wspólne Wyszukiwanie: projekt open source przywraca PageRank
Zapisz się na nasze codzienne podsumowanie ciągle zmieniającego się krajobrazu marketingu w wyszukiwarkach.
Uwaga: przesyłając ten formularz, wyrażasz zgodę na warunki Third Door Media. Szanujemy Twoją prywatność.

w ciągu ostatnich kilku lat Google powoli zmniejszało ilość danych dostępnych dla praktyków SEO. Najpierw były to dane słów kluczowych, potem wynik PageRank. Teraz jest to konkretny wolumen wyszukiwania z AdWords (chyba, że wydajesz trochę moola). Możesz przeczytać więcej na ten temat w doskonałym artykule Russa Jonesa, który szczegółowo opisuje wpływ badań jego firmy i wgląd w dane clickstream dla disambiguacji wolumenu.
jednym z elementów, w które naprawdę się ostatnio zaangażowaliśmy, są Common Crawl data. Jest kilka drużyn w naszej branży, które używają tych danych od jakiegoś czasu, więc trochę się spóźniłem na grę. Common Crawl data to projekt open source, który regularnie scrapuje cały internet. Na szczęście Amazon, będąc świetną firmą, wpadł do przechowywania danych, aby udostępnić je wielu osobom bez wysokich kosztów przechowywania.
oprócz Common Crawl data istnieje organizacja non-profit o nazwie Common Search, której misją jest stworzenie alternatywnej, otwartej i przejrzystej Wyszukiwarki — pod wieloma względami odwrotnej do Google. To wzbudziło moje zainteresowanie, ponieważ oznacza to, że wszyscy możemy grać, modyfikować i manipulować sygnałami, aby dowiedzieć się, jak działają wyszukiwarki bez ogromnej inwestycji czasu, począwszy od punktu zerowego.
Common Search data
obecnie Common Search wykorzystuje następujące źródła danych do obliczania rankingów wyszukiwania (są one pobierane bezpośrednio ze strony internetowej):
- Common Crawl: największe otwarte repozytorium danych indeksowania sieci. Jest to obecnie nasze unikalne źródło surowych danych strony.
- Wikidata: Bezpłatna, powiązana baza danych, która działa jako centralne miejsce przechowywania ustrukturyzowanych danych wielu projektów Wikimedia, takich jak Wikipedia, Wikivoyage i Wikisource.
- Czarna lista UT1: utrzymywana przez Fabrice Prigent z Université Toulouse 1 Capitole, ta czarna lista kategoryzuje domeny i adresy URL na kilka kategorii, w tym” dla dorosłych “i” phishing.”
- DMOZ: znany również jako Open Directory Project, jest najstarszym i największym katalogiem internetowym wciąż żywym. Chociaż jego dane nie są tak wiarygodne, jak w przeszłości, nadal Używamy go jako źródła sygnału i metadanych.
- wykresy hiperłączy Web Data Commons: wykresy wszystkich hiperłączy z archiwum wspólnego indeksowania 2012. Obecnie używamy pliku Harmonic Centrality jako tymczasowego sygnału rankingowego na domenach. W niedalekiej przyszłości planujemy wykonać własną analizę wykresu internetowego.
- Alexa top 1m sites: Alexa pozycjonuje strony internetowe na podstawie połączonej miary odsłon strony i unikalnych użytkowników witryny. Wiadomo, że jest stronniczy demograficznie. Używamy go jako tymczasowego sygnału rankingowego na domenach.
wspólny ranking wyszukiwań
oprócz tych źródeł danych, do badania kodu wykorzystuje również długość URL, długość ścieżki i PageRank domeny jako sygnały rankingowe w swoim algorytmie. I oto, od lipca, Common Search ma swoje własne dane o Pagerank na poziomie hosta i wszyscy to przegapiliśmy.
za chwilę przejdę do PageRank (PR), ale ciekawie jest przejrzeć kod Common Crawl, zwłaszcza rankera.py część znajduje się tutaj, ponieważ naprawdę można dostać się do fotela kierowcy z podkręcania wagi sygnałów, które wykorzystuje do rangi stron:
signal_weights = {"url_total_length": 0.01,"url_path_length": 0.01,"url_subdomain": 0.1,"alexa_top1m": 5,"wikidata_url": 3,"dmoz_domain": 1,"dmoz_url": 1,"webdatacommons_hc": 1,"commonsearch_host_pagerank": 1}
na szczególną uwagę zasługuje również to, że wspólne Wyszukiwanie wykorzystuje BM25 jako miarę podobieństwa słowa kluczowego do treści dokumentu i metadanych. BM25 jest lepszym miernikiem niż TF-IDF, ponieważ uwzględnia długość dokumentu, co oznacza, że dokument 200-słowny, który ma słowo kluczowe pięć razy, jest prawdopodobnie bardziej odpowiedni niż dokument 1500-słowny, który ma go tyle samo razy.
warto również powiedzieć, że liczba sygnałów jest tutaj bardzo prymitywna i oczywiście brakuje wielu udoskonaleń (i danych), które Google zintegrowało w swoim algorytmie Rankingu wyszukiwania. Jedną z kluczowych rzeczy, nad którymi pracujemy, jest wykorzystanie danych dostępnych w Common Crawl i infrastrukturze Common Search do wyszukiwania wektorowego treści, które są istotne w oparciu o semantykę, a nie tylko dopasowywanie słów kluczowych.
on to PageRank
na stronie tutaj znajdziesz linki do PageRank na poziomie hosta dla wspólnego indeksowania czerwca 2016. Używam tego, który ma prawo pagerank-top1m.txt.gz (top 1 milion), ponieważ drugi plik to 3GB i ponad 112 milionów domen. Nawet w R nie mam wystarczającej ilości maszyny, aby ją załadować bez zamykania.
po pobraniu, będziesz musiał wprowadzić plik do katalogu roboczego w R. dane PageRank z Common Search nie są znormalizowane, a także nie są w czystym formacie 0-10, do którego wszyscy jesteśmy przyzwyczajeni. Wspólne Wyszukiwanie używa “max (0, min (1, float(rank) / 244660.58)) ” — zasadniczo ranga domeny podzielona przez rangę Facebooka-jako metoda przekładania danych na dystrybucję między 0 a 1. Ale to pozostawia pewne określone luki, w tym, że pozostawi to PageRank Linkedin jako 1.4 po skalowaniu przez 10.

poniższy kod załaduje zestaw danych i doda kolumnę PR z lepszym przybliżonym PR:
#Grab the datadf <- read.csv("pagerank-top1m.txt", header = F, sep = " ")#Log NormalizelogNorm <- function(x){ #Normalize x <- (x-min(x))/(max(x)-min(x)) 10 / (1 - (log10(x)*.25))}#Append a Column named PR to the datasetdf$pr <- (round(logNorm(df$V2),digits = 0))
musieliśmy trochę pobawić się liczbami, aby dostać się gdzieś blisko (dla kilku próbek domen, dla których pamiętałem PR) do starego Google PR. Poniżej kilka przykładowych wyników PageRank:
- en.wikipedia.org
- searchengineland.com
- consultwebs.com
- youtube.com
- moz.com (6)
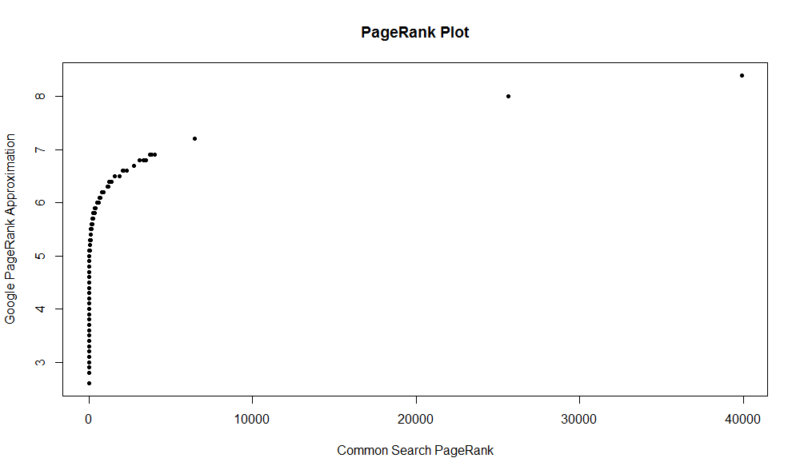
oto wykres 100 000 losowych próbek. Obliczony wynik PageRank jest wzdłuż osi Y, a oryginalny wspólny wynik wyszukiwania jest wzdłuż osi X.
aby pobrać własne wyniki, możesz uruchomić następujące polecenie w R (wystarczy podstawić własną domenę):
df

należy pamiętać, że ten zbiór danych ma tylko jeden milion najlepszych domen według PageRank, więc z 112 milionów domen, które są indeksowane przez wspólne Wyszukiwanie, istnieje duża szansa, że Twoja witryna może tam nie być, jeśli nie ma całkiem dobrego profilu linków. Ponadto ta metryka nie zawiera żadnych oznak szkodliwości linków, a jedynie przybliżenie popularności Twojej witryny w odniesieniu do linków.
wspólne Wyszukiwanie to świetne narzędzie i świetny fundament. Z niecierpliwością czekam na większe zaangażowanie w tamtejszą społeczność i mam nadzieję, że nauczę się lepiej rozumieć nakrętki i śruby stojące za wyszukiwarkami, pracując nad jedną z nich. Dzięki R i odrobinie kodu możesz szybko sprawdzić PR dla miliona domen w ciągu kilku sekund. Mam nadzieję, że się podobało!
Zapisz się na nasze codzienne podsumowanie ciągle zmieniającego się krajobrazu marketingu w wyszukiwarkach.
Uwaga: przesyłając ten formularz, wyrażasz zgodę na warunki Third Door Media. Szanujemy Twoją prywatność.
o autorze

JR Oakes jest starszym dyrektorem technicznych badań SEO w Locomotive. Wcześniej był dyrektorem działu technicznego SEO w agencji Adapt Partners. Współpracuje z klientami w szerokim zakresie zagadnień technicznych, wydajności, CTR, crawl-ability, treści i analizy danych. JR uwielbia testowanie, kodowanie i prototypowanie rozwiązań trudnych problemów związanych z marketingiem w wyszukiwarkach. Kiedy nie pracuje, lubi czytać o nowych technologiach, grać na gitarze basowej, oglądać koszykówkę w college ‘ u, gotować i spędzać czas z przyjaciółmi i rodziną. Jest również jednym ze współorganizatorów Raleigh SEO Meetup, Raleigh SEO Conference i RTP SEO Meetup.