skalowalne, rozproszone indeksowanie wtórne w Scylla

model danych w Scylla i Apache Cassandra partycjonuje dane między węzłami klastra za pomocą klucza partycji zdefiniowanego przez schemat bazy danych. Używanie klucza partycji zapewnia skuteczny sposób wyszukiwania wierszy za pomocą klucza partycji, ponieważ można znaleźć węzeł, który jest właścicielem wiersza, haszując klucz partycji. Niestety, oznacza to również, że znalezienie wiersza przy użyciu klucza bez partycji wymaga pełnego skanowania tabeli, co jest nieefektywne. Indeksy drugorzędne są mechanizmem w Apache Cassandra, który umożliwia wydajne wyszukiwanie kluczy bez partycji poprzez utworzenie indeksu.
w tym wpisie dowiesz się:
- jak Apache Cassandra implementuje indeksy wtórne przy użyciu indeksowania lokalnego
- dlaczego zdecydowaliśmy się na inną strategię implementacji dla Scylli przy użyciu indeksowania globalnego
- jak wpływa indeksowanie globalne jak należy używać indeksowania wtórnego
- jak tworzyć własne indeksy wtórne i używać ich w zapytaniach CQL aplikacji
tło
wielkość indeksu jest proporcjonalna do wielkości indeksowanych danych. Ponieważ dane w Scylli i Apache Cassandra są dystrybuowane do wielu węzłów, niepraktyczne jest przechowywanie całego indeksu w jednym węźle. Apache Cassandra implementuje indeksy drugorzędne jako indeksy lokalne, co oznacza, że indeks jest przechowywany w tym samym węźle, co dane indeksowane z tego węzła. Zaletą indeksu lokalnego jest to, że zapisy są bardzo szybkie, ale wadą jest to, że odczyty muszą potencjalnie odpytywać każdy węzeł, aby znaleźć indeks do przeprowadzenia wyszukiwania, co sprawia, że lokalne indeksy są niewyważalne dla dużych klastrów. Oprócz natywnych indeksów wtórnych, Apache Cassandra ma również inny lokalny schemat indeksowania, SSTABLE Attached Secondary Index (SASI), który obsługuje złożone zapytania i wyszukiwanie. Jednak z punktu widzenia skalowalności ma dokładnie te same cechy, co oryginalne indeksy wtórne.
zmaterializowane widoki w Scylli i Apache Cassandra są mechanizmem do automatycznego denormalizowania danych z tabeli bazowej do tabeli widoku przy użyciu innego klucza partycji. Rozwiązuje to problem skalowalności lokalnych indeksów, ale wiąże się z kosztem pamięci masowej, ponieważ w najgorszym przypadku trzeba zduplikować całą tabelę. Zmaterializowane widoki nie są zatem zamiennikiem drugorzędnych indeksów dla wszystkich przypadków użycia. Jednak zmaterializowane widoki zapewniają niezbędną infrastrukturę do implementacji drugorzędnych indeksów przy użyciu indeksowania globalnego, co jest podejściem wdrożeniowym przyjętym dla Scylli.
indeksowanie Globalne
Scylla stosuje inne podejście niż Apache Cassandra i implementuje indeksy wtórne za pomocą indeksowania globalnego. W przypadku indeksowania globalnego dla każdego indeksu tworzony jest zmaterializowany Widok. Zmaterializowany Widok ma indeksowaną kolumnę jako klucz partycji i klucz podstawowy (klucz partycji i klucze klastrowe) zindeksowanego wiersza jako klucze klastrowe. Scylla dzieli zindeksowane zapytania na dwie części: (1) zapytanie w tabeli indeksów w celu pobrania kluczy partycji dla zindeksowanej tabeli i (2) zapytanie do zindeksowanej tabeli przy użyciu odzyskanych kluczy partycji. Zaletą tego podejścia jest to, że możemy użyć wartości indeksowanej kolumny, aby znaleźć odpowiedni wiersz tabeli indeksu w klastrze, dzięki czemu odczyty są skalowalne. Minusem tego podejścia jest to, że zapisy są wolniejsze niż w przypadku indeksowania lokalnego ze względu na cały narzut związany z aktualizowaniem widoku indeksu.
zapytania na zindeksowanej kolumnie wyglądają następująco. Załóżmy, że stół wygląda tak:
i zapytanie w kolumnie email, która nie jest kluczem partycji, ale ma indeks:
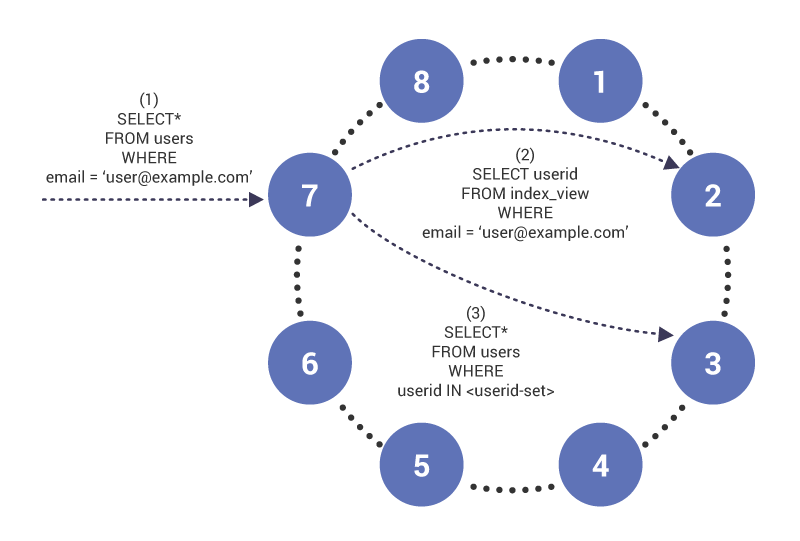
w fazie (1) zapytanie dociera do węzła 7, który działa jako koordynator dla zapytania. Węzeł zauważa, że pytamy o indeksowaną kolumnę i dlatego w phase (2) wystawia tabelę odczytu do indeksu na węźle 2, która ma wiersz tabeli indeksu dla “”. Zapytanie zwraca zestaw identyfikatorów użytkownika, które są używane w phase (3) do pobierania zawartości zindeksowanej tabeli.
przykład
najpierw musimy utworzyć schemat. W tym przykładzie mamy tabelę, która przedstawia informacje o użytkowniku z userid jako kluczem partycji i nazwą, e-mailem i krajem jako zwykłymi kolumnami:
następnie wypełniamy tabelę danymi testowymi wygenerowanymi za pomocą Mockaroo:
indeksy drugorzędne są zaprojektowane tak, aby umożliwić wydajne odpytywanie kolumn kluczy bez partycji. Podczas gdy Apache Cassandra obsługuje również zapytania dotyczące kolumn kluczy bez partycji przy użyciu ALLOW FILTERING, jest to bardzo nieefektywne (wymagające skanowania całej tabeli) i obecnie nie jest obsługiwane przez Scyllę (szczegóły w wydaniu #2200).
kolumny tabeli można indeksować za pomocą instrukcji CREATE INDEX. Na przykład, aby utworzyć indeksy dla kolumn email i country, wykonaj następujące polecenia CQL:
Scylla automatycznie tworzy zmaterializowany widok, który ma indeksowaną kolumnę jako klucz partycji i klucz podstawowy tabeli docelowej (klucz partycji i klucze klastrowe) jako klucze klastrowe.
na przykład zmaterializowany Widok indeksu w kolumnie email wygląda następująco:
jeśli powyższy Widok zostanie utworzony jako zwykła tabela, będzie on wyglądał następująco:
kolumna email jest używana jako klucz partycji dla tabeli indeksu, a useridjest dołączany jako klucz klastrowy, który pozwala nam efektywnie znaleźć klucze partycji dla tabeli docelowej za pomocą tylko email.
możesz użyć polecenia DESCRIBE, aby zobaczyć cały schemat tabeli ks.users, w tym utworzone indeksy i widoki:
teraz z indeksem wtórnym na miejscu, możesz odpytywać indeksowane kolumny tak, jakby były kluczami partycji:
skończyliśmy z tym przykładem!
kiedy stosować indeksy wtórne?
indeksy wtórne są (w większości) przezroczyste dla aplikacji. Zapytania mają dostęp do wszystkich kolumn w tabeli i można dodawać i usuwać indeksy bez zmiany aplikacji. Indeksy drugorzędne mogą również mieć mniej miejsca na dysku niż widoki zmaterializowane, ponieważ indeksy drugorzędne muszą tylko powielać indeksowaną kolumnę i klucz główny, a nie kwerendowane kolumny, jak w przypadku Zmaterializowanego widoku. Ponadto, z tego samego powodu, aktualizacje mogą być bardziej wydajne z drugorzędnymi indeksami, ponieważ tylko zmiany klucza głównego i indeksowanej kolumny powodują aktualizację w widoku indeksu. W przypadku Zmaterializowanego widoku aktualizacja dowolnej kolumny, która pojawia się w widoku, wymaga aktualizacji widoku podkładu.
jak zawsze decyzja, czy użyć drugorzędnych indeksów, czy zmaterializowanych widoków, naprawdę zależy od wymagań Twojej aplikacji. Jeśli potrzebujesz maksymalnej wydajności i prawdopodobnie chcesz wysłać zapytanie do określonego zestawu kolumn, powinieneś użyć widoków zmaterializowanych. Jeśli jednak aplikacja wymaga odpytywania różnych zestawów kolumn, indeksy wtórne są lepszym wyborem, ponieważ można je dodawać i usuwać z mniejszą ilością pamięci masowej w zależności od potrzeb aplikacji.
chcesz dowiedzieć się więcej o indeksach wtórnych? Zobacz moją prezentację z Scylla Summit 2017 na SlideShare. Jeśli chcecie wypróbować tę funkcję, oczekuje się, że pojawi się ona w nadchodzącej wersji Scylla 2.2.