ewolucja systemu planowania klastrów
Kubernetes stał się de facto standardem w dziedzinie orkiestracji kontenerów. Wszystkie aplikacje będą rozwijane i uruchamiane na Kubernetes w przyszłości. Celem tej serii artykułów jest przedstawienie podstawowych zasad implementacji Kubernetes w sposób dogłębny i prosty.
Kubernetes jest systemem planowania klastrów. W tym artykule przedstawiono przede wszystkim wcześniejszą architekturę systemu planowania klastrów Kubernetes. Analizując ich pomysły projektowe i charakterystykę architektury, możemy zbadać proces ewolucji architektury systemu planowania klastrów i główny problem, który należy wziąć pod uwagę w projektowaniu architektury. Będzie to bardzo pomocne w zrozumieniu architektury Kubernetes.
musimy zrozumieć niektóre z podstawowych pojęć systemu planowania klastrów, aby było jasne, wyjaśnię tę koncepcję na przykładzie, załóżmy, że chcemy zaimplementować rozproszony Cron. System zarządza zestawem hostów Linuksowych. Użytkownik definiuje zadanie poprzez API dostarczane przez system. system będzie okresowo wykonywać odpowiednie zadanie w oparciu o definicję zadania, w tym przykładzie podstawowe pojęcia są poniżej:
- Klaster: hosty linuksowe zarządzane przez ten system tworzą pulę zasobów do uruchamiania zadań. Ta pula zasobów nazywa się klastrem.
- zadanie: określa, w jaki sposób klaster wykonuje swoje zadania. W tym przykładzie Crontab jest dokładnie prostym zadaniem, które wyraźnie pokazuje, co należy zrobić(skrypt wykonawczy) w jakim czasie (przedział czasu).Definicja niektórych zadań jest bardziej złożona, na przykład definicja zadania do wykonania w kilku zadaniach i zależności między zadaniami, a także wymagania dotyczące zasobów każdego zadania.
- zadanie: zadanie musi być zaplanowane na konkretne zadania wydajnościowe. Jeśli zdefiniujemy zadanie, które ma wykonywać skrypt o 1 w nocy, to proces skryptowy wykonywany o 1 w nocy każdego dnia jest zadaniem.
podczas projektowania systemu planowania klastra, podstawowe zadania systemu to dwa:
- planowanie zadań: Po przesłaniu zadań do systemu planowania klastra przesłane zadania należy podzielić na konkretne zadania wykonawcze, a wyniki wykonania zadań muszą być śledzone i monitorowane. W przykładzie rozproszonego crona system planowania musi na czas rozpocząć proces zgodnie z wymaganiami operacji. Jeśli proces się nie powiedzie, konieczna jest ponowna próba itp. Niektóre złożone scenariusze, takie jak Hadoop Map Reduce, system planowania musi podzielić zadanie Map Reduce na odpowiednie wiele Map i zredukować zadania, a ostatecznie uzyskać dane wyniku wykonania zadania.
- planowanie zasobów: jest zasadniczo używane do dopasowywania zadań i zasobów, a odpowiednie zasoby są przydzielane do uruchamiania zadań zgodnie z wykorzystaniem zasobów hostów w klastrze. Jest to podobne do procesu algorytmu planowania systemu operacyjnego, głównym celem planowania zasobów jest poprawa wykorzystania zasobów w miarę możliwości i skrócenie czasu oczekiwania na zadania pod warunkiem stałej podaży zasobów oraz zmniejszenie opóźnienia zadania lub czasu odpowiedzi (jeśli jest to zadanie wsadowe, odnosi się do czasu od początku do końca operacji zadania, jeśli są to zadania typu odpowiedzi online, takie jak aplikacje internetowe, które odnoszą się do każdego czasu odpowiedzi na żądanie), priorytet zadania należy wziąć pod uwagę, będąc tak sprawiedliwym, jak i sprawiedliwym. możliwe (zasoby są sprawiedliwie przydzielane do wszystkich zadań). Niektóre z tych celów są sprzeczne i muszą być zrównoważone, takie jak wykorzystanie zasobów, czas reakcji, Sprawiedliwość i priorytety.
Hadoop MRv1
Map Reduce jest rodzajem równoległego modelu obliczeniowego. Hadoop może uruchomić tego rodzaju platformę zarządzania klastrami obliczeń równoległych. MRv1 jest pierwszą generacją silnika planowania zadań Map Reduce platformy Hadoop. Krótko mówiąc, MRv1 jest odpowiedzialny za planowanie i wykonywanie zadania na klastrze oraz powrót do wyników obliczeń, gdy użytkownik zdefiniuje mapę zmniejsz obliczenia i prześlij je do Hadoop. Oto jak wygląda Architektura MRv1:
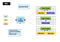
architektura jest stosunkowo prosta, standardowa Architektura Master / Slave ma dwa podstawowe komponenty:
- Job Tracker jest głównym komponentem zarządzania klastrem, który jest odpowiedzialny zarówno za planowanie zasobów, jak i planowanie zadań.
- Task Tracker działa na każdej maszynie w klastrze, która jest odpowiedzialna za uruchamianie określonych zadań na hoście i raportowanie stanu.
wraz z popularnością Hadoop i wzrostem różnych wymagań, MRv1 ma następujące problemy do poprawy:
- wydajność ma pewne wąskie gardło: Maksymalna liczba węzłów wspierających zarządzanie wynosi 5000, a maksymalna liczba zadań wspierających działanie to 40 000. Jest jeszcze trochę miejsca na poprawę.
- nie jest wystarczająco elastyczny, aby rozszerzyć lub obsługiwać inne typy zadań. Oprócz zadań typu Map reduce, istnieje wiele innych typów zadań w ekosystemie Hadoop, które należy zaplanować, takich jak Spark, Hive, HBase, Storm, Oozie itp. Dlatego potrzebny jest bardziej ogólny system planowania, który może obsługiwać i rozszerzać więcej typów zadań
- niskie wykorzystanie zasobów: MRv1 statycznie konfiguruje stałą liczbę slotów dla każdego węzła, a każdy slot może być używany tylko dla określonego typu zadania (Map lub Reduce), co prowadzi do problemu wykorzystania zasobów. Na przykład duża liczba zadań na mapie czeka w kolejce na bezczynne zasoby, ale w rzeczywistości duża liczba miejsc na redukcję jest bezczynna dla maszyn.
- multi-tenancy i multi-version issues. Na przykład różne działy uruchamiają zadania w tym samym klastrze, ale są logicznie odizolowane od siebie lub uruchamiają różne wersje Hadoop w tym samym klastrze.
YARN
YARN(Yet Another Resource Negotiator) to druga generacja Hadoop ,głównym celem jest rozwiązywanie wszelkiego rodzaju problemów w MRv1. Architektura przędzy wygląda tak:

proste zrozumienie YARN polega na tym, że główną poprawą w stosunku do MRv1 jest podział obowiązków oryginalnego ścieżki zadań na dwa różne komponenty: Menedżer zasobów i Mistrz aplikacji
- Menedżer zasobów: Jest odpowiedzialny za planowanie zasobów, zarządza wszystkimi zasobami, przypisuje zasoby do różnych typów zadań i łatwo rozszerza algorytm planowania zasobów za pomocą wtyczkowej architektury.
- Mistrz aplikacji: odpowiada za planowanie zadań. Każde zadanie (zwane aplikacją w przędzy) uruchamia odpowiedni Master aplikacji, który jest odpowiedzialny za podział zadania na konkretne zadania i ubieganie się o zasoby z Menedżera zasobów, rozpoczynanie zadania, śledzenie statusu zadania i raportowanie wyników.
przyjrzyjmy się, jak ta zmiana architektury rozwiązała różne problemy MRv1:
- podziel oryginalne obowiązki planowania zadań w Job Tracker, co skutkuje znaczną poprawą wydajności. Obowiązki związane z planowaniem zadań w oryginalnym Job trackerze zostały rozdzielone, a Master aplikacji został rozproszony, każda instancja obsługiwała tylko jedno zadanie, dzięki czemu promowała maksymalną liczbę węzłów klastra z 5000 do 10 000.
- komponenty harmonogramowania zadań, wzorca aplikacji i harmonogramowania zasobów są oddzielone i dynamicznie tworzone na podstawie żądań zadań. Jedna instancja application Master odpowiada tylko za jedno zadanie planowania, co ułatwia obsługę różnych typów zadań.
- wprowadzono technologię izolacji kontenerów, każde zadanie jest uruchamiane w izolowanym kontenerze, co znacznie poprawia wykorzystanie zasobów zgodnie z zapotrzebowaniem zadania na zasoby, które mogą być przydzielane dynamicznie. Minusem jest to, że zarządzanie zasobami i alokacja mają tylko jeden wymiar pamięci.
Architektura Mezos
celem projektu YARN jest nadal obsługa harmonogramu ekosystemu Hadoop. Cel Mesos jest coraz bliższy, ma być to ogólny system planowania, który może zarządzać pracą całego data center. Jak widzimy, projekt architektoniczny Mezos wykorzystywał wiele przędzy w celach informacyjnych, planowanie zadań i planowanie zasobów są ponoszone przez różne moduły osobno. Jednak największą różnicą między Mezos i YARN jest sposób planowania zasobów, zaprojektowany został unikalny mechanizm zwany ofertą zasobów. Presja harmonogramu zasobów jest dodatkowo zwalniana, a skalowalność harmonogramu zadań jest również zwiększona.

głównymi składnikami Mezos są:
- Mesos Master: jest to komponent odpowiedzialny wyłącznie za alokację zasobów i elementy zarządzania, który jest menedżerem zasobów odpowiadającym przędzy wewnętrznej. Ale tryb działania jest nieco inny, jeśli zostaną omówione później.
- Framework: odpowiada za planowanie zadań, Różne typy zadań będą miały odpowiednie ramy, takie jak Framework Spark, który jest odpowiedzialny za zadania Spark.
oferta zasobów Mezos
może się wydawać, że architektury Mezos i YARN są dość podobne, ale w rzeczywistości, w aspekcie zarządzania zasobami, Mistrz Mezos ma bardzo unikalny (i nieco dziwaczny) mechanizm oferty zasobów:
- przędza jest Pull: Zasoby dostarczane przez Menedżera zasobów w YARN są pasywne, gdy konsumenci zasobu (application Master) potrzebują zasobów, może wywołać interfejs menedżera zasobów, aby uzyskać zasoby, a Menedżer zasobów tylko pasywnie reaguje na potrzeby mistrza aplikacji.
- Mezos jest Push: zasoby dostarczane przez Master of Mesos są proaktywne. Master of Mesos będzie regularnie podejmował inicjatywę, aby zepchnąć wszystkie dostępne obecnie zasoby (tzw. oferty zasobów, nazwę je od teraz ofertą) do frameworka. Jeśli Framework ma do wykonania zadania, nie może aktywnie ubiegać się o zasoby, chyba że zostaną otrzymane oferty. Framework wybiera kwalifikowany zasób z oferty do zaakceptowania (ten ruch nazywa się akceptować w Mezos) i odrzucić pozostałe oferty (ten ruch nazywa się odrzucić). Jeśli nie ma wystarczającej ilości wykwalifikowanych zasobów w tej rundzie oferty, musimy poczekać na następną rundę mistrza, aby przedstawić ofertę.
wierzę, że gdy zobaczysz ten aktywny mechanizm oferty, będziesz miał to samo uczucie ze mną. Oznacza to, że wydajność jest stosunkowo niska i pojawią się następujące problemy:
- efektywność decyzyjna wszelkich RAM ma wpływ na ogólną efektywność. Aby zachować spójność, Master może oferować tylko jeden Framework naraz i czekać, aż Framework wybierze ofertę, zanim dostarczy resztę do następnego frameworku. W ten sposób efektywność podejmowania decyzji przez jakiekolwiek ramy wpłynie na ogólną wydajność.
- “marnuje” dużo czasu na frameworki, które nie wymagają zasobów. Mesos tak naprawdę nie wie, który Framework potrzebuje zasobów. Tak więc będą ramy z wymaganiami dotyczącymi zasobów, które stoją w kolejce do oferty, ale Ramy bez wymagań dotyczących zasobów często otrzymują ofertę.
w odpowiedzi na powyższe problemy, Mesos dostarczył pewne mechanizmy łagodzące problemy, takie jak ustawienie limitu czasu dla frameworka na podejmowanie decyzji lub umożliwienie Frameworkowi odrzucania ofert poprzez ustawienie go w stanie tłumić. Ponieważ nie jest to główny punkt tej dyskusji, szczegóły są tu pomijane.
w rzeczywistości istnieje kilka oczywistych zalet dla Mezos korzystających z tego mechanizmu aktywnej oferty:
- wydajność jest wyraźnie lepsza. Klaster może obsługiwać do 100 000 węzłów zgodnie z testami symulacyjnymi, w środowisku produkcyjnym Twittera największy klaster może obsługiwać 80 000 węzłów. głównym powodem jest to, że aktywna oferta Mesos Master mechanism dodatkowo upraszcza obowiązki Mezos. proces planowania zasobów, dopasowywania zasobów do zadań, w Mezos jest podzielony na dwa etapy: zasoby do zaoferowania i oferta do zadania. Mistrz Mezos jest odpowiedzialny tylko za ukończenie pierwszej fazy, a dopasowanie drugiej fazy pozostaje do ram.
- bardziej elastyczny i zdolny do spełnienia bardziej odpowiedzialnych zasad planowania zadań. Na przykład, strategia wykorzystania zasobów All Or Nothings.
algorytm szeregowania Mezos DRF (dominant Resource Fairness)
jeśli chodzi o algorytm DRF, w rzeczywistości nie ma on nic wspólnego z naszym zrozumieniem architektury Mezos, ale jest bardzo ważny i ważny w Mezos, więc wyjaśnię nieco więcej tutaj.
jak wspomniano powyżej, Mesos oferuje z kolei Framework, więc który Framework powinien być wybrany, aby oferować za każdym razem? Jest to podstawowy problem do rozwiązania przez algorytm DRF. Podstawową zasadą jest uwzględnienie zarówno sprawiedliwości, jak i skuteczności. Spełniając wszystkie wymogi RAM w zakresie zasobów, powinno być jak najbardziej sprawiedliwe, aby uniknąć zużywania przez jedną ramę zbyt wielu zasobów i zagłodzenia innych ram na śmierć.
DRF jest wariantem algorytmu uczciwości min-max. W prostych słowach, jest to, aby wybrać ramy o najniższym dominującym zużyciu zasobów, aby zapewnić ofertę za każdym razem. Jak obliczyć Dominujące wykorzystanie zasobów w ramach? Ze wszystkich typów zasobów zajmowanych przez strukturę, typ zasobu o najniższym wskaźniku zajętości zasobów jest wybierany jako zasób dominujący. Wskaźnik zajmowania zasobów jest dokładnie dominującym wykorzystaniem zasobów w ramach. Na przykład procesor frameworka zajmuje 20% całego zasobu, 30% pamięci i 10% dysku. Tak więc dominujące wykorzystanie zasobów w ramach będzie wynosić 10%, oficjalny termin nazywa dysk jako dominujący zasób, a to 10% nazywa się dominującym wykorzystaniem zasobów.
ostatecznym celem DRF jest równomierna dystrybucja zasobów między wszystkie frameworki. Jeśli Framework X zaakceptuje zbyt wiele zasobów w tej rundzie oferty, to zajmie dużo więcej czasu, aby uzyskać możliwość następnej rundy oferty. Jednak uważni czytelnicy odkryją, że istnieje założenie w tym algorytmie, to znaczy, że po zaakceptowaniu zasobów przez Framework, uwolni je szybko, w przeciwnym razie będą dwie konsekwencje:
- inne struktury umierają z głodu. Jeden Framework a akceptuje większość zasobów w klastrze jednocześnie, a zadanie działa bez zamykania, więc większość zasobów jest zajęta przez Framework a przez cały czas, a inne frameworki nie będą już otrzymywać zasobów.
- Zagłodź się na śmierć. Ponieważ dominujące wykorzystanie zasobów tego frameworka jest zawsze bardzo wysokie, więc nie ma szans na uzyskanie oferty przez długi czas, więc więcej zadań nie może być uruchomionych.
więc Mesos nadaje się tylko do planowania krótkich zadań, a Mesos zostały pierwotnie zaprojektowane do krótkich zadań w centrach danych.
podsumowanie
z dużej architektury cała architektura systemu planowania jest architekturą Master/Slave, koniec Slave jest instalowany na każdej maszynie z wymaganiem zarządzania, który służy do zbierania informacji o hoście i wykonywania zadań na hoście. Master jest głównie odpowiedzialny za planowanie zasobów i harmonogramowanie zadań. Planowanie zasobów ma wyższe wymagania dotyczące wydajności, a planowanie zadań ma wyższe wymagania dotyczące skalowalności. Ogólna tendencja polega na omówieniu dwóch rodzajów oddzielania cła i uzupełnieniu ich różnymi komponentami.
