wklęsły Kadłub
Tworzenie granicy klastra przy użyciu podejścia K-najbliżsi sąsiedzi
kilka miesięcy temu napisałem tutaj na Medium artykuł o mapowaniu punktów gorących wypadków drogowych w Wielkiej Brytanii. Byłem głównie zaniepokojony zilustrowaniem zastosowania algorytmu klastrowania DBSCAN na danych geograficznych. W artykule użyłem informacji geograficznych opublikowanych przez rząd brytyjski na temat zgłoszonych wypadków drogowych. Moim celem było przeprowadzenie procesu grupowania opartego na gęstości, aby znaleźć obszary, w których najczęściej zgłaszane są wypadki drogowe. Efektem końcowym było stworzenie zestawu geo-ogrodzeń reprezentujących te gorące miejsca wypadków.
zbierając wszystkie punkty w danym klastrze, możesz zorientować się, jak klaster będzie wyglądał na mapie, ale brakuje Ci ważnej informacji: zewnętrznego kształtu klastra. W tym przypadku mówimy o zamkniętym wielokątu, który może być przedstawiony na mapie jako geo-ogrodzenie. Każdy punkt wewnątrz geo-ogrodzenia można założyć, że należy do klastra, co sprawia, że ten kształt jest interesującą informacją: można go użyć jako funkcji rozróżniającej. Można założyć, że wszystkie nowo pobrane punkty mieszczące się wewnątrz wielokąta należą do odpowiedniego klastra. Jak wspomniałem w artykule, możesz użyć takich wielokątów, aby potwierdzić swoje ryzyko jazdy, używając ich do klasyfikacji własnej pobranej lokalizacji GPS.
teraz pytanie brzmi, jak stworzyć znaczący wielokąt z chmury punktów, które tworzą konkretny klaster. Moje podejście w pierwszym artykule było nieco naiwne i odzwierciedlało rozwiązanie, które już wykorzystałem w kodzie produkcyjnym. Rozwiązanie to polegało na umieszczeniu okręgu wyśrodkowanego na każdym z punktów gromady, a następnie połączeniu wszystkich okręgów razem, tworząc wielokąt w kształcie chmury. Wynik nie jest zbyt ładny, ani realistyczny. Ponadto, używając okręgów jako podstawowego kształtu do budowy końcowego wielokąta, będą one miały więcej punktów niż bardziej opływowy kształt, co zwiększy koszty przechowywania i sprawi, że algorytmy wykrywania włączenia będą wolniejsze w działaniu.

z drugiej strony, takie podejście ma tę zaletę, że jest proste obliczeniowo (przynajmniej z perspektywy programisty), ponieważ wykorzystuje funkcję Shapely cascaded_union do scalania wszystkich okręgów razem. Inną zaletą jest to, że kształt wielokąta jest domyślnie zdefiniowany za pomocą wszystkich punktów w klastrze.
aby uzyskać bardziej wyrafinowane podejście, musimy jakoś zidentyfikować punkty graniczne klastra, te, które wydają się definiować kształt chmury punktów. Co ciekawe, dzięki niektórym implementacjom DBSCAN można odzyskać punkty graniczne jako produkt uboczny procesu klastrowania. Niestety, ta informacja jest (najwyraźniej) niedostępna w implementacji SciKit Learn, więc musimy to zrobić.
pierwszym podejściem, które przyszło na myśl, było obliczenie wypukłości zbioru punktów. Jest to dobrze zrozumiały algorytm, ale cierpi na problem nie Obsługi wklęsłych kształtów, takich jak ten:

ten kształt nie oddaje właściwie istoty punktów leżących poniżej. Gdyby użyto go jako rozróżniacza, niektóre punkty byłyby błędnie zaklasyfikowane jako znajdujące się wewnątrz gromady, gdy nie są. Potrzebujemy innego podejścia.
alternatywa dla wklęsłego kadłuba
na szczęście istnieją alternatywy dla tego stanu rzeczy: możemy obliczyć wklęsły kadłub. Oto jak wygląda wklęsły kadłub po nałożeniu na ten sam zestaw punktów, co na poprzednim obrazku:

a może ten:
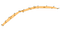
jak widać, i w przeciwieństwie do wypukłego kadłuba, nie ma jednej definicji tego, czym jest wklęsły kadłub zbioru punktów. Z algorytmem, który tu prezentuję, wybór jak wklęsłe mają być wasze kadłuby dokonywany jest poprzez jeden parametr: k – Liczba najbliższych sąsiadów brana pod uwagę przy obliczaniu kadłuba. Zobaczmy, jak to działa.
algorytm
algorytm, który tu prezentuję, został opisany ponad dekadę temu przez Adriano Moreirę i Maribela Yasminę Santosa z Uniwersytetu Minho w Portugalii . Z abstrakcji:
w artykule opisano algorytm obliczania obwiedni zbioru punktów na płaszczyźnie, który generuje wypukłości na nie wypukłych łuskach, które reprezentują obszar zajmowany przez dane punkty. Proponowany algorytm opiera się na podejściu K-najbliżsi sąsiedzi, gdzie wartość K, jedyny parametr algorytmu, jest używany do kontrolowania “gładkość” ostatecznego rozwiązania.
ponieważ zastosuję ten algorytm do informacji geograficznej, trzeba było wprowadzić pewne zmiany, a mianowicie przy obliczaniu kątów i odległości . Ale nie zmieniają one w żaden sposób istoty algorytmu, który można szeroko opisać następującymi krokami:
- Znajdź punkt o najniższej współrzędnej Y (szerokość geograficzna) i ustaw go na bieżącą.
- Znajdź K-najbliższe punkty do bieżącego punktu.
- z najbliższego punktu K wybierz ten, który odpowiada największemu prawostronnemu skręceniu z poprzedniego kąta. Tutaj użyjemy pojęcia łożyska i zaczniemy od kąta 270 stopni (na zachód).
- sprawdź, czy dodając nowy punkt do rosnącego ciągu linii, nie przecina się. Jeśli Tak, wybierz inny punkt z najbliższego punktu k lub uruchom ponownie z większą wartością K.
- Ustaw nowy punkt jako bieżący punkt i usuń go z listy.
- po iteracjach k dodaje pierwszy punkt z powrotem do listy.
- pętla do numeru 2.
algorytm wydaje się być dość prosty, ale jest wiele szczegółów, które muszą być uwzględnione, zwłaszcza że mamy do czynienia ze współrzędnymi geograficznymi. Odległości i kąty są mierzone w inny sposób.
Kod
tutaj publikuję jest dostosowaną wersją kodu poprzedniego artykułu. Nadal znajdziesz ten sam kod klastrowy i ten sam generator klastrów w kształcie chmury. Zaktualizowana wersja zawiera teraz pakiet o nazwie geomath.hulls, w którym można znaleźć klasę ConcaveHull. Aby utworzyć wklęsłe kadłuby, wykonaj następujące czynności:
w powyższym kodzie points jest tablicą wymiarów (N, 2), gdzie wiersze zawierają obserwowane punkty, a kolumny zawierają współrzędne geograficzne (długość, szerokość geograficzna). Wynikowa tablica ma dokładnie tę samą strukturę, ale zawiera tylko punkty, które należą do wielokątnego kształtu klastra. Rodzaj filtra.
ponieważ będziemy zajmować się tablicami, to naturalne, że wprowadzamy NumPy do walki. Wszystkie obliczenia zostały odpowiednio wektoryzowane, o ile to możliwe, i podjęto wysiłki, aby poprawić wydajność podczas dodawania i usuwania elementów z tablic(spoiler: nie są one w ogóle przenoszone). Jednym z brakujących ulepszeń jest równoległość kodu. Ale to może poczekać.
uporządkowałem kod wokół algorytmu, jak pokazano w artykule, chociaż niektóre optymalizacje zostały dokonane podczas tłumaczenia. Algorytm jest zbudowany wokół kilku podprogramów, które są wyraźnie zidentyfikowane przez artykuł, więc pozbądźmy się ich już teraz. Dla wygody czytania, użyję tych samych nazw, co w gazecie.
CleanList-Czyszczenie listy punktów jest wykonywane w konstruktorze klasy:
jak widać, lista punktów jest zaimplementowana jako tablica NumPy ze względu na wydajność. Czyszczenie listy odbywa się na linii 10, gdzie przechowywane są tylko Unikalne punkty. Tablica zbiorów danych jest zorganizowana z obserwacji w wierszach i współrzędnych geograficznych w dwóch kolumnach. Zauważ, że tworzę również tablicę logiczną w linii 13, która będzie używana do indeksowania do głównej tablicy zestawów danych, ułatwiając zadanie usuwania elementów i, raz na jakiś czas, dodając je z powrotem. Widziałem tę technikę zwaną “maską” w dokumentacji NumPy i jest ona bardzo potężna. Jeśli chodzi o liczby pierwsze, omówię je później.
FindMinYPoint-wymaga to małej funkcji:
funkcja ta jest wywoływana z tablicą dataset jako argumentem i zwraca indeks punktu o najniższej szerokości geograficznej. Zauważ, że wiersze są kodowane z długością geograficzną w pierwszej kolumnie i szerokością geograficzną w drugiej.
RemovePoint
AddPoint — są to no-brainery, ze względu na użycie tablicy indices. Tablica ta służy do przechowywania aktywnych indeksów w głównej tablicy zestawu danych, więc usunięcie elementów z zestawu danych jest bardzo proste.
chociaż algorytm opisany w artykule wymaga dodania punktu do tablicy składającej się na kadłub, jest to faktycznie zaimplementowane jako:
później, zmienna test_hull zostanie przypisana z powrotem do hull, gdy łańcuch linii zostanie uznany za nie przecinający się. Ale wyprzedzam grę. Usunięcie punktu z tablicy dataset jest tak proste jak:
self.indices = False
dodanie go z powrotem jest tylko kwestią odwrócenia wartości tablicy w tym samym indeksie z powrotem do true. Ale cała ta wygoda wiąże się z ceną konieczności trzymania naszych kart na indeksach. Więcej na ten temat później.
NearestPoints-tu zaczyna być ciekawie, bo nie mamy do czynienia ze współrzędnymi planarskimi, więc out z Pitagorasem A IN Z Haversine:
należy zauważyć,że drugi i trzeci parametr są tablicami w formacie zestawu danych: Długość geograficzna w pierwszej kolumnie i szerokość geograficzna w drugiej. Jak widać, funkcja ta zwraca tablicę odległości w metrach między punktem w drugim argumencie a punktami w trzecim argumencie. Kiedy już je mamy, możemy łatwo dostać K-najbliższych sąsiadów. Ale jest do tego wyspecjalizowana funkcja i zasługuje na wyjaśnienia:
funkcja rozpoczyna się od utworzenia tablicy z indeksami bazowymi. Są to indeksy punktów, które nie zostały usunięte z tablicy zbiorów danych. Na przykład, jeśli na klastrze dziesięciu punktów zaczniemy od usunięcia pierwszego punktu, tablica indeksów bazowych będzie . Następnie obliczamy odległości i sortujemy wynikowe indeksy tablicy. Pierwsze k są wyodrębniane, a następnie używane jako maska do pobierania indeksów bazowych. Jest trochę zakrzywiony, ale działa. Jak widać, funkcja nie zwraca tablicy współrzędnych, ale tablicy indeksów do tablicy zbiorów danych.
SortByAngle – tu jest więcej kłopotów, bo nie obliczamy prostych kątów, tylko łożyska. Są one mierzone jako zero stopni na północ, z kątami rosnącymi zgodnie z ruchem wskazówek zegara. Oto rdzeń kodu, który oblicza łożyska:
funkcja zwraca tablicę łożysk mierzonych od punktu, którego indeks znajduje się w pierwszym argumencie, do punktów, których indeksy znajdują się w trzecim argumencie. Sortowanie jest proste:
w tym momencie tablica kandydatów zawiera indeksy K-najbliższych punktów posortowane według kolejności malejącej łożyska.
IntersectQ-zamiast toczyć własne funkcje przecięcia linii, zwróciłem się o pomoc do Shapely. W rzeczywistości, budując wielokąt, zasadniczo obsługujemy ciąg linii, dołączając segmenty, które nie przecinają się z poprzednimi. Testowanie tego jest proste: pobieramy powstałą tablicę kadłubów, przekształcamy ją w kształtny obiekt ciągu linii i sprawdzamy, czy jest prosta (nie przecinająca się samoczynnie), czy nie.
krótko mówiąc, kształtny ciąg linii staje się złożony, jeśli się przecina, więc predykat is_simple staje się fałszywy. Spokojnie.
PointInPolygon — ten okazał się najtrudniejszy do wdrożenia. Pozwól, że wyjaśnię, patrząc na kod, który wykonuje ostateczną walidację wielokąta kadłuba (sprawdza, czy wszystkie punkty klastra są zawarte w wielokątu):
funkcje Shapely ‘ ego do testowania przecięcia i Włączenia powinny wystarczyć do sprawdzenia, czy końcowy wielokąt kadłuba pokrywa się ze wszystkimi punktami klastra, ale tak nie było. Dlaczego? Shapely jest agnostykiem współrzędnych, więc będzie obsługiwać współrzędne geograficzne wyrażone w szerokościach i długościach geograficznych dokładnie tak samo jak współrzędne na płaszczyźnie kartezjańskiej. Ale świat zachowuje się inaczej, gdy żyje się na kuli, a kąty (lub łożyska) nie są stałe wzdłuż Geodezji. Doskonale ilustruje to przykład linii geodezyjnej łączącej Bagdad z Osaką. Tak się składa, że w pewnych okolicznościach algorytm może zawierać punkt oparty na kryterium łożyskowania, ale później, używając algorytmów płaskich Shapely ‘ ego, można uznać go zawsze za nieco poza wielokątem. To właśnie robi korekcja małych odległości.
Zajęło mi to trochę czasu. Moją pomocą w debugowaniu był QGIS, świetny kawałek wolnego oprogramowania. Na każdym etapie podejrzanych obliczeń wyprowadzałem dane w formacie WKT do pliku CSV, który miał być odczytany jako warstwa. Prawdziwy ratownik!
wreszcie, jeśli wielokąt nie pokryje wszystkich punktów klastra, jedyną opcją jest zwiększenie k i próba ponownego. Tutaj dodałem trochę własnej intuicji.
Prime k
artykuł sugeruje zwiększenie wartości k o jeden i ponowne wykonanie algorytmu od zera. Moje wczesne testy z tą opcją nie były zbyt satysfakcjonujące: czas pracy byłby powolny na problematycznych klastrach. Było to spowodowane powolnym wzrostem k, więc postanowiłem użyć innego harmonogramu wzrostu: tabeli liczb pierwszych. Algorytm zaczyna się już od k=3, więc było to łatwe rozszerzenie, aby ewoluować na liście liczb pierwszych. To właśnie widzisz w wywołaniu rekurencyjnym:
mam coś do liczb pierwszych, wiesz…
wysadzić w powietrze
wklęsłe wielokąty kadłuba generowane przez ten algorytm nadal wymagają dalszej obróbki, ponieważ będą rozróżniać tylko punkty wewnątrz kadłuba, ale nie blisko niego. Rozwiązaniem jest dodanie wyściółki do tych chudych klastrów. Tutaj używam dokładnie tej samej techniki, co poprzednio, a oto jak to wygląda:

tutaj użyłem funkcji Shapely ‘ ego buffer, aby to zrobić.
funkcja przyjmuje kształtny wielokąt i zwraca nadmuchaną wersję siebie. Drugim parametrem jest Promień w metrach dodanej wyściółki.
uruchamianie kodu
Rozpocznij od pobrania kodu z repozytorium GitHub do lokalnej maszyny. Plik, który chcesz wykonać, to ShowHotSpots.py w głównym katalogu. Po pierwszym wykonaniu kod będzie odczytywał w Wielkiej Brytanii dane o wypadkach drogowych z lat 2013-2016 i gromadził je. Wyniki są następnie buforowane jako plik CSV dla kolejnych uruchomień.
następnie zostaną zaprezentowane dwie mapy: pierwsza jest generowana przy użyciu klastrów w kształcie chmury, podczas gdy druga wykorzystuje omawiany tutaj algorytm klastrowania wklęsłego. Podczas wykonywania kodu generowania wielokątów może pojawić się kilka błędów. Aby pomóc zrozumieć, dlaczego algorytm nie tworzy wklęsłego kadłuba, kod zapisuje klastry do plików CSV do katalogu data/out/failed/. Jak zwykle za pomocą QGIS można importować te pliki jako warstwy.
zasadniczo algorytm ten zawodzi, gdy nie znajduje wystarczającej ilości punktów ,aby” obejść ” kształt bez samorozcinania. Oznacza to, że musisz być gotowy albo odrzucić te klastry, albo zastosować do nich inną obróbkę (wypukły kadłub lub połączone pęcherzyki).
wklęsłość
to okład. W tym artykule przedstawiłem metodę przetwarzania końcowego klastrów geograficznych generowanych przez DBSCAN w wklęsłe kształty. Metoda ta może zapewnić lepiej dopasowany wielokąt zewnętrzny dla klastrów w porównaniu z innymi alternatywami.
dziękuję za przeczytanie i miłego majsterkowania przy kodzie!
Kryszkiewicz M., Lasek P. (2010) Ti-DBSCAN: klastrowanie z DBSCAN za pomocą nierówności trójkąta. W: Szczuka M., Kryszkiewicz M., Ramanna S., Jensen R., Hu Q. (red.) Rough Sets and Current Trends in Computing. RSCTC 2010. Lecture Notes in Computer Science, vol 6086. Springer, Berlin, Heidelberg
Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, pp. 2825-2830, 2011
Moreira, A. and Santos, M. Y., 2007, Concave Hull: A K-nearest neighbours approach for the computing of the region occupied by a set of points
Calculate distance, bearing and more between Latitude / Longitude points
GitHub repository