej ilości czasu i bólów głowy.
zalety denormalizacji:
- mniej tabel minimalizuje potrzebę łączenia tabel, co przyspiesza przepływ pracy analityków danych i prowadzi ich do odkrywania bardziej przydatnych wglądów w dane
- mniej tabel uprość zapytania prowadzące do mniejszej liczby błędów
Modele danych
przechowywanie wszystkich danych w jednej ogromnej tabeli byłoby szalenie nieefektywne. Hurtownia danych zawiera wiele tabel, które można połączyć, aby uzyskać określone informacje. Główną tabelę nazywa się tabelą faktów, a tabele wymiarów otaczają ją.
pierwszym krokiem w projektowaniu hurtowni danych jest zbudowanie koncepcyjnego modelu danych, który definiuje żądane dane i relacje między nimi na wysokim poziomie.
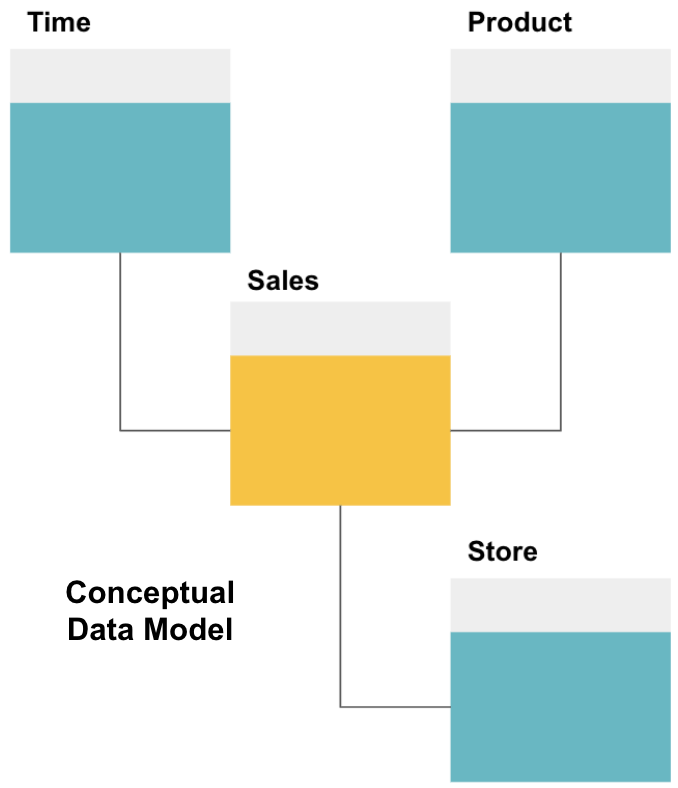
tutaj zdefiniowaliśmy model koncepcyjny. Przechowujemy dane sprzedażowe i mamy trzy dodatkowe tabele-czas, produkt i Sklep-które dostarczają dodatkowych, bardziej szczegółowych informacji o każdej sprzedaży. Tabelą faktów jest sprzedaż, a pozostałe są tabelami wymiarowymi.
następnym krokiem jest zdefiniowanie logicznego modelu danych. Model ten szczegółowo opisuje dane w prostym języku angielskim, nie martwiąc się o to, jak zaimplementować je w kodzie.
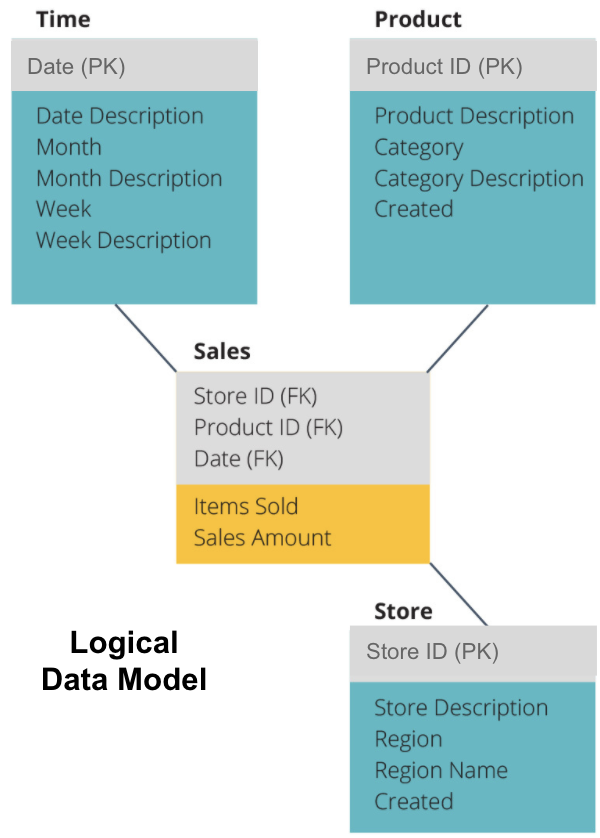
teraz wypełniliśmy informacje, które każda tabela zawiera w prostym języku angielskim. Każda z tabel wymiarów czasu, produktu i magazynu pokazuje klucz podstawowy (PK) w szarym polu, a odpowiednie dane w niebieskich polach. Tabela Sprzedaży zawiera trzy klucze obce (FK), dzięki czemu może szybko połączyć się z innymi tabelami.
ostatnim etapem jest stworzenie fizycznego modelu danych. Ten model mówi, jak zaimplementować hurtownię danych w kodzie. Definiuje tabele, ich strukturę i relacje między nimi. Określa również typy danych dla kolumn, a wszystko jest nazwane tak, jak będzie w końcowej hurtowni danych, tj. wszystkie znaki i połączone ze znakami podkreślenia. Wreszcie, każda tabela wymiarów zaczyna się od DIM_, a każda tabela faktów zaczyna się od FACT_.
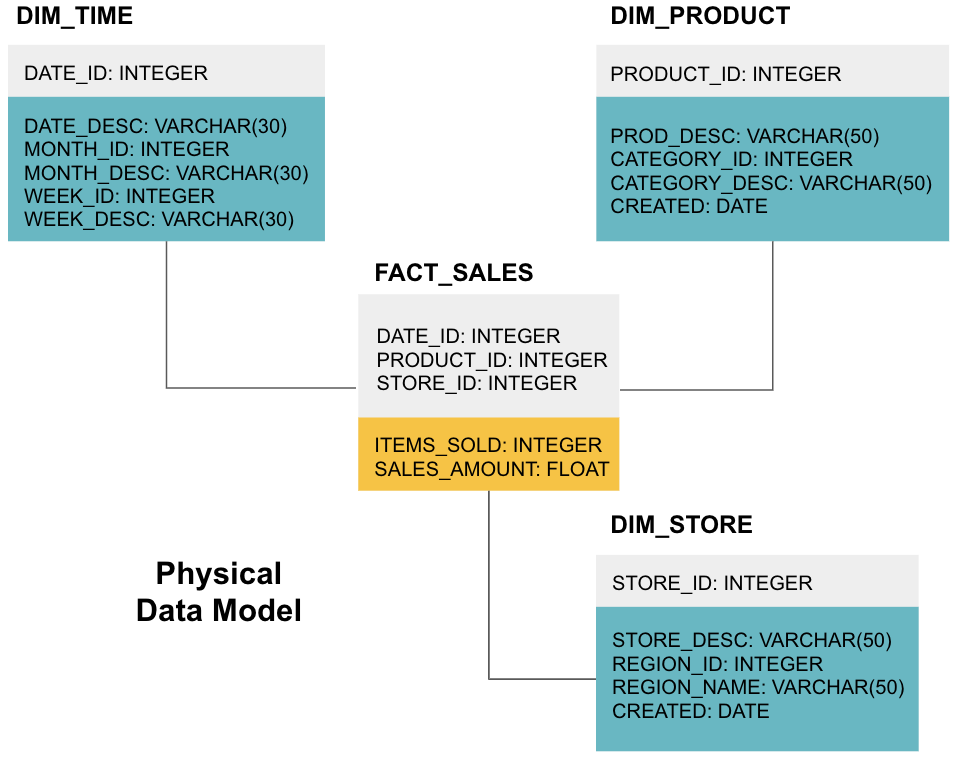
teraz wiesz, jak zaprojektować hurtownię danych, ale istnieje kilka niuansów dotyczących tabel faktów i wymiarów, które wyjaśnimy dalej.
tabela faktów
każda funkcja biznesowa – np. sprzedaż, marketing, finanse – ma odpowiednią tabelę faktów.
tabele faktów mają dwa typy kolumn: kolumny wymiaru i kolumny faktów. Kolumny wymiarów-w naszych przykładach w kolorze szarym-zawierają klucze obce (FK), których używasz do łączenia tabeli faktów z tabelą wymiarów. Te klucze obce są kluczami podstawowymi (PK) dla każdej z tabel wymiarów. Kolumny faktów-w naszych przykładach w Kolorze Żółtym-zawierają rzeczywiste dane i środki do analizy, np. liczbę sprzedanych pozycji i całkowitą wartość sprzedaży w dolarach.
tablica faktów bez faktów jest szczególnym rodzajem tabeli faktów, która ma tylko kolumny wymiarów. Takie tabele są przydatne do śledzenia zdarzeń, takich jak frekwencja uczniów lub urlopy pracowników, ponieważ wymiary mówią wszystko, co musisz wiedzieć o wydarzeniach.
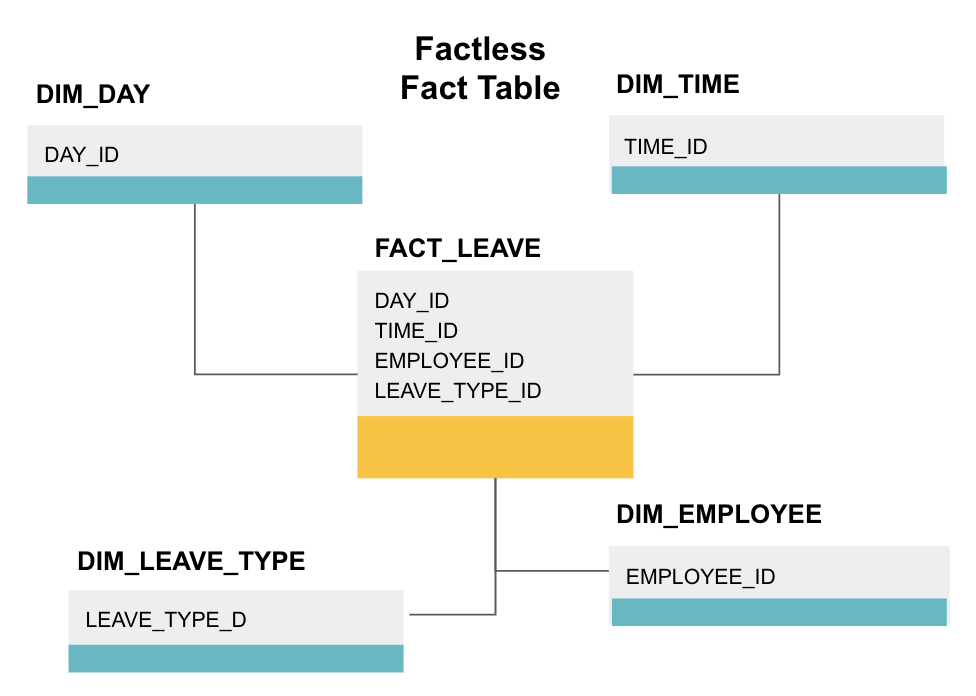
powyższa tablica faktów śledzi urlopy pracowników. Nie ma żadnych faktów, ponieważ musisz tylko wiedzieć:
- jakiego dnia były wolne (DAY_ID).
- jak długo były wyłączone (TIME_ID).
- kto był na urlopie (EMPLOYEE_ID).
- ich powody przebywania na urlopie, np., choroba, urlop, wizyta u lekarza itp. (LEAVE_TYPE_ID).
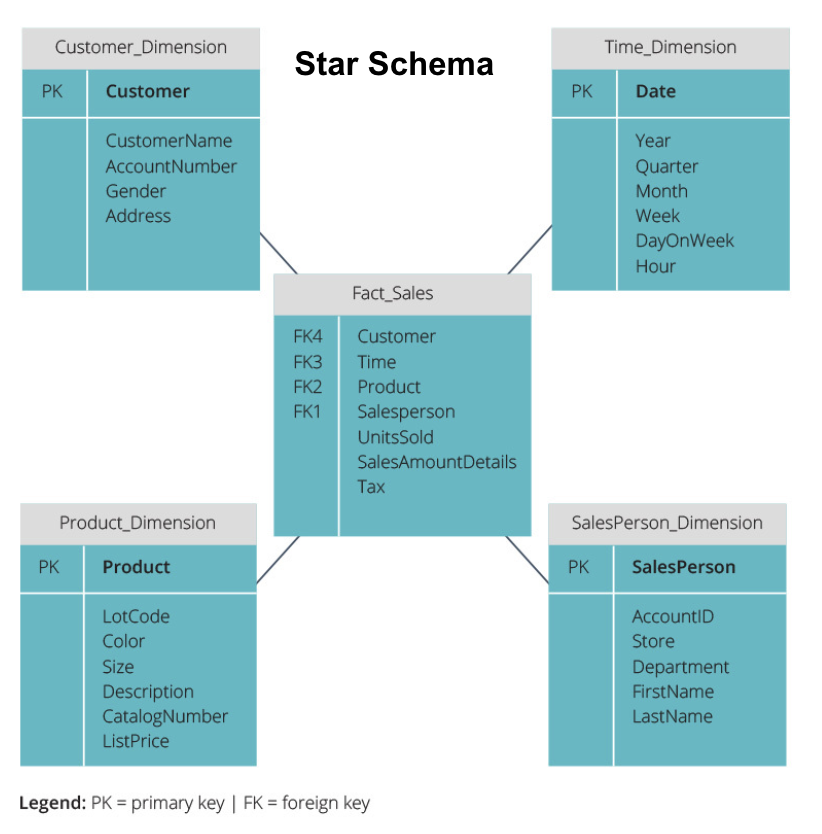
schemat Gwiazdy vs schemat Płatka Śniegu
wszystkie powyższe hurtownie danych miały podobny układ. Jednak nie jest to jedyny sposób, aby je zorganizować.
dwa najpopularniejsze Schematy używane do organizowania hurtowni danych to star i snowflake. Obie metody używają tabel wymiarów, które opisują informacje zawarte w tabeli faktów.
schemat Gwiazdy pobiera informacje z tabeli faktów i dzieli je na denormalizowane tabele wymiarów. Nacisk na schemat Gwiazdy kładzie się na szybkość zapytań. Tylko jedno join jest potrzebne, aby połączyć tabele faktów z każdym wymiarem, więc odpytywanie każdej tabeli jest łatwe. Ponieważ jednak tabele są denormalizowane, często zawierają powtarzające się i nadmiarowe dane.
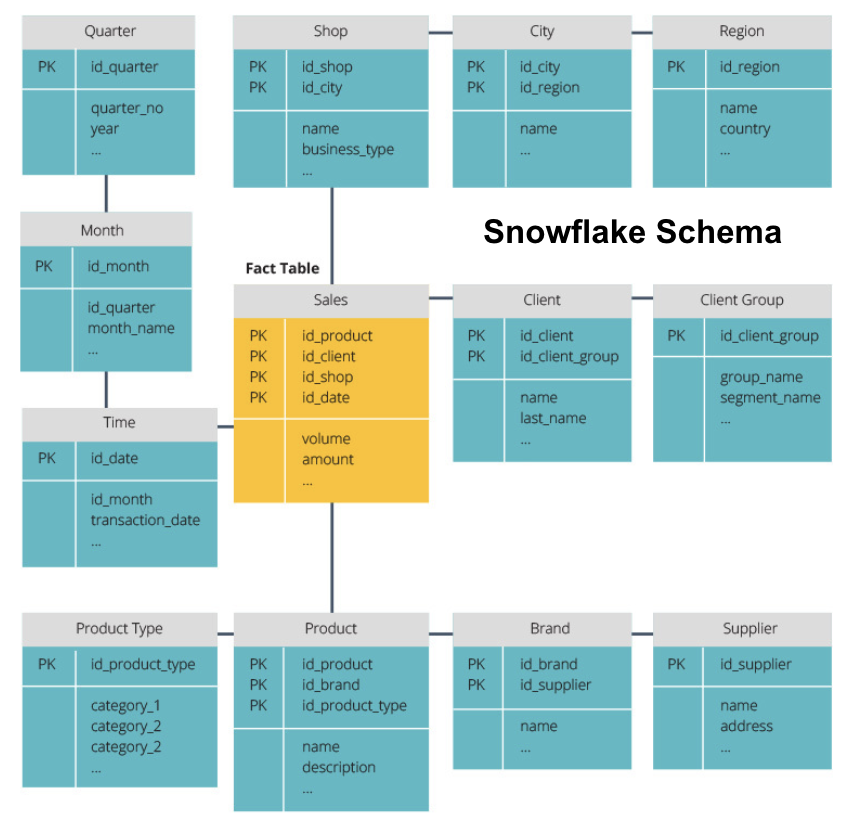
schemat płatka śniegu dzieli tabelę faktów na serię znormalizowanych tabel wymiarów. Normalizacja tworzy więcej tabel wymiarów, a tym samym zmniejsza problemy z integralnością danych. Jednak zapytania jest trudniejsze przy użyciu schematu płatka śniegu, ponieważ potrzebujesz więcej tabel łączy, aby uzyskać dostęp do odpowiednich danych. Masz więc mniej zbędnych danych, ale dostęp do nich jest trudniejszy.
teraz wyjaśnimy kilka podstawowych koncepcji hurtowni danych.
OLAP kontra OLTP
przetwarzanie transakcji online (OLTP) charakteryzuje się transakcjami typu short write, które obejmują aplikacje front-end architektury danych przedsiębiorstwa. Bazy danych OLTP kładą nacisk na szybkie przetwarzanie zapytań i zajmują się tylko aktualnymi danymi. Firmy wykorzystują je do przechwytywania informacji dla procesów biznesowych i dostarczania danych źródłowych dla hurtowni danych.
online analytical processing (OLAP) pozwala na uruchamianie złożonych zapytań odczytu, a tym samym wykonywanie szczegółowej analizy historycznych danych transakcyjnych. Systemy OLAP pomagają analizować dane w hurtowni danych.
Trzywarstwowa Architektura
tradycyjne hurtownie danych mają zazwyczaj strukturę trzech warstw:
- dolna warstwa: serwer bazy danych, zazwyczaj RDBMS, który wyodrębnia dane z różnych źródeł za pomocą bramy. Źródła danych wprowadzane do tej warstwy obejmują operacyjne bazy danych i inne typy danych front-end, takie jak pliki CSV i JSON.
- warstwa środkowa: serwer OLAP, który
- bezpośrednio implementuje operacje lub
- mapuje operacje na danych wielowymiarowych na standardowe operacje relacyjne, np. spłaszczanie danych XML lub JSON w wiersze w tabelach.
- Top Tier: narzędzia do zapytań i raportowania do analizy danych i Business intelligence.
wirtualna Hurtownia danych / Data Mart
wirtualna hurtownia danych wykorzystuje rozproszone zapytania w kilku bazach danych, bez integrowania danych w jedną fizyczną hurtownię danych.
data marts to podzbiory hurtowni danych zorientowanych na określone funkcje biznesowe, takie jak sprzedaż lub Finanse. Hurtownia danych zazwyczaj łączy informacje z kilku Mart danych w wielu funkcjach biznesowych. Jednak data mart zawiera dane z zestawu systemów źródłowych dla jednej funkcji biznesowej.
Kimball vs. Inmon
istnieją dwa podejścia do projektowania hurtowni danych, zaproponowane przez Billa Inmona i Ralpha Kimballa. Bill Inmon to amerykański informatyk, uznawany za ojca hurtowni danych. Ralph Kimball jest jednym z oryginalnych architektów hurtowni danych i napisał kilka książek na ten temat.
obaj eksperci mieli sprzeczne opinie na temat struktury hurtowni danych. Konflikt ten dał początek dwóm szkołom myślenia.
podejście Inmon jest projektem odgórnym. Dzięki metodologii Inmon hurtownia danych jest tworzona jako pierwsza i jest postrzegana jako centralny składnik środowiska analitycznego. Dane są następnie sumowane i dystrybuowane ze scentralizowanego magazynu do jednego lub więcej zależnych martów danych.
podejście Kimballa zajmuje oddolny widok projektu hurtowni danych. W tej architekturze Organizacja tworzy oddzielne centra danych, które dostarczają widoki do pojedynczych działów w organizacji. Hurtownia danych to połączenie tych danych.
ETL vs. ELT
Extract, Transform, Load (ETL) opisuje proces ekstrakcji danych z systemów źródłowych (zazwyczaj systemów transakcyjnych), konwersji danych na format lub strukturę odpowiednią do zapytań i analiz, a następnie załadowania ich do hurtowni danych. ETL wykorzystuje oddzielną bazę danych i stosuje szereg reguł lub funkcji do wyodrębnionych danych przed załadowaniem.
Extract, Load, Transform (ELT) to inne podejście do ładowania danych. ELT pobiera dane z różnych źródeł i ładuje je bezpośrednio do systemu docelowego, takiego jak hurtownia danych. Następnie system przekształca załadowane dane na żądanie, aby umożliwić analizę.
ELT oferuje szybsze ładowanie niż ETL, ale wymaga potężnego systemu do wykonywania transformacji danych na żądanie.
Enterprise Data Warehouse
enterprise data warehouse to ujednolicony, scentralizowany magazyn zawierający wszystkie informacje transakcyjne w organizacji, zarówno bieżące, jak i historyczne. Hurtownia danych przedsiębiorstwa powinna zawierać dane ze wszystkich obszarów tematycznych związanych z działalnością, takich jak marketing, sprzedaż, finanse i zasoby ludzkie.
są to podstawowe idee, które tworzą tradycyjne hurtownie danych. Teraz przyjrzyjmy się, jakie hurtownie danych w chmurze dodały do nich.
koncepcje hurtowni danych w chmurze
hurtownie danych w chmurze są nowe i stale się zmieniają. Aby najlepiej zrozumieć ich podstawowe pojęcia, najlepiej jest poznać wiodące rozwiązania hurtowni danych w chmurze.
trzy wiodące rozwiązania hurtowni danych w chmurze to Amazon Redshift, Google BigQuery i Panoply. Poniżej wyjaśniamy podstawowe pojęcia z każdej z tych usług, aby zapewnić ogólne zrozumienie, jak działają nowoczesne hurtownie danych.
koncepcje hurtowni danych w chmurze – Amazon Redshift
poniższe koncepcje są wyraźnie stosowane w hurtowni danych w chmurze Amazon Redshift, ale mogą mieć zastosowanie do dodatkowych rozwiązań hurtowni danych w przyszłości opartych na infrastrukturze Amazon.
klastry
Amazon Redshift opiera swoją architekturę na klastrach. Klaster to po prostu Grupa współdzielonych zasobów obliczeniowych, zwanych węzłami.
węzły
Węzły To zasoby obliczeniowe, które mają CPU, PAMIĘĆ RAM i miejsce na dysku twardym. Klaster zawierający dwa lub więcej węzłów składa się z węzła lidera i węzłów obliczeniowych.
węzły leadera komunikują się z programami klienckimi i kompilują kod do wykonywania zapytań, przypisując go do węzłów obliczeniowych. Węzły obliczeniowe uruchamiają zapytania i zwracają wyniki do węzła prowadzącego. Węzeł obliczeniowy wykonuje tylko zapytania, które odwołują się do tabel przechowywanych w tym węźle.
partycje / plasterki
Amazon partycje każdy węzeł obliczeniowy w plasterki. Plasterek otrzymuje przydział pamięci i miejsca na dysku w węźle. Wiele plasterków działa równolegle, aby przyspieszyć czas wykonywania zapytań.
magazyn kolumnowy
Redshift wykorzystuje magazyn kolumnowy, umożliwiając lepszą wydajność zapytań analitycznych. Zamiast zapisywać rekordy w wierszach, przechowuje wartości z jednej kolumny dla wielu wierszy. Poniższe diagramy sprawiają, że jest to jaśniejsze:
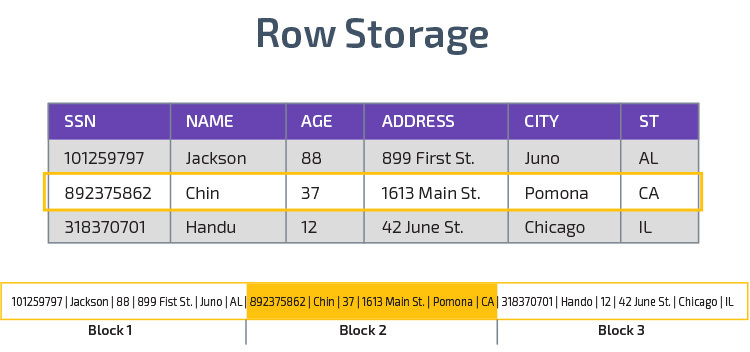
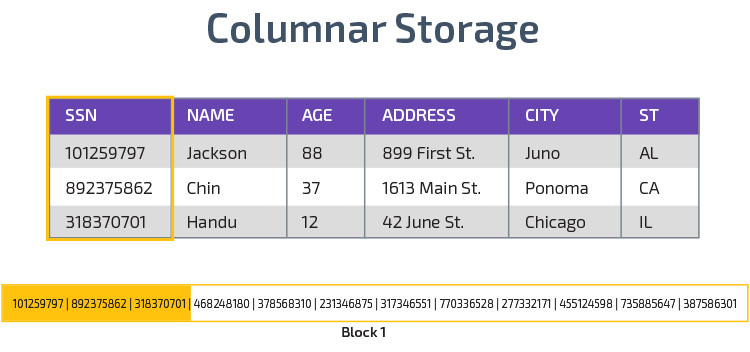
Przechowywanie kolumnowe umożliwia szybszy odczyt danych, co jest kluczowe w przypadku zapytań analitycznych obejmujących wiele kolumn w zbiorze danych. Pamięć kolumnowa zajmuje również mniej miejsca na dysku, ponieważ każdy blok zawiera ten sam typ danych, co oznacza, że można go skompresować do określonego formatu.
Kompresja
Kompresja zmniejsza rozmiar przechowywanych danych. W Redshift, ze względu na sposób przechowywania danych, kompresja występuje na poziomie kolumny. Redshift pozwala na ręczne kompresowanie informacji podczas tworzenia tabeli lub automatycznie za pomocą polecenia Kopiuj.
Ładowanie Danych
możesz użyć polecenia Kopiuj Redshift, aby załadować duże ilości danych do hurtowni danych. Polecenie COPY wykorzystuje architekturę MPP Redshift do równoległego odczytywania i ładowania danych z plików w Amazon S3, z tabeli DynamoDB lub danych wyjściowych tekstu z jednego lub więcej zdalnych hostów.
możliwe jest również przesyłanie danych do Redshift za pomocą usługi Amazon Kinesis Firehose.
Cloud Database Warehouse – Google BigQuery
poniższe pojęcia są wyraźnie używane w Google BigQuery cloud data warehouse, ale mogą mieć zastosowanie do dodatkowych rozwiązań w przyszłości opartych na infrastrukturze Google.
usługa Bezserwerowa
BigQuery wykorzystuje architekturę bezserwerową. Dzięki BigQuery firmy nie muszą zarządzać fizycznymi jednostkami serwerowymi, aby uruchomić swoje hurtownie danych. Zamiast tego BigQuery dynamicznie zarządza alokacją zasobów obliczeniowych. Przedsiębiorstwa korzystające z usługi po prostu płacą za przechowywanie danych na gigabajt, a zapytania na terabajt.
system plików Colossus
BigQuery korzysta z najnowszej wersji rozproszonego systemu plików Google o nazwie kodowej Colossus. System plików Colossus wykorzystuje algorytmy przechowywania kolumnowego i kompresji do optymalnego przechowywania danych do celów analitycznych.
Dremel Execution Engine
Dremel execution engine wykorzystuje układ kolumnowy do szybkiego odpytywania ogromnych magazynów danych. Silnik wykonawczy Dremel może uruchamiać zapytania ad-hoc na miliardach wierszy w sekundach, ponieważ wykorzystuje masowo równoległe przetwarzanie w postaci architektury drzewa.
Architektura drzewa rozdziela zapytania między kilka serwerów pośrednich z serwera głównego. Serwery pośrednie wysyłają zapytanie do serwerów leaf (zawierających zapisane dane), które skanują dane równolegle. W drodze powrotnej na drzewo każdy serwer leaf wysyła wyniki zapytań, a serwery pośrednie przeprowadzają równoległą agregację wyników częściowych.
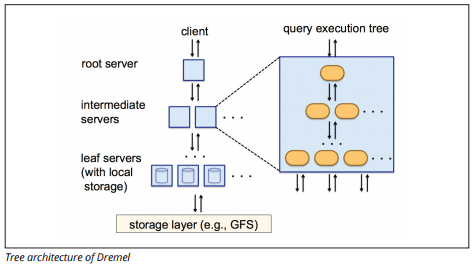
źródło obrazu
Dremel umożliwia organizacjom jednoczesne uruchamianie zapytań na dziesiątkach tysięcy serwerów. Według Google Dremel może skanować 35 miliardów wierszy bez indeksu w ciągu kilkudziesięciu sekund.
udostępnianie danych
Architektura Bezserwerowa Google BigQuery umożliwia przedsiębiorstwom łatwe udostępnianie danych innym organizacjom bez konieczności inwestowania w ich własne przechowywanie.
organizacje, które chcą odpytywać udostępnione dane, mogą to zrobić i będą płacić tylko za zapytania. Nie ma potrzeby tworzenia kosztownych współdzielonych silosów danych, poza infrastrukturą danych organizacji, i kopiowania danych do tych silosów.
przesyłanie strumieniowe i pobieranie wsadowe
możliwe jest ładowanie danych do BigQuery z Google Cloud Storage, w tym plików CSV, JSON (rozdzielanych znakami nowej linii) i Avro, a także kopii zapasowych Google Cloud Datastore. Można również załadować dane bezpośrednio z czytelnego źródła danych.
BigQuery oferuje również strumieniowe API do ładowania danych do systemu z prędkością milionów wierszy na sekundę bez ładowania. Dane są dostępne do analizy niemal natychmiast.
koncepcje hurtowni danych w chmurze – Panoply
Panoply to kompleksowy magazyn, który łączy ETL z potężnym magazynem danych. Jest to najprostszy sposób synchronizacji, przechowywania i dostępu do danych firmy, eliminując rozwój i kodowanie związane z przekształcaniem, integracją i zarządzaniem dużymi danymi.
Poniżej znajdują się niektóre z głównych pojęć w hurtowni danych Panoply związanych z modelowaniem danych i ochroną danych.
klucze podstawowe
klucze podstawowe zapewniają, że wszystkie wiersze w tabelach są unikalne. Każda tabela ma jeden lub więcej kluczy podstawowych, które określają, co reprezentuje pojedynczy unikalny wiersz w bazie danych. Wszystkie interfejsy API mają domyślny klucz podstawowy dla tabel.
Klucze przyrostowe
Panoply używa klucza przyrostowego do kontrolowania atrybutów w celu stopniowego ładowania danych ze źródeł do hurtowni danych, zamiast przeładowywania całego zestawu danych za każdym razem, gdy coś się zmienia. Ta funkcja jest przydatna w przypadku większych zbiorów danych, które mogą zająć dużo czasu, aby odczytać głównie niezmienione dane. Klucz Przyrostowy wskazuje ostatni punkt aktualizacji dla wierszy w tym źródle danych.
zagnieżdżone dane
zagnieżdżone dane nie są w pełni zgodne z pakietami BI i standardowymi zapytaniami SQL—Panoply zajmuje się zagnieżdżonymi danymi za pomocą silnie relacyjnego modelu, który nie zezwala na zagnieżdżone wartości. Panoply przekształca zagnieżdżone dane w następujący sposób:
- podzbiory: domyślnie Panoply przekształca zagnieżdżone dane w zestaw tabel relacji wiele-do-wielu lub jeden-do-wielu, które są płaskimi tabelami relacyjnymi.
- spłaszczanie: przy włączonym tym trybie Panoply spłaszcza zagnieżdżoną strukturę na rekord, który ją zawiera.
tabele historii
czasami trzeba analizować dane, śledząc zmiany danych w czasie, aby dokładnie zobaczyć, jak zmieniają się dane (na przykład adresy osób).
aby przeprowadzić takie analizy, Panoply używa tabel historii, które są tabelami szeregów czasowych, które zawierają historyczne migawki każdego wiersza w oryginalnej tabeli statycznej. Następnie można wykonać proste zapytania do oryginalnej tabeli lub zmiany do tabeli, przewijając do dowolnego punktu w czasie.
transformacje
Panoply używa ELT, który jest wariacją na temat pierwotnego procesu integracji danych ETL. Po wstrzyknięciu danych ze źródła do magazynu danych Panoply natychmiast je przekształca. Proces ten zapewnia analizę danych w czasie rzeczywistym i optymalną wydajność w porównaniu ze standardowym procesem ETL.
formaty łańcuchów
Panoply przetwarza formaty łańcuchów i obsługuje je tak, jakby były zagnieżdżonymi obiektami w oryginalnych danych. Obsługiwane formaty ciągów to CSV, TSV, JSON, JSON-Line, Ruby object format, ciągi zapytań URL i dzienniki dystrybucji sieci web.
Ochrona danych
Panoply jest zbudowany na bazie AWS, więc ma najnowsze poprawki zabezpieczeń i możliwości szyfrowania dostarczane przez AWS, w tym przyspieszane sprzętowo szyfrowanie RSA i specjalny zestaw funkcji bezpieczeństwa Amazon Redshift.
dodatkowa ochrona pochodzi z szyfrowania kolumnowego, które umożliwia korzystanie z kluczy prywatnych, które nie są przechowywane na serwerach Panoply.
Kontrola dostępu
Panoply wykorzystuje dwustopniową weryfikację, aby zapobiec nieautoryzowanemu dostępowi, a system uprawnień pozwala ograniczyć dostęp do określonych tabel, widoków lub kolumn. Wykrywanie anomalii identyfikuje zapytania pochodzące z nowych komputerów lub z innego kraju, co pozwala na blokowanie tych zapytań, chyba że zostaną one zatwierdzone ręcznie.
Biała lista IP
zalecamy blokowanie połączeń z nierozpoznanych źródeł za pomocą zapory sieciowej lub grupy zabezpieczeń AWS i dodawanie do białej listy zakresu adresów IP, z których źródła danych Panoply zawsze korzystają podczas uzyskiwania dostępu do bazy danych.
podsumowanie: tradycyjne kontra koncepcje hurtowni danych w skrócie
aby zakończyć, podsumujemy koncepcje wprowadzone w tym dokumencie.
tradycyjne pojęcia hurtowni danych
- fakty i miary: miara to właściwość, na której można dokonać obliczeń. Określamy zbiór miar jako fakty, ale czasami terminy są używane zamiennie.
- normalizacja: proces zmniejszania ilości duplikatów danych, co prowadzi do bardziej wydajnego magazynu danych, który jest wolniejszy w zapytaniach.
- wymiar: służy do kategoryzowania i kontekstualizacji faktów i środków, umożliwiając analizę i raportowanie na temat tych środków.
- koncepcyjny model danych: definiuje krytyczne jednostki danych wysokiego poziomu i relacje między nimi.
- logiczny model danych: Opisuje relacje danych, encje i atrybuty w prostym języku angielskim, nie martwiąc się o to, jak zaimplementować je w kodzie.
- fizyczny model danych: przedstawienie sposobu implementacji projektu danych w określonym systemie zarządzania Bazą Danych.
- schemat Gwiazdy: pobiera tabelę faktów i dzieli jej informacje na denormalizowane tabele wymiarów.
- schemat Płatka Śniegu: dzieli tabelę faktów na znormalizowane tabele wymiarów. Normalizacja zmniejsza problemy z redundancją danych i poprawia integralność danych, ale zapytania są bardziej złożone.
- OLTP: Systemy przetwarzania transakcji online ułatwiają szybkie, zorientowane na transakcje przetwarzanie za pomocą prostych zapytań.
- OLAP: przetwarzanie analityczne Online pozwala na uruchamianie złożonych zapytań odczytu, a tym samym wykonywanie szczegółowej analizy historycznych danych transakcyjnych.
- data mart: archiwum danych skupiające się na określonym temacie lub Dziale w organizacji.
- podejście Inmon: podejście Bill Inmon Data warehouse definiuje hurtownię danych jako scentralizowane repozytorium danych dla całego przedsiębiorstwa. Data marts mogą być budowane z hurtowni danych, aby zaspokoić potrzeby analityczne różnych działów.
- podejście Kimballa: Ralph Kimball opisuje hurtownię danych jako połączenie krytycznych martów danych, które są najpierw tworzone w celu zaspokojenia potrzeb analitycznych różnych działów.
- ETL: integruje dane z hurtownią danych, wyodrębniając je z różnych źródeł transakcyjnych, przekształcając dane w celu ich optymalizacji do analizy, a następnie ładując je do hurtowni danych.
- ELT: Odmiana ETL, która wyodrębnia surowe dane ze źródeł danych organizacji i ładuje je do hurtowni danych. W razie potrzeby jest przekształcany w celach analitycznych.
- Hurtownia danych przedsiębiorstwa: EDW konsoliduje dane ze wszystkich obszarów tematycznych związanych z przedsiębiorstwem.
koncepcje Cloud Data Warehouse – Amazon Redshift jako przykład
- Klaster: Grupa współdzielonych zasobów obliczeniowych opartych na chmurze.
- węzeł: zasób obliczeniowy zawarty w klastrze. Każdy węzeł ma swój własny procesor, pamięć RAM i miejsce na dysku twardym.
- : Przechowuje to wartości tabeli w kolumnach, a nie w wierszach, co optymalizuje dane dla zapytań zagregowanych.
- Kompresja: techniki zmniejszania rozmiaru przechowywanych danych.
- ładowanie danych: Pobieranie danych ze źródeł do hurtowni danych w chmurze. W Redshift możesz użyć polecenia Kopiuj lub usługi przesyłania strumieniowego danych.
koncepcje hurtowni danych w chmurze – BigQuery jako przykład
- usługa Bezserwerowa: dostawca chmury dynamicznie zarządza alokacją zasobów maszyny W oparciu o ilość zużywaną przez użytkownika. Dostawca chmury ukrywa decyzje dotyczące zarządzania serwerem i planowania pojemności od użytkowników Usługi.
- system plików Colossus: rozproszony system plików, który wykorzystuje algorytmy przechowywania kolumnowego i kompresji danych do optymalizacji danych do analizy.
- Dremel execution engine: silnik zapytań, który wykorzystuje masowo równoległe przetwarzanie i przechowywanie kolumnowe do szybkiego wykonywania zapytań.
- udostępnianie danych: w usłudze bezserwerowej praktyczne jest odpytywanie współdzielonych danych innej organizacji bez inwestowania w Przechowywanie danych-po prostu płacisz za zapytania.
- strumieniowanie danych: wstawianie danych w czasie rzeczywistym do hurtowni danych bez ładowania. Możesz przesyłać strumieniowo dane w żądaniach wsadowych, które są wieloma połączeniami API połączonymi w jedno żądanie HTTP.
tradycyjna a analiza kosztów i korzyści w chmurze
| koszt / korzyść | tradycyjny | Chmura |
| Koszt | duży koszt początkowy zakupu i instalacji systemu on-prem. potrzebujesz sprzętu, serwerowni i specjalistycznego personelu (który płacisz na bieżąco). jeśli nie masz pewności, ile miejsca do przechowywania potrzebujesz, istnieje ryzyko wysokich kosztów utopione, które są trudne do odzyskania. |
nie ma potrzeby zakupu sprzętu, serwerowni ani zatrudniania specjalistów. brak ryzyka kosztów utopionych-zakup większej ilości pamięci masowej w przyszłości jest łatwy. Plus, koszt pamięci i mocy obliczeniowej maleje z czasem. |
| skalowalność | po maksymalizacji obecnej pojemności serwerowni lub sprzętu może być konieczne zakup nowego sprzętu i zbudowanie/zakup większej liczby miejsc do jego przechowywania. Plus, trzeba kupić wystarczająco dużo miejsca, aby poradzić sobie z czasem szczytu; w związku z tym przez większość czasu większość pamięci nie jest używana. |
możesz łatwo kupić więcej pamięci masowej, gdy jej potrzebujesz. często po prostu trzeba płacić za to, czego używasz, więc nie ma ryzyka przepłacenia. |
| integracje | ponieważ przetwarzanie w chmurze jest normą, większość integracji, które chcesz wykonać, dotyczy usług w chmurze. podłączenie do nich niestandardowej hurtowni danych może okazać się trudne. |
ponieważ hurtownie danych w chmurze znajdują się już w chmurze, łączenie się z wieloma innymi usługami w chmurze jest proste. |
| bezpieczeństwo | masz całkowitą kontrolę nad swoim magazynem danych. porównując ilość danych, które posiadasz do Amazona lub Google, jesteś mniejszym celem dla złodziei. Więc może być bardziej prawdopodobne, że zostaniesz sam. |
dostawcy hurtowni danych w chmurze mają zespoły złożone z wysoko wykwalifikowanych inżynierów bezpieczeństwa, których jedynym celem jest zapewnienie bezpieczeństwa ich produktów. wiodące firmy na świecie zarządzają nimi, a tym samym wdrażają światowej klasy praktyki bezpieczeństwa. |
| Zarządzanie | wiesz dokładnie, gdzie są Twoje dane i masz do nich dostęp lokalnie. mniejsze ryzyko nieumyślnego łamania prawa przez bardzo wrażliwe dane, na przykład podróżując po świecie na serwerze w chmurze. |
najlepsi dostawcy hurtowni danych w chmurze zapewniają ich zgodność z przepisami dotyczącymi nadzoru i bezpieczeństwa, takimi jak RODO. Dodatkowo pomagają twojej firmie zapewnić zgodność z przepisami. pojawiły się problemy dotyczące dokładnej znajomości danych i miejsca ich przenoszenia. Problemy te są aktywnie rozwiązywane i rozwiązywane. pamiętaj, że przechowywanie ogromnych ilości bardzo wrażliwych danych w chmurze może być niezgodne z określonymi przepisami. Jest to jeden przypadek, w którym przetwarzanie w chmurze może być nieodpowiednie dla Twojej firmy. |
| niezawodność | jeśli twój lokalny magazyn danych zawiedzie, Twoim obowiązkiem jest go naprawić. Twój zespół IT ma dostęp do fizycznego sprzętu i może uzyskać dostęp do każdej warstwy oprogramowania w celu rozwiązywania problemów. Ten szybki dostęp może znacznie przyspieszyć rozwiązywanie problemów. jednak nie ma gwarancji, że Twój magazyn będzie miał określoną ilość czasu sprawności każdego roku. |
dostawcy hurtowni danych w chmurze gwarantują niezawodność i czas pracy w swoich umowach SLA. działają na masowo rozproszonych systemach na całym świecie, więc jeśli wystąpi awaria na jednym z nich, jest mało prawdopodobne, aby wpłynęła na Ciebie. |
| Kontrola | twoja hurtownia danych jest dostosowana do Twoich potrzeb. Teoretycznie robi to, co chcesz, kiedy chcesz, w sposób, który rozumiesz. | nie masz całkowitej kontroli nad hurtownią danych. jednak przez większość czasu kontrola, którą masz, jest więcej niż wystarczająca. |
| szybkość | jeśli jesteś małą firmą w jednym miejscu geograficznym z niewielką ilością danych, twoje przetwarzanie danych będzie szybsze. jednak mówimy o milisekundach vs. sekundach dla niektórych procesów do zakończenia. duża firma działająca w wielu krajach prawdopodobnie nie zauważy znaczącego wzrostu prędkości dzięki systemowi on-prem. |
dostawcy chmury zainwestowali i stworzyli systemy, które implementują Massively Parallel Processing (MPP), niestandardową architekturę i mechanizmy wykonawcze oraz inteligentne algorytmy przetwarzania danych. hurtownie danych w chmurze są wynikiem lat badań i testów w celu stworzenia zasobów zoptymalizowanych pod kątem szybkości i wydajności. w niektórych przypadkach może być nieco wolniejszy niż on-prem, ale te opóźnienia są często nieistotne dla ludzi (sekundy vs.milisekundy). |
Panoply to bezpieczne miejsce do przechowywania, synchronizacji i uzyskiwania dostępu do wszystkich danych biznesowych. Panoply można skonfigurować w ciągu kilku minut, nie wymaga ciągłej konserwacji i zapewnia wsparcie online, w tym dostęp do doświadczonych architektów danych. Wypróbuj Panoply za darmo przez 14 dni.
dowiedz się więcej o hurtowniach danych
- Architektura hurtowni danych: tradycyjna kontra Chmura
- baza danych kontra Hurtownia danych
- Data Mart kontra Hurtownia danych