Scalable, Distributed Secundário de Indexação em Scylla

O modelo de dados em Scylla e Apache Cassandra partições de dados entre os nós do cluster usando uma chave de partição, que é definido pelo esquema de banco de dados. A utilização de uma chave de partição oferece uma forma eficiente de procurar as linhas usando a chave de partição, porque você pode encontrar o nó que possui a linha, através de hashing a chave de partição. Infelizmente, isso também significa que encontrar uma linha usando uma chave de não-partição requer uma varredura de tabela completa que é ineficiente. Índices secundários são um mecanismo no Apache Cassandra que permite pesquisas eficientes em chaves não-partições, criando um índice.
neste post você vai aprender:
- Como o Apache Cassandra implementa Índices Secundários locais de indexação
- Por que decidiu tomar uma estratégia de implementação para Scylla usando global de indexação
- Como global de indexação afeta a forma como você deve usar Secundário Indexação
- Como criar seu próprio Índices Secundários e usá-los em seu aplicativo CQL consultas
Fundo
O tamanho de um índice é proporcional ao tamanho dos dados indexados. Como os dados em Scylla e Apache Cassandra são distribuídos para vários nós, é impraticável armazenar o índice inteiro em um único nó. O Apache Cassandra implementa índices secundários como índices locais, o que significa que o índice é armazenado no mesmo nó que os dados que estão sendo indexados a partir desse nó. O benefício de um índice local é que as escritas são muito rápidas, mas o lado negativo é que as leituras têm que potencialmente consultar cada nó para encontrar o índice para realizar uma pesquisa, o que torna os índices locais inescaláveis para grandes aglomerados. Além dos índices secundários nativos, o Apache Cassandra também tem outro esquema de indexação local, o SSTable Attached Secondary Index (SASI), que suporta consultas complexas e pesquisa. No entanto, do ponto de vista da escalabilidade, tem exatamente as mesmas características que os índices secundários originais.
visualizações materializadas em Scylla e Apache Cassandra são um mecanismo para desnormalizar automaticamente os dados de uma tabela de base para uma tabela de visualização usando uma chave de partição diferente. Isso resolve a questão de escalabilidade dos índices locais, mas vem a um custo de armazenamento, porque você precisa duplicar a tabela inteira no pior caso. Os pontos de vista materializados não substituem, portanto, os índices secundários para todos os casos de Utilização. No entanto, as visões materializadas fornecem a infra-estrutura necessária para implementar índices secundários usando indexação global, que é a abordagem de implementação adotada para Scylla.
indexação Global
Scylla tem uma abordagem diferente do Apache Cassandra e implementa índices secundários usando indexação global. Com indexação global, uma visão materializada é criada para cada índice. A área materializada tem a coluna indexada como chave de partição e chave primária (chave de partição e Chaves de agrupamento) da linha indexada como chaves de agrupamento. Scylla quebra as consultas indexadas em duas partes: (1) uma consulta na tabela índice para obter chaves de partição para a tabela indexada e (2) uma consulta para a tabela indexada usando as chaves de partição recuperadas. O benefício desta abordagem é que podemos usar o valor da coluna indexada para encontrar a linha de tabela de índice correspondente no cluster de modo que as leituras são escaláveis. A desvantagem da abordagem é que as escritas são mais lentas do que com a indexação local por causa de todas as despesas gerais de manter a vista do Índice atualizada.
pesquisar numa coluna indexada parece ser a seguinte. Vamos supor uma mesa que se pareça com isto.:
e uma consulta na coluna email, que não é uma chave de partição, mas tem um índice:
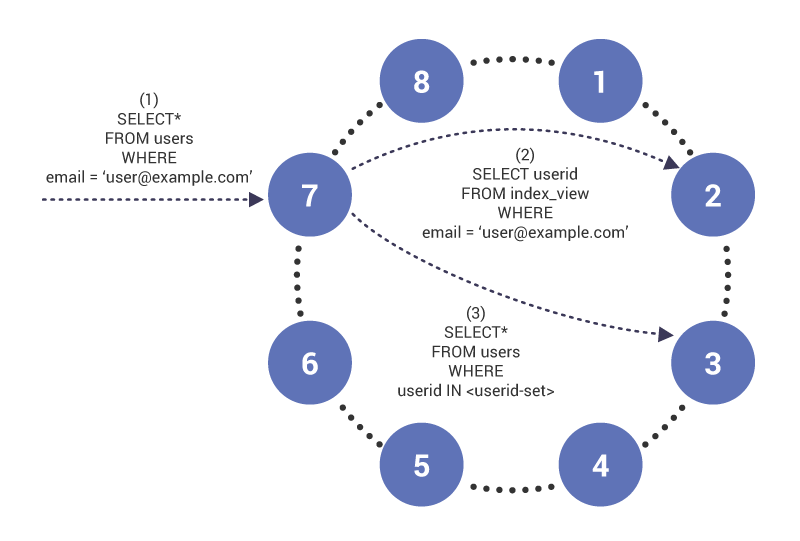
na Fase (1), a consulta chega ao nó 7, que atua como coordenador da consulta. O nó percebe que estamos pesquisando em uma coluna indexada e, portanto, na Fase (2), emite uma tabela de leitura para índice no nó 2, que tem a linha de tabela de índice para “”. A consulta retorna um conjunto de IDs do usuário que são usados na Fase (3) para recuperar o conteúdo da tabela indexada.
exemplo
primeiro precisamos criar um esquema. Neste exemplo, temos uma tabela que representa a informação do usuário com userid como a chave de partição e nome, e-mail, e país como colunas regulares:
então populamos a tabela com alguns dados de teste gerados com Mockaroo:
os índices secundários são projetados para permitir o questionamento eficiente de colunas chave não-divisórias. Enquanto o Apache Cassandra também suporta consultas em colunas chave de não-partição usando ALLOW FILTERING, isso é muito ineficiente (requerendo a digitalização de toda a tabela) e atualmente não suportado por Scylla (veja a edição #2200 para detalhes).
pode indexar colunas de tabelas usando a instrução CREATE INDEX. Por exemplo, para criar índices de E-mail e colunas de país, execute as seguintes declarações CQL:
Scylla cria automaticamente uma vista materializada que tem a coluna indexada como chave de partição e chave primária de Tabela-alvo (chave de partição e Chaves de agrupamento) como chaves de agrupamento.
por exemplo, a vista materializada para o índice na coluna email parece ser a seguinte:
se a vista acima seria criada como uma tabela regular, seria efetivamente a seguinte::
a coluna email é usada como chave de partição para a tabela de índice e userid é incluída como chave de agrupamento, o que nos permite encontrar eficientemente chaves de partição para a Tabela-alvo usando apenas email.
Você pode usar o DESCRIBE comando para ver todo o esquema para a ks.users tabela, incluindo os criados índices e pontos de vista:
Agora, com o Índice Secundário no lugar, você pode consultar colunas indexadas, como se fossem chaves de partição:
Estamos a fazer com o exemplo!
quando utilizar índices secundários?
os índices secundários são (na sua maioria) transparentes para a aplicação. As consultas têm acesso a todas as colunas da tabela e você pode adicionar e remover índices sem alterar a aplicação. Os índices secundários também podem ter menos despesas de armazenamento do que as vistas materializadas porque os índices secundários só precisam duplicar a coluna indexada e chave primária, não as colunas pesquisadas como com uma vista materializada. Além disso, pela mesma razão, as atualizações podem ser mais eficientes com índices secundários porque apenas as mudanças na chave primária e coluna indexada causam uma atualização na vista de índice. No caso de uma vista materializada, uma atualização para qualquer uma das colunas que aparecem na janela requer que a vista de suporte seja atualizada.
como sempre, a decisão de usar índices secundários ou visões materializadas depende realmente dos Requisitos de sua aplicação. Se você precisa de desempenho máximo e é provável que você consulta um conjunto específico de colunas, você deve usar visualizações materializadas. No entanto, se a aplicação precisa consultar diferentes conjuntos de colunas, os índices secundários são uma melhor escolha porque eles podem ser adicionados e removidos com menos despesas de armazenamento dependendo das necessidades da aplicação.
deseja saber mais sobre os índices secundários? Veja a minha apresentação da Cimeira de Scylla 2017 sobre SlideShare. Se você quiser experimentar este recurso, é esperado para estar no próximo lançamento Scylla 2.2.