pesquisa comum: o projecto de código aberto que devolve o PageRank
Inscreva-se para as nossas recaps diárias da paisagem de marketing de pesquisa em constante mudança.
nota: ao enviar este formulário, você concorda com os termos da terceira porta Media. Respeitamos a sua privacidade.

nos últimos anos, o Google reduziu lentamente a quantidade de dados disponíveis para os praticantes do SEO. Primeiro foi a palavra-chave data, depois a pontuação PageRank. Agora é um volume de pesquisa específico do AdWords (a menos que você esteja gastando algum moola). Você pode ler mais sobre isso no excelente artigo de Russ Jones que detalha o impacto da pesquisa de sua empresa e insights sobre dados clickstream para desambiguação de volume.
um item em que nos envolvemos realmente recentemente são dados comuns de rastejar. Há várias equipes em nossa indústria que têm usado esses dados por algum tempo, então eu me senti um pouco atrasado para o jogo. Common Crawl data é um projeto de código aberto que raspa toda a internet em intervalos regulares. Felizmente, Amazon, sendo a grande empresa que é, contribuiu para armazenar os dados para torná-lo disponível para muitos sem os altos custos de armazenamento.
além de dados comuns de rastreamento, há uma sem fins lucrativos chamada busca comum cuja missão é criar uma fonte aberta alternativa e motor de busca transparente-o oposto, em muitos aspectos, do Google. Isso despertou meu interesse porque significa que todos nós podemos jogar, ajustar e mangletar os sinais para aprender como os motores de busca funcionam sem o enorme investimento de tempo de começar do zero.
dados comuns de pesquisa
actualmente, a Pesquisa comum utiliza as seguintes fontes de dados para calcular os seus rankings de pesquisa (isto é retirado directamente do seu sítio Web):
- rastejamento comum: o maior repositório aberto de dados de rastreamento web. Esta é atualmente a nossa fonte única de dados de página raw.
- Wikidata: A free, linked database that acts as central storage for the structured data of many Wikimedia projects like Wikipedia, Wikivoyage and Wikisource.
- UT1 Lista negra: mantida por Fabrice Prigent da Université Toulouse 1 Capitole, esta lista negra categoriza domínios e URLs em várias categorias, incluindo “adulto” e “phishing”.”
- DMOZ: também conhecido como o projeto diretório aberto, é o mais antigo e maior diretório web ainda vivo. Embora os seus dados não sejam tão fiáveis como eram no passado, ainda o usamos como fonte de sinais e metadados.
- Web Data Commons Hyperlink Graphs: Graphs of all hyperlinks from a 2012 Common Crawl archive. Estamos atualmente usando seu arquivo de centralidade harmônica como um sinal de classificação temporária em domínios. Planeamos realizar a nossa própria análise do Gráfico web num futuro próximo.
- Alexa Top 1m sites: Alexa classifica sites baseados em uma medida combinada de visualizações de páginas e usuários únicos do site. É conhecido por ser demograficamente tendenciosa. Estamos a usá-lo como um sinal temporário de classificação em domínios.
Common Search ranking
In addition to these data sources, in investigating the code, it also uses URL length, path length and domain PageRank as ranking signals in its algorithm. Vejam só, desde julho, a Pesquisa comum tem os seus próprios dados sobre o PageRank do nível do hospedeiro, e todos nós o perdemos.
eu vou chegar ao PageRank (PR) em um momento, mas é interessante rever o código de rastejar comum, especialmente o ranker.py porção localizada aqui, porque você realmente pode entrar no Banco do condutor com ajustes nos pesos dos sinais que ele usa para classificar as páginas:
signal_weights = {"url_total_length": 0.01,"url_path_length": 0.01,"url_subdomain": 0.1,"alexa_top1m": 5,"wikidata_url": 3,"dmoz_domain": 1,"dmoz_url": 1,"webdatacommons_hc": 1,"commonsearch_host_pagerank": 1}
de particular nota, também, é que a Pesquisa comum usa BM25 como medida de similaridade da palavra-chave para documentar corpo e meta dados. BM25 é uma medida melhor do que TF-IDF porque leva em conta o comprimento do documento, o que significa que um documento de 200 palavras que tem a sua palavra-chave cinco vezes é provavelmente mais relevante do que um documento de 1.500 palavras que tem o mesmo número de vezes.
também vale a pena dizer que o número de Sinais aqui é muito rudimentar e obviamente falta muitos dos refinamentos (e dados) que o Google integrou em seu algoritmo de classificação de pesquisa. Uma das coisas-chave em que estamos trabalhando é usar os dados disponíveis em comum Crawl e a infra-estrutura de busca comum para fazer pesquisa vetorial Tópico para conteúdo que é relevante com base na semântica, não apenas correspondência de palavras-chave.
no PageRank
na página aqui, você pode encontrar links para o PageRank de nível anfitrião para o Crawl comum de junho de 2016. Estou a usar a que tem o direito pagerank-top1m.txt.gz (top 1 milhão) porque o outro arquivo é 3GB e mais de 112 milhões de domínios. Mesmo em R, Eu Não tenho máquina suficiente para carregá-lo sem cair fora.
após o download, você precisará trazer o arquivo para o seu diretório de trabalho em R. os dados do PageRank da Pesquisa comum não estão normalizados e também não está no formato limpo 0-10 que estamos todos acostumados a vê-lo. A pesquisa comum usa ” max (0, min (1, float(rank) / 244660.58)) ” – basicamente, o ranking de um domínio dividido pelo rank do Facebook — como o método de traduzir os dados em uma distribuição entre 0 e 1. Mas isso deixa algumas lacunas definidas, na medida em que isso deixaria o PageRank de Linkedin como um 1.4 quando escalado por 10.

O código a seguir irá carregar o conjunto de dados e acrescentar um PR coluna com uma melhor aproximação PR:
#Grab the datadf <- read.csv("pagerank-top1m.txt", header = F, sep = " ")#Log NormalizelogNorm <- function(x){ #Normalize x <- (x-min(x))/(max(x)-min(x)) 10 / (1 - (log10(x)*.25))}#Append a Column named PR to the datasetdf$pr <- (round(logNorm(df$V2),digits = 0))
tivemos que brincar um pouco com os números para obtê-lo em algum lugar perto (para várias amostras de domínios que eu me lembrei de relações públicas) para o Google idade PR. Abaixo estão alguns exemplos de resultados do PageRank:
- en.wikipedia.org (8)
- searchengineland.com (6)
- consultwebs.com (5)
- youtube.com (9)
- moz.com (6)
Aqui é um terreno de 100.000 amostras aleatórias. A pontuação PageRank calculada é ao longo do eixo Y, e a pontuação de busca comum original é ao longo do eixo X.
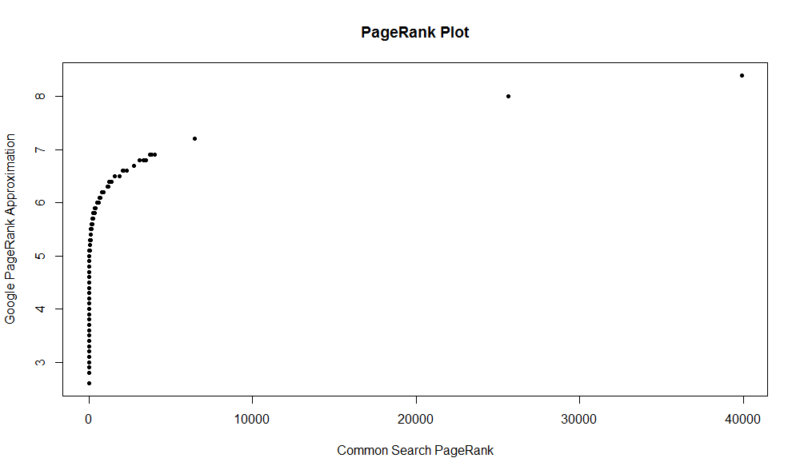
para obter os seus próprios resultados, pode executar o seguinte comando em R (basta substituir o seu próprio domínio):
df

tenha em mente que este conjunto de dados só tem o top um milhão de domínios por PageRank, então de 112 milhões de domínios que Pesquisa comum indexada, há uma boa chance de seu site pode não estar lá se ele não tem um perfil de link muito bom. Além disso, esta métrica não inclui nenhuma indicação da nocividade dos links, apenas uma aproximação da popularidade do seu site com relação aos links.
a busca comum é uma grande ferramenta e uma grande fundação. Estou ansioso por me envolver mais com a comunidade de lá e espero aprender a entender melhor as porcas e parafusos por trás dos motores de busca, trabalhando realmente em um. Com R e um pequeno código, você pode ter uma maneira rápida de verificar PR para um milhão de domínios em questão de segundos. Espero que tenham gostado!
Inscreva-se para as nossas recaps diárias da paisagem de marketing de pesquisa em constante mudança.
nota: ao enviar este formulário, você concorda com os termos da terceira porta Media. Respeitamos a sua privacidade.
Sobre O Autor

JR Oakes é o diretor sênior de técnicas de SEO pesquisa na Locomotiva. Ele foi anteriormente diretor da SEO Técnica da Agência Adapt Partners. Ele trabalha com clientes em uma ampla gama de frentes, incluindo questões técnicas, desempenho, CTR, capacidade de rastreamento, conteúdo e análise de dados. A JR adora testar, codificar e prototipar soluções para problemas difíceis de marketing de pesquisa. Quando ele não está trabalhando, ele gosta de ler sobre tecnologias emergentes, tocar baixo, assistir basquete universitário, cozinhar e passar tempo com seus amigos e família. Ele também é um dos co-organizadores do Raleigh SEO Meetup, Raleigh SEO Conference, e RTP SEO Meetup.