armazenamento de dados em nuvem vs conceitos tradicionais de armazenamento de dados
armazenamento de dados em nuvem são a nova norma. Longe vão os dias em que seu negócio teve que comprar hardware, criar salas de servidor e contratar, treinar e manter uma equipe dedicada de funcionários para geri-lo. Agora, com alguns cliques em seu laptop e um cartão de crédito, você pode acessar praticamente ilimitado poder de computação e espaço de armazenamento.No entanto, isto não significa que as ideias tradicionais do armazém de dados estejam mortas. A teoria clássica do armazém de dados sustenta a maior parte do que os armazéns de dados baseados em nuvem fazem.
neste artigo, explicaremos os conceitos tradicionais de armazenamento de dados que você precisa conhecer e os mais importantes de uma seleção dos principais provedores: Amazon, Google e Panoply. Finalmente, vamos terminar com uma análise de custo-benefício de armazéns de dados tradicionais vs. cloud, então você sabe qual é o mais certo para você.Vamos começar.
- conceitos tradicionais de Data Warehouse
- factos, dimensões e medidas
- Normalização e desnormalização
- Modelos de Dados
- quadro factual
- Star Schema vs. Snowflake Schema
- OLAP vs. OLTP
- Arquitectura de três níveis
- Data Warehouse / Data Mart
- Kimball vs. Inmon
- ETL vs. ELT
- Enterprise Data Warehouse
- os conceitos de armazenamento de dados em nuvem
- Clusters
- nós
- partições/fatias
- armazenamento colunar
- Compressão
- data Loading
- Cloud Database Warehouse-Google BigQuery
- serviço sem serventia
- Colossus File System
- Dremel Execution Engine
- partilha de dados
- Streaming and Batch Ingestion
- Cloud Data Warehouse Concepts – Panoply
- chaves primárias
- Incremental Keys
- dados aninhados
- tabelas de História
- transformações
- String Formats
- Data Protection
- Controle de acesso
- IP Whitelisting
- Conclusion: Traditional vs. Data Warehouse Concepts in Brief
- conceitos tradicionais de Data Warehouse
- Cloud Data Warehouse Concepts-Amazon Redshift as Example
- Cloud Data Warehouse Concepts-BigQuery as Example
- Tradicional versus Nuvem Análise de Custo-Benefício
- Saiba Mais sobre Armazéns de Dados
conceitos tradicionais de Data Warehouse
um data warehouse é qualquer sistema que recolhe dados de uma vasta gama de fontes dentro de uma organização. Os armazéns de dados são utilizados como repositórios de dados centralizados para fins analíticos e de reporte.
um armazém de dados tradicional está localizado no local em seus escritórios. Você compra o hardware, as salas do servidor e contrata a equipe para geri-lo. Eles também são chamados de “on-premes”, “on-prem” ou “gramatically incorrect”.
factos, dimensões e medidas
os elementos fundamentais da informação num armazém de dados são factos, dimensões e medidas.
um fato é a parte dos seus dados que indica uma ocorrência ou transação específica. Por exemplo, se o seu negócio vende flores, alguns fatos que você veria em seu armazém de dados são:
- vendi 30 rosas na loja por 19 dólares.99
- encomendou 500 novos vasos de flores da China por $1500
- salário pago do caixa para este mês $1000
vários números podem descrever cada fato, e chamamos esses números de medidas. Algumas medidas para descrever o fato de “ordenados de 500 novos vasos da China por us $1500′ são:
- Quantidade de ordem – 500
- Custo – $1500
Quando os analistas estão trabalhando com dados, realizar cálculos sobre as medidas (por exemplo, soma, máximo, média), para colher insights. Por exemplo, você pode querer saber o número médio de vasos de flores que você encomenda a cada mês.
uma dimensão categoriza fatos e medidas e fornece informações estruturadas de rotulagem para eles – caso contrário, eles seriam apenas uma coleção de números não encomendados! Algumas dimensões para descrever o fato de “ordenados de 500 novos vasos da China por us $1500′ são:
- País adquirido da – China
- Tempo comprado – 1 pm
- data prevista de chegada – 6 de junho
não é possível executar cálculos em dimensões explicitamente, e isso provavelmente não seria muito útil – como você pode encontrar a “média data de chegada de ordens’? No entanto, é possível criar novas medidas a partir de dimensões, que são úteis. Por exemplo, se você souber o número médio de dias entre a data de encomenda e a data de chegada, você pode planejar melhor as compras de ações.
Normalização e desnormalização
normalização é o processo de organização eficiente de dados em um armazém de dados (ou qualquer outro lugar que armazena dados). Os principais objetivos são reduzir a redundância de dados – por exemplo, de remover quaisquer dados duplicados e melhorar a integridade dos dados – por exemplo, melhorar a precisão dos dados. Existem diferentes níveis de Normalização e nenhum consenso para o método “melhor”. No entanto, todos os métodos envolvem o armazenamento de informações separadas, mas relacionadas, em diferentes tabelas.
há muitos benefícios para a normalização, tais como:
- mais Rápido pesquisa e classificação em cada tabela
- mais Simples tabelas de fazer modificação de dados comandos mais rápido para gravar e executar o
- Menos redundante de dados significa que você economizar espaço em disco, e então você pode coletar e armazenar mais dados
Denormalization é o processo de, deliberadamente, a adição de cópias redundantes ou grupos de dados, já normalizado de dados. Não é o mesmo que dados não normalizados. A desnormalização melhora o desempenho de leitura e torna muito mais fácil manipular tabelas em formas que você deseja. Quando os analistas trabalham com armazéns de dados, eles normalmente só realizam leituras sobre os dados. Assim, dados desnormalizados podem salvá-los grandes quantidades de tempo e dores de cabeça.
Benefícios de denormalization:
- Menos mesas minimizar a necessidade de tabela de associações que acelera a importação de dados dos analistas de fluxo de trabalho e leva-los a descobrir mais informações úteis em dados
- Menos mesas simplificar as consultas, levando a menos bugs
Modelos de Dados
seria extremamente ineficiente para armazenar todos os seus dados em uma grande tabela. Então, seu data warehouse contém muitas tabelas que você pode juntar para obter informações específicas. A tabela principal é chamada de tabela de fatos, e tabelas de dimensão cercam-no.
o primeiro passo na concepção de um armazém de dados é construir um modelo conceptual de dados que defina os dados que deseja e as relações de alto nível entre eles.
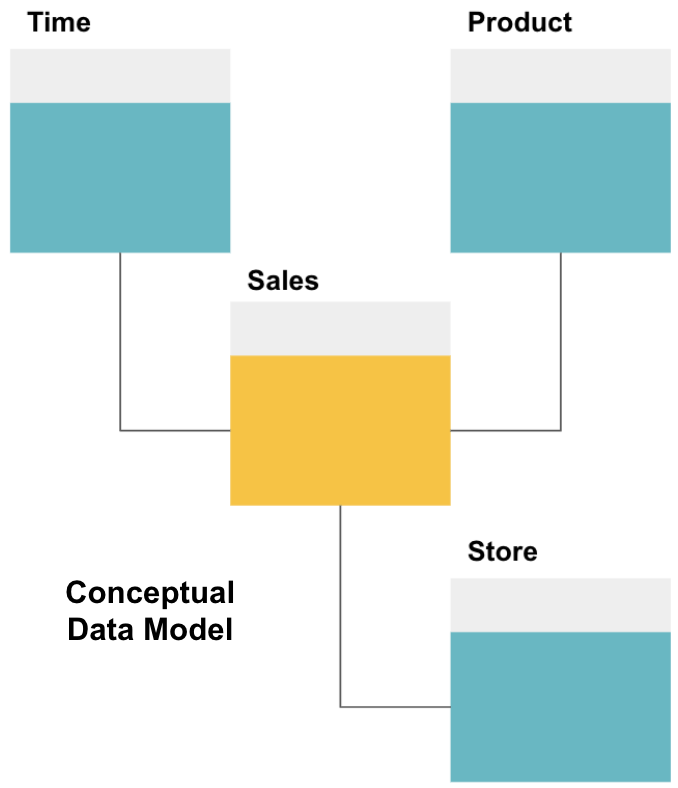
aqui, definimos o modelo conceitual. Estamos armazenando dados de vendas e temos três tabelas adicionais – Tempo, produto e loja – que fornecem informações extra, mais granulares sobre cada venda. A tabela de fatos são as vendas, e as outras são tabelas de dimensão.
o próximo passo é definir um modelo de dados lógicos. Este modelo descreve os dados em detalhes em Inglês claro, sem se preocupar com a forma de implementá-lo em código.
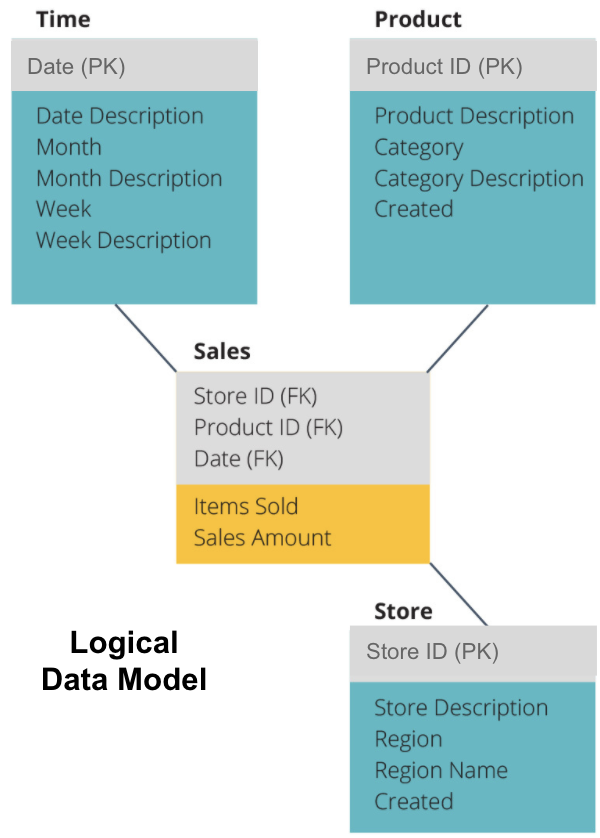
agora nós preenchemos as informações que cada tabela contém em inglês puro. Cada uma das tabelas de dimensão de tempo, Produto e armazenamento mostra a chave primária (PK) na caixa cinza e os dados correspondentes nas caixas azuis. A tabela de vendas contém três chaves estrangeiras (FK) para que ele possa rapidamente se juntar com as outras tabelas.
a fase final é criar um modelo de dados físicos. Este modelo diz-lhe como implementar o armazém de dados em código. Define as tabelas, sua estrutura e a relação entre elas. Ele também especifica tipos de dados para colunas, e tudo é nomeado como será no armazém de dados final, ou seja, todos os caps e conectado com underscores. Por último, cada tabela de dimensões começa com o DIM_, e cada tabela de factos começa com o FACT_.
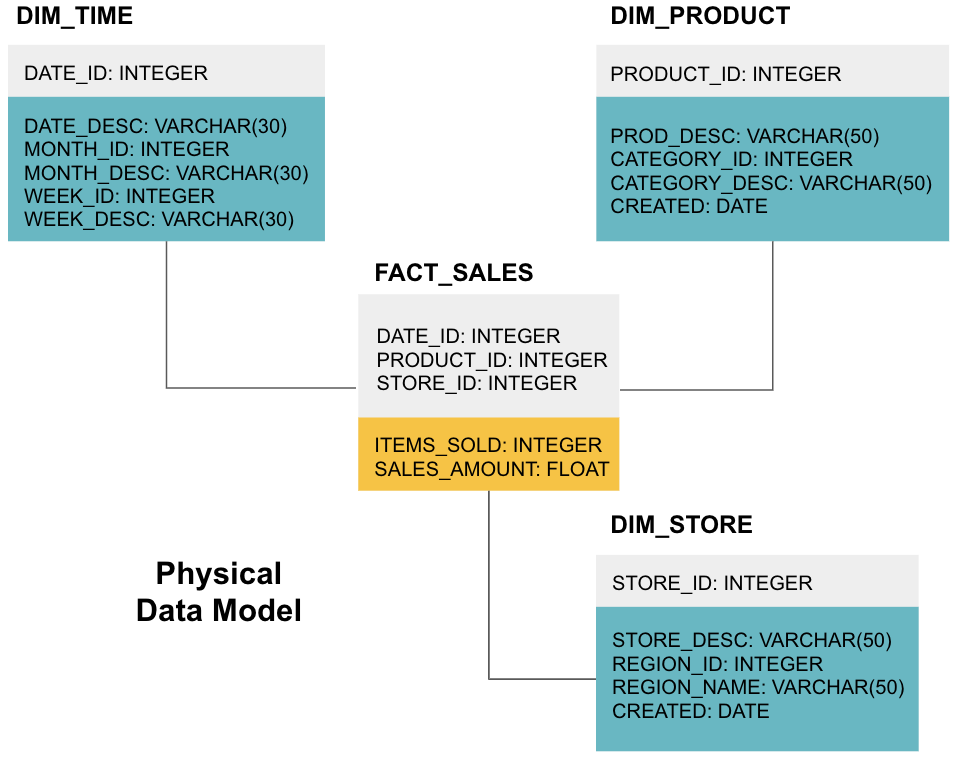
agora você sabe como projetar um armazém de dados, mas há algumas nuances para tabelas de fatos e dimensões que vamos explicar a seguir.
quadro factual
cada função comercial-por exemplo, Vendas, marketing, Finanças – tem uma tabela factual correspondente.
as tabelas Fact têm dois tipos de colunas: colunas dimensionais e Colunas factuais. As colunas dimensionais-coloridas a cinzento nos nossos exemplos-contêm chaves estrangeiras (FK) que você usa para se juntar a uma tabela de factos com uma tabela dimensional. Estas chaves estrangeiras são as chaves primárias (PK) para cada uma das tabelas de dimensões. As colunas de fato-coloridas de amarelo em nossos exemplos-contêm os dados reais e as medidas a serem analisadas, por exemplo, o número de itens vendidos e o valor total em Dólares das vendas.
uma tabela de fatos sem fatos é um tipo particular de tabela de fatos que só tem colunas dimensionais. Tais tabelas são úteis para acompanhar eventos, como a presença do estudante ou a licença do empregado, já que as dimensões lhe dizem tudo o que você precisa saber sobre os eventos.
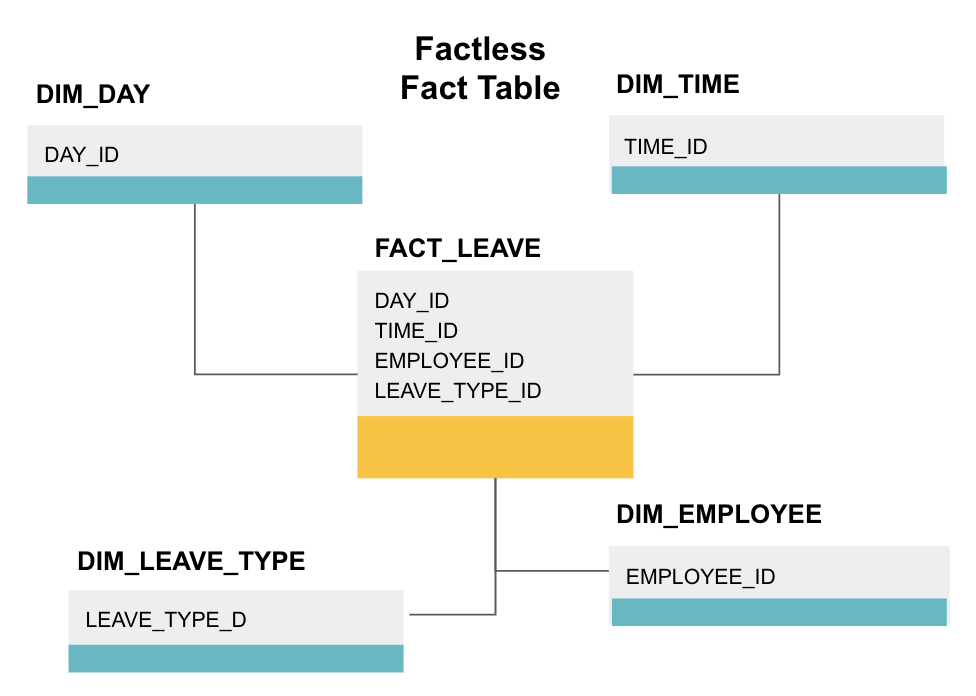
a tabela de factos acima mostra a saída dos empregados. Não há factos, uma vez que só precisas de saber:
- em que dia (de folga) estavam?
- quanto tempo estiveram desligados (TIME_ID).
- que estava de licença (empregado).
- sua razão para estar de licença, e.g., doença, férias, consulta médica, etc. (LEAVE_TYPE_ID).
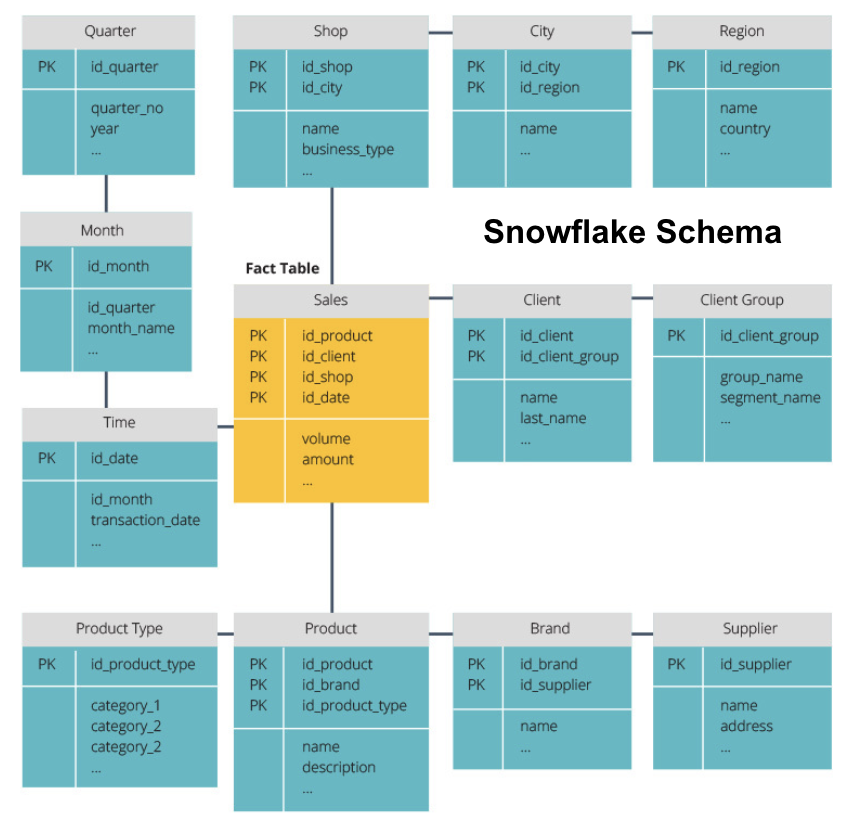
Star Schema vs. Snowflake Schema
os armazéns de dados acima têm todos um layout semelhante. No entanto, esta não é a única forma de Os organizar.
os dois esquemas mais comuns usados para organizar armazéns de dados são estrelas e flocos de neve. Ambos os métodos utilizam tabelas dimensionais que descrevem a informação contida numa tabela fact.
o esquema estelar pega a informação da tabela de fatos e divide-a em tabelas dimensionais desnormalizadas. A ênfase para o esquema estelar é na velocidade da consulta. Apenas uma junção é necessária para ligar tabelas de fatos a cada dimensão, por isso questionar cada tabela é fácil. No entanto, uma vez que as tabelas são desnormalizadas, elas muitas vezes contêm dados repetidos e redundantes.
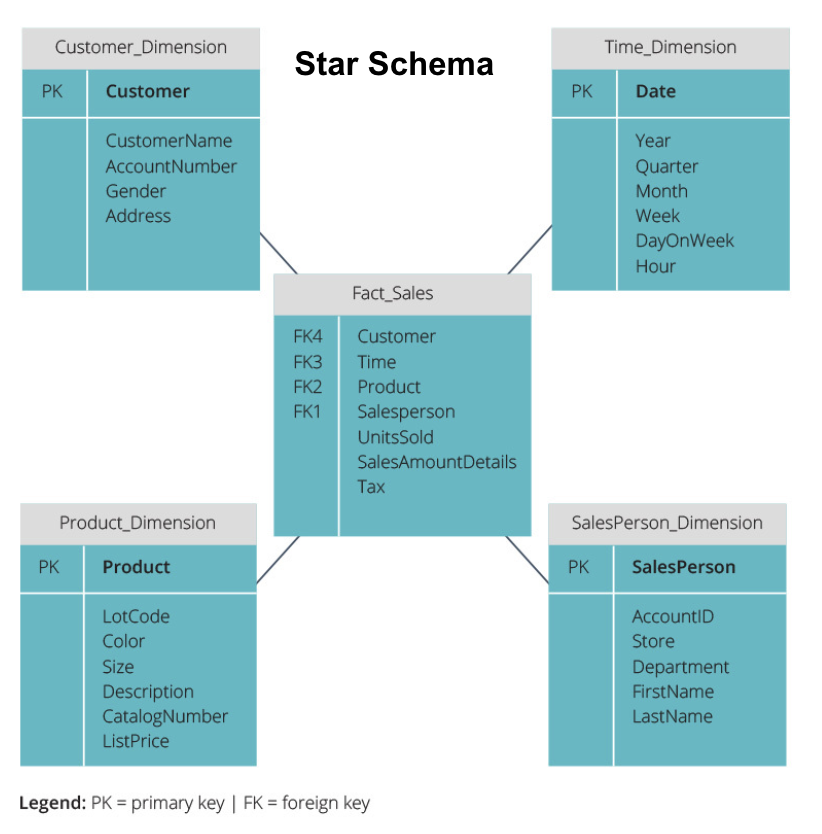
o esquema do floco de neve divide a tabela de fatos em uma série de tabelas dimensionais normalizadas. Normalizar cria mais tabelas de dimensão, e assim reduz os problemas de integridade de dados. No entanto, questionar é mais desafiador usando o esquema do floco de neve porque você precisa de mais ligações de tabela para acessar os dados relevantes. Então, você tem dados menos redundantes, mas é mais difícil de acessar.
agora vamos explicar alguns conceitos fundamentais de data warehouse.
OLAP vs. OLTP
o processamento de transações Online (OLTP) é caracterizado por transações de escrita curta que envolvem as aplicações front-end da arquitetura de dados de uma empresa. As bases de dados OLTP enfatizam o processamento rápido de consultas e só lidam com os dados atuais. As empresas usam essas informações para capturar informações para processos de negócios e fornecer dados fonte para o armazém de dados.
o processamento analítico Online (OLAP) permite que você execute consultas complexas de leitura e, assim, realizar uma análise detalhada dos dados históricos transacionais. Os sistemas OLAP ajudam a analisar os dados no armazém de dados.
Arquitectura de três níveis
os armazéns de dados tradicionais estão tipicamente estruturados em três níveis:
- nível inferior: um servidor de banco de dados, tipicamente um RDBMS, que extrai dados de diferentes fontes usando um gateway. As fontes de dados introduzidas neste nível incluem bases de dados operacionais e outros tipos de dados front-end, tais como ficheiros CSV e JSON.
- nível médio: um servidor OLAP que implementa diretamente as operações, ou
- mapeia as operações em dados multidimensionais para operações relacionais padrão, por exemplo, achatando dados XML ou JSON em linhas dentro das tabelas.
- nível superior: as ferramentas de consulta e comunicação para análise de dados e inteligência de negócios.
Data Warehouse / Data Mart
Virtual data warehousing usa consultas distribuídas em várias bases de dados, sem integrar os dados num único armazém de dados físicos.Os “Data marts” são subconjuntos de armazéns de dados orientados para funções comerciais específicas, tais como vendas ou finanças. Um data warehouse normalmente combina informações de vários data marts em várias funções de negócios. No entanto, um data mart contém dados de um conjunto de sistemas fonte para uma função de Negócio.
Kimball vs. Inmon
existem duas abordagens para o design de data warehouse, propostas por Bill Inmon e Ralph Kimball. Bill Inmon é um cientista da computação estadunidense que é reconhecido como o pai do data warehouse. Ralph Kimball é um dos arquitetos originais do data warehousing e escreveu vários livros sobre o tema.
os dois peritos tinham opiniões contraditórias sobre a forma como os armazéns de dados devem ser estruturados. Este conflito deu origem a duas escolas de pensamento.
a abordagem Inmon é um design top-down. Com a metodologia Inmon, o data warehouse é criado primeiro e é visto como o componente central do ambiente analítico. Os dados são então resumidos e distribuídos do armazém centralizado para um ou mais marts de dados dependentes.
a abordagem Kimball tem uma visão bottom-up do projeto do data warehouse. Nesta arquitetura, uma organização cria Marte de dados separados, que fornecem vistas em departamentos únicos dentro de uma organização. O data warehouse é a combinação destes data marts.
ETL vs. ELT
Extract, Transform, Load (ETL) descreve o processo de extração de dados a partir de sistemas de origem (normalmente sistemas transacionais), convertendo os dados para um formato ou estrutura adequada para a consulta e análise, e, finalmente, carregá-lo para o armazém de dados. O ETL utiliza uma base de dados separada e aplica uma série de regras ou funções aos dados extraídos antes do Carregamento.
Extract, Load, Transform (ELT) is a different approach to loading data. ELT pega os dados de fontes díspares e carrega-os diretamente para o sistema alvo, como o data warehouse. O sistema então transforma os dados carregados On-demand para permitir a análise.
ELT oferece carga mais rápida do que o ETL, mas requer um sistema poderoso para realizar as transformações de dados a pedido.
Enterprise Data Warehouse
a enterprise data warehouse is intended as a unified, centralized warehouse containing all transactional information in the organization, both current and historical. Um armazém de dados de empresas deve incorporar dados de todas as áreas temáticas relacionadas com o negócio, tais como marketing, Vendas, Finanças e recursos humanos.
estas são as ideias centrais que compõem os armazéns de dados tradicionais. Agora, vamos ver o que os armazéns de dados em nuvem adicionaram em cima deles.Os conceitos de armazenamento de dados em nuvem
os conceitos de armazenamento de dados em nuvem
os armazéns de dados em nuvem são novos e estão em constante mudança. Para melhor entender seus conceitos fundamentais, é melhor aprender sobre as soluções líderes de armazenamento de dados em nuvem.
três principais soluções de armazenamento de dados em nuvem são Amazon Redshift, Google BigQuery e Panoply. A seguir, explicamos conceitos fundamentais de cada um destes serviços para fornecer-lhe uma compreensão geral de como os modernos armazéns de dados funcionam.Os seguintes conceitos são explicitamente usados no Amazon Redshift cloud data warehouse, mas podem se aplicar a soluções de armazenamento de dados adicionais no futuro com base na infraestrutura Amazon.
Clusters
Amazon Redshift baseia sua arquitetura em clusters. Um cluster é simplesmente um grupo de recursos computacionais compartilhados, chamados nós.
nós
nós são recursos de computação que têm CPU, RAM e espaço em disco rígido. Um conjunto contendo dois ou mais nós é composto por um nó líder e nós computados.
os nós Leader comunicam com os programas clientes e compila o código para executar consultas, atribuindo-o para computar nós. Calcular Nós executar as consultas e devolver os resultados para o nó líder. Um nó de cálculo só executa consultas que as tabelas de referência armazenadas nesse nó.
partições/fatias
partições amazónicas cada nó computado em fatias. Uma fatia recebe uma alocação de memória e espaço em disco no nó. Várias fatias operam em paralelo para acelerar o tempo de execução da consulta.
armazenamento colunar
Redshift usa armazenamento colunar, permitindo um melhor desempenho da consulta analítica. Em vez de armazenar registros em linhas, ele armazena valores de uma única coluna para várias linhas. Os diagramas a seguir tornar isto mais claro:
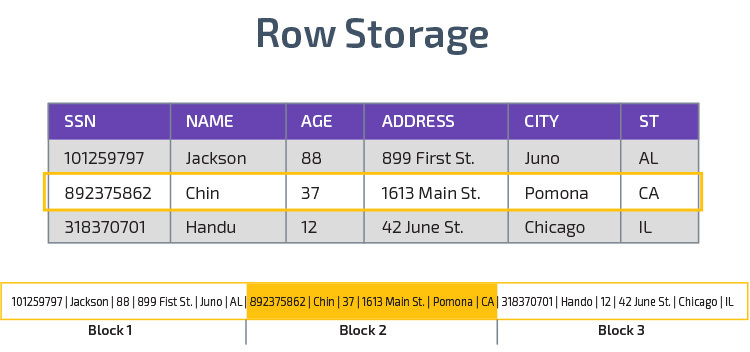
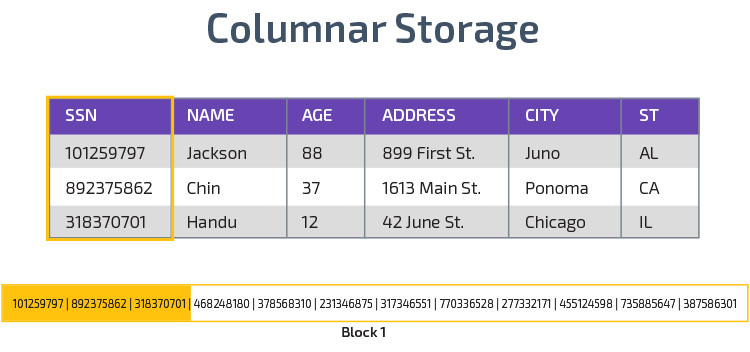
armazenamento Colunar torna possível ler os dados mais rapidamente, o que é crucial para consultas analíticas que abrangem várias colunas em um conjunto de dados. O armazenamento colunar também ocupa menos espaço em disco, porque cada bloco contém o mesmo tipo de dados, o que significa que pode ser comprimido em um formato específico.
Compressão
Compressão reduz o tamanho dos dados armazenados. No Redshift, devido à forma como os dados são armazenados, a compressão ocorre ao nível da coluna. O Redshift permite-lhe comprimir manualmente a informação ao criar uma tabela ou usar automaticamente o comando COPY.
data Loading
you can use Redshift’s COPY command to load large amounts of data into the data warehouse. O comando COPY alavanca a arquitetura MPP do Redshift para ler e carregar dados em paralelo de arquivos na Amazon S3, a partir de uma tabela DynamoDB, ou saída de texto de uma ou mais hosts remotas.
também é possível transmitir dados para o Redshift, usando o serviço de Firehose da Amazon Kinesis.
Cloud Database Warehouse-Google BigQuery
os seguintes conceitos são explicitamente utilizados no Google BigQuery cloud data warehouse, mas podem aplicar-se a soluções adicionais no futuro com base na infra-estrutura do Google.
serviço sem serventia
BigQuery usa arquitetura sem serventia. Com a BigQuery, as empresas não precisam gerenciar unidades de Servidores físicos para executar seus armazéns de dados. Em vez disso, BigQuery gerencia dinamicamente a alocação de seus recursos de computação. As empresas que utilizam o serviço pagam simplesmente o armazenamento de dados por gigabyte e as consultas por terabyte.
Colossus File System
BigQuery uses the latest version of Google’s distributed file system, code-named Colossus. O sistema de arquivos Colossus usa algoritmos de armazenamento colunar e compressão para armazenar dados para fins analíticos.
Dremel Execution Engine
The Dremel execution engine uses a columnar layout to query vast stores of data quickly. O motor de execução de Dremel pode executar consultas ad-hoc em bilhões de linhas em segundos, porque ele usa processamento massivamente paralelo na forma de uma arquitetura de árvore.
a arquitectura da árvore distribui consultas entre vários servidores intermédios a partir de um servidor root. Os servidores intermediários empurram a consulta para os servidores leaf (contendo dados armazenados), que digitalizam os dados em paralelo. No caminho de volta para a árvore, cada servidor leaf envia resultados de consulta, e os servidores intermediários realizam uma agregação paralela de resultados parciais.
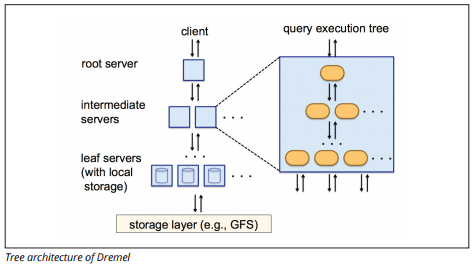
fonte de imagem
Dremel permite que as organizações executem consultas em até dezenas de milhares de servidores simultaneamente. De acordo com o Google, a Dremel pode digitalizar 35 mil milhões de linhas sem um índice em dezenas de segundos.
partilha de dados
a arquitectura serverless do Google BigQuery permite às empresas partilhar facilmente dados com outras organizações sem exigir que essas organizações invistam no seu próprio armazenamento.
organizações que querem consultar dados compartilhados podem fazê-lo, e eles só vão pagar pelas consultas. Não há necessidade de criar silos de dados caros compartilhados, externos à infraestrutura de dados da organização, e copiar os dados para esses silos.
Streaming and Batch Ingestion
It is possible to load data to BigQuery from Google Cloud Storage, including CSV, JSON( newline-delimited), and Avro files, as well as Google Cloud Datastore backups. Você também pode carregar dados diretamente de uma fonte de dados legível.
BigQuery também oferece uma API de Streaming para carregar dados para o sistema a uma velocidade de milhões de linhas por segundo sem realizar uma carga. Os dados estão disponíveis para análise quase imediatamente.
Cloud Data Warehouse Concepts – Panoply
Panoply is an all-in-one warehouse that combines ETL with a powerful data warehouse. É a maneira mais fácil de sincronizar, armazenar e acessar os dados de uma empresa, eliminando o desenvolvimento e codificação associados à transformação, integração e gerenciamento de grandes dados.
abaixo estão alguns dos principais conceitos no Armazém de dados Panoply relacionados à modelagem de dados e proteção de dados.
chaves primárias
chaves primárias asseguram que todas as linhas nas suas tabelas são únicas. Cada tabela tem uma ou mais chaves primárias que definem o que representa uma única linha única no banco de dados. Todas as APIs têm uma chave primária padrão para tabelas.
Incremental Keys
Panoply uses an incremental key to control attributes for incrementally loading data to the data warehouse from sources rather than reloading the entire dataset each time something changes. Este recurso é útil para conjuntos de dados maiores, que pode levar um longo tempo para ler principalmente dados inalterados. A chave incremental indica o último ponto de actualização das linhas nessa fonte de dados.Dados aninhados
dados aninhados
dados aninhados não são totalmente compatíveis com bi suites e consultas SQL padrão—Panoply lida com dados aninhados usando um modelo fortemente relacional que não permite valores aninhados. A panóplia transforma os dados aninhados desta forma:
- Subtables: por padrão, Panoply transforma dados aninhados em um conjunto de muitas-para-muitas ou tabelas de relacionamento um-para-muitas, que são tabelas relacionais planas.
- achatamento: com este modo activo, a panóplia achata a estrutura aninhada no registo que a contém.
tabelas de História
às vezes você precisa analisar os dados, mantendo o controle da mudança de dados ao longo do tempo para ver exatamente como os dados mudam (por exemplo, endereços das pessoas).
para realizar tais análises, Panoply usa tabelas de história, que são tabelas de séries cronológicas que contêm instantâneos históricos de cada linha na tabela estática original. Você pode então realizar consultas simples da tabela original ou revisões à tabela, rebobinando para qualquer ponto no tempo.
transformações
Panoply usa ELT, que é uma variação no processo original de integração de dados ETL. Uma vez que você tenha injetado dados da fonte em seu armazém de dados, Panoply imediatamente transforma-o. Este processo lhe dá a análise de dados em tempo real e o desempenho ideal quando comparado com o processo ETL padrão.
String Formats
Panoply parses string formats and handles them as if they were nested objects in the original data. Formatos de texto suportados são CSV, TSV, JSON, JSON-Line, formato de objetos Ruby, strings de pesquisa URL, e logs de distribuição web.
Data Protection
Panoply is built on top of AWS, so it has the latest security patches and encryption capabilities provided by AWS, including hardware-accelerated RSA encryption and Amazon Redshift’s specific set of security features.
a protecção Extra vem da encriptação colunar, que lhe permite usar as suas chaves privadas que não são guardadas nos servidores da Panoply.
Controle de acesso
Panoply usa verificação em duas etapas para impedir o acesso não autorizado, e um sistema de permissão permite restringir o acesso a tabelas, vistas ou colunas específicas. A detecção de anomalias identifica consultas provenientes de novos computadores ou de um país diferente, permitindo-lhe bloquear essas consultas a menos que elas recebam aprovação manual.
IP Whitelisting
recomendamos que bloqueie as ligações a partir de fontes não reconhecidas, utilizando um firewall ou um grupo de segurança AWS e clarifique a gama de endereços IP que as fontes de dados da Panoply usam sempre ao aceder à sua base de dados.
Conclusion: Traditional vs. Data Warehouse Concepts in Brief
To wrap up, we’ll summarize the concepts introduced in this document.
conceitos tradicionais de Data Warehouse
- Factos e medidas: uma medida é uma propriedade sobre a qual podem ser feitos cálculos. Nós nos referimos a uma coleção de medidas como fatos, mas às vezes os termos são usados indistintamente.
- normalização: o processo de redução da quantidade de dados duplicados, o que leva a um armazenamento de dados mais eficiente de memória que é mais lento de consulta.
- dimensão: usada para categorizar e contextualizar factos e medidas, permitindo a análise e a comunicação dessas medidas.
- modelo Conceptual de dados: define as entidades críticas de dados de alto nível e as relações entre elas.
- modelo de dados lógicos: Descreve as relações de dados, entidades e atributos em Inglês claro sem se preocupar sobre como implementá-lo em código.
- modelo de dados físicos: uma representação de como implementar o projeto de dados em um sistema de gerenciamento de banco de dados específico.
- star schema: toma uma tabela de factos e divide a sua informação em tabelas dimensionais desnormalizadas.
- esquema de Flocos De Neve: divide a tabela de factos em tabelas dimensionais normalizadas. Normalizar reduz os problemas de redundância de dados e melhora a integridade dos dados, mas as consultas são mais complexas.
- OLTP: Os sistemas de processamento de transações on-line facilitam processamento rápido e orientado a transações com consultas simples.
- OLAP: o processamento analítico Online permite que você execute consultas complexas de leitura e, assim, realizar uma análise detalhada dos dados históricos transacionais.Data mart: um arquivo de dados com foco em um determinado assunto ou departamento dentro de uma organização.
- Inmon approach: Bill Inmon’s data warehouse approach defines the data warehouse as the centralized data repository for the entire enterprise. Os marts de dados podem ser construídos a partir do data warehouse para atender às necessidades analíticas de diferentes departamentos.Abordagem Kimball: Ralph Kimball descreve um armazém de dados como a fusão de marts de dados críticos para missões, que são criados pela primeira vez para atender às necessidades analíticas de diferentes departamentos.
- ETL: integra os dados no armazém de dados extraindo – os de várias fontes transacionais, transformando os dados para otimizá-los para análise e, finalmente, carregando-os no armazém de dados.
- ELT: Uma variação na ETL que extrai dados brutos das fontes de dados de uma organização e a carrega para o armazém de dados. Quando necessário, é transformado para fins analíticos.
- Enterprise Data Warehouse: a EDW consolida dados de todas as áreas temáticas relacionadas com a empresa.
Cloud Data Warehouse Concepts-Amazon Redshift as Example
- Cluster: A group of shared computing resources based in the cloud.
- Node: um recurso informático contido num cluster. Cada nó tem seu próprio CPU, RAM e espaço em disco rígido.
- armazenamento colunar: Isto armazena os valores de uma tabela em colunas ao invés de linhas, que otimiza os dados para consultas agregadas.Compressão: técnicas para reduzir o tamanho dos dados armazenados.
- data loading: Getting data from sources into the cloud-based data warehouse. No Redshift, você pode usar o comando COPY ou um serviço de transmissão de dados.
Cloud Data Warehouse Concepts-BigQuery as Example
- Serverless service: The cloud provider dynamically manages the allocation of machine resources based on the amount the user consumes. O provedor de nuvem esconde as decisões de gerenciamento de servidores e planejamento de capacidade dos usuários do serviço.
- Colossus file system: um sistema de arquivos distribuído que usa algoritmos de armazenamento colunar e compressão de dados para otimizar dados para análise.
- Dremel execution engine: a query engine that uses massively parallel processing and columnar storage to execute queries quickly.
- partilha de dados: num serviço sem servidor, é prático consultar os dados partilhados de outra organização sem investir no armazenamento de dados—você simplesmente paga as consultas.
- Streaming data: inserir dados em tempo real no armazém de dados sem efectuar uma carga. Você pode transmitir dados em pedidos de lote, que são várias chamadas de API combinadas em um pedido HTTP.
Tradicional versus Nuvem Análise de Custo-Benefício
| Custo/Benefício | Tradicional | Nuvem |
| Custo | Grande custo inicial para adquirir e instalar um no-prem sistema. você precisa de hardware, salas de servidores e pessoal especializado (que você paga em uma base contínua). se não tiver a certeza de quanto espaço de armazenamento necessita, existe o risco de elevados custos irrecuperáveis que são difíceis de recuperar. |
não é necessário comprar hardware, salas de servidores ou contratar especialistas. nenhum risco de custos irrecuperáveis-comprar mais armazenamento no futuro é fácil. Plus, the cost of storage and computing power are decreating over time. |
| escalabilidade | uma vez que você max as suas actuais salas de servidor ou capacidade de hardware, você pode ter que comprar novo hardware e construir/comprar mais Lugares para alojá-lo. mais, você precisa comprar armazenamento suficiente para lidar com os tempos de pico; assim, na maioria das vezes, a maior parte do seu armazenamento não é usado. |
pode facilmente comprar mais armazenamento à medida que precisar. muitas vezes só tem que pagar pelo que você usa, então há pouco ou nenhum risco de pagamento excessivo. |
| integrações | como a computação em nuvem é a norma, a maioria das integrações que você quer fazer será para serviços em nuvem.Ligar o seu armazém de dados personalizado a eles pode ser um desafio.Como os depósitos de dados em nuvem já estão na nuvem, a ligação a uma série de outros serviços em nuvem é simples. | |
| segurança | você tem o controle total de seu armazém de dados.Comparando a quantidade de dados que você Casa com a Amazon ou Google, você é um alvo menor para ladrões. Então, é mais provável que te deixem em paz.Os provedores de armazenamento de dados em nuvem têm equipes cheias de engenheiros de segurança altamente qualificados, cujo único objetivo é tornar seu produto tão seguro quanto possível. as empresas mais proeminentes do mundo gerem-NAS e, portanto, implementam práticas de segurança de classe mundial. |
|
| Governança | você sabe exatamente onde seus dados estão e pode acessá-los localmente. menor risco de dados altamente sensíveis inadvertidamente infringindo a lei, por exemplo, viajando pelo mundo em um servidor de nuvem. |
os principais fornecedores de armazenamento de dados em nuvem garantem que eles estão em conformidade com as leis de governança e segurança, como o GDPR. Além disso, eles ajudam o seu negócio a garantir que você é complacente.Tem havido problemas em saber exactamente onde os seus dados estão e onde se movem. Estes problemas estão a ser activamente abordados e resolvidos.Note que armazenar grandes quantidades de dados altamente sensíveis na nuvem pode ser contra leis específicas. Este é um caso em que a computação em nuvem pode ser inapropriada para o seu negócio. |
| fiabilidade | se o seu armazém de dados on-prem falhar, é da sua responsabilidade corrigi-lo.Sua equipe de TI tem acesso ao hardware físico e pode acessar todas as camadas de software para solucionar problemas. Este acesso rápido pode tornar a resolução de problemas muito mais rápida. no entanto, não há garantia de que o seu armazém terá uma quantidade particular de tempo de funcionamento a cada ano.Os provedores de armazenamento de dados em nuvem garantem sua confiabilidade e tempo de funcionamento em seus SLAs.Eles operam em sistemas massivamente distribuídos em todo o mundo, então se houver uma falha em um deles, é altamente improvável que o afete. |
|
| Controle | seu armazém de dados é feito sob medida para atender às suas necessidades. Em teoria, ele faz o que você quer que ele faça, quando você quer, de uma forma que você entende.Não tem controlo total sobre o seu armazém de dados.No entanto, na maioria das vezes, o controlo que tem é mais do que suficiente. | |
| Velocidade | Se você é uma pequena empresa em uma localização geográfica com uma pequena quantidade de dados, o seu processamento de dados será mais rápida.No entanto, estamos a falar de milisegundos vs. segundos para alguns processos terminarem.É pouco provável que uma grande empresa que opera em vários países veja ganhos de velocidade significativos com um sistema on-prem.Os provedores de nuvem investiram e criaram sistemas que implementam processamento massivamente paralelo (MPP), arquitetura customizada e motores de execução, e algoritmos inteligentes de processamento de dados.Os armazéns de dados em nuvem são o resultado de anos de pesquisa e testes para criar recursos otimizados para velocidade e desempenho. pode ser ligeiramente mais lento que o on-prem em alguns casos, mas estes atrasos são muitas vezes negligenciáveis para os seres humanos (segundos vs. milisegundos). |
Panoply é um lugar seguro para armazenar, sincronizar e acessar todos os seus dados de negócios. A Panoply pode ser configurada em minutos, requer zero manutenção em andamento, e fornece suporte on-line, incluindo acesso a arquitetos de dados experientes. Tente a Panoply livre por 14 dias.
Saiba Mais sobre Armazéns de Dados
- Data Warehouse Arquitectura Tradicional vs. Nuvem
- Banco de dados vs. Armazém de Dados
- Data Mart vs. Armazém de Dados