Agrupamento e K significa: definição e Análise de clusters no Excel
definições de Estatísticas > Clustering / Cluster Analysis
What is Clustering?
Clustering in statistics refers to how data is gathered (“clustered”) by factors like:
- idade.
- Tamanho do agregado familiar.
- rendimento.
- Ou nível de ensino.
a Classificação dos dados em aglomerados leva, por vezes, a uma maior investigação dos dados. Por exemplo, os clusters cancerígenos podem indicar algum problema no ambiente. Ou podem ser apenas o resultado da Natureza ser aleatória. A análise de Cluster tende a ser subjetiva em muitos casos; depende do que você percebe como threads comuns nos dados. A técnica não é realmente nada de novo nas estatísticas; se você já fez um gráfico de barras, você provavelmente já fez clusters (mesmo se você não chamou isso). Por exemplo, um gráfico de barras que mostra raças de cães requer que você agrupar por raça (Husky Siberiano, Border Collie, pastor alemão…) ou um gráfico de níveis de renda pode ser agrupado por baixos, médios e altos níveis de renda.
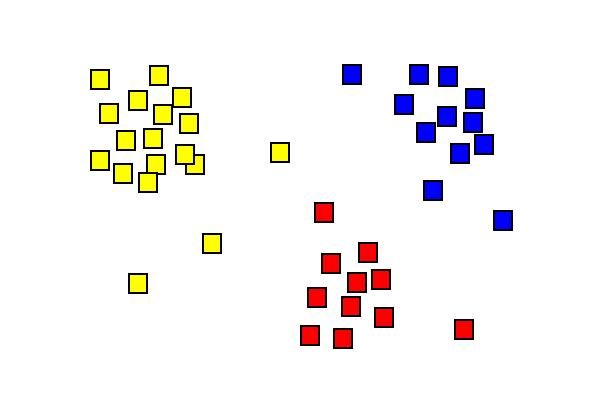
resultados de Análise de aglomerado mostrando três grupos coloridos diferentes.
os aglomerados podem ser baseados em factores como::
- agrupamento à distância. Os itens são ordenados com base na sua proximidade (ou distância). Por exemplo, os casos de cancro podem ser agrupados se estiverem na mesma localização geográfica.
- clustering Conceptual. Os itens são agrupados por fatores que os itens têm em comum. Por exemplo, os clusters cancerígenos poderiam ser agrupados por “pessoas que trabalham na fabricação.”
Tipos De Agrupamento
- Agrupamento Exclusivo. Cada item só pode pertencer a um único conjunto. Não pode pertencer a outro grupo.
- agrupamento difuso: aos pontos de dados é atribuída uma probabilidade de pertencer a um ou mais aglomerados.
- Agrupamento Sobreposto. Cada item pode pertencer a mais de um grupo.
- Clustering Hierárquico. Esta é uma abordagem mais complexa para a agregação usada na mineração de dados. Basicamente, cada item é dado o seu próprio conjunto. Um par de aglomerados é unido com base em semelhanças, dando um aglomerado a menos. Este processo é repetido até que todos os itens sejam agrupados. O dendrograma é um grafo que mostra clusters hierárquicos.
- Clustering Probabilistic. Os dados são agrupados usando algoritmos que conectam itens usando distâncias ou densidades. Isto é geralmente realizado por um computador.
- Ward’s method: uses minimum variance in each step to create relatively small, even-sized clusters.
K significa agrupamento
agrupamento é apenas uma forma de agrupar um conjunto de dados em conjuntos mais pequenos. As duas formas de agrupar um conjunto de dados são quantitativamente (usando números) e qualitativamente (usando categorias). Por exemplo, livros sobre Amazon.com são listados tanto por categoria (qualitativa) quanto por best seller (quantitativo). K-means clustering é uma das mais simples algoritmos de aprendizagem supervisionada, que resolve problemas de clustering usando um método quantitativo: você pré-defina um número de clusters e empregar um algoritmo simples para classificar os dados. Dito isto, “simples” no mundo da computação não equivale a simples na vida real. Este é na verdade um problema NP-hard, então você vai querer usar software para K-means clustering. Alguns programas que irão realizar isso para você (clique no link para o procedimento) são:
- SPSS.
- R
- MATLAB
:
- decidir quantos grupos (k).
- colocar k pontos centrais em diferentes locais (geralmente distantes um do outro).
- tomar cada ponto de dados e colocá-lo perto do ponto central apropriado. Repetir até que todos os pontos de dados tenham sido atribuídos.
- recalcular k novos pontos centrais como baricentros.
- Repita a atribuição de pontos de dados, desta vez para o novo ponto central (o baricentro).
- repetir 4 e 5 até que os pontos centrais (baricentros) não se movam mais.
K-significa agrupamento: uma definição mais Formal
uma forma mais formal de definir a clustering significa K é categorizar objetos n Em K(k>1) Grupos pré-definidos. O objetivo é minimizar a distância de cada ponto de dados para o aglomerado. Por outras palavras, para encontrar:
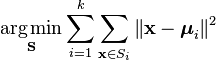
:
X é um ponto de dados
k é o número de aglomerados
ui é a média dos pontos em Si.
Análise de clusters vs. análise discriminante
análise de Clusters é muito semelhante à análise discriminante. Ambos os métodos envolvem separação em grupos. No entanto, a análise de clusters é uma forma de identificar os grupos, enquanto a análise discriminante requer que você conheça os grupos antes de começar a análise. Por exemplo, digamos que tinha um grupo de pacientes psiquiátricos com comportamentos anormais. A análise de clusters pode ajudá-lo a encontrar grupos distintos, como pacientes com histórico de abuso, aqueles com TEPT, ou aqueles que experimentam alucinações. Se você fosse fazer uma análise discriminante no mesmo grupo de pessoas, você deve conhecer os diagnósticos dos pacientes antes de começar a colocá-los em grupos.
Clustering in Excel
Microsoft Excel has a data mining add-in for making clusters. Você pode encontrar instruções aqui. O assistente trabalha com tabelas, gamas ou consultas de pesquisa de análise do Excel. Este add-in pode ser personalizado, ao contrário da ferramenta detectar Categorias. Além disso, a Ferramenta de categorias de detecção está limitada aos dados das tabelas.
a utilizar:
- Descarregue e instale o Add-in de mineração de dados.
- Click “Data Mining,” then click “Cluster,” then ” Next.”
- diga ao Excel onde estão os seus dados. Por exemplo, selecione uma gama de dados. A página de agrupamento ficará disponível.
- Clustering: deixe como é para o agrupamento automático, ou você pode especificar um número de grupos.
- Segments: leave as is for automatic grouping, or specify a number of categories.
Stephanie Glen. “Clustering and K Means: Definition & Cluster Analysis in Excel” From StatisticsHowTo.com: Estatísticas elementares para o resto de nós! https://www.statisticshowto.com/clustering/
——————————————————————————
Precisa de ajuda com a lição de casa ou a pergunta de teste? Com o estudo Chegg, você pode obter soluções passo a passo para suas perguntas de um especialista no campo. Os seus primeiros 30 minutos com um tutor Chegg são grátis!