Tempo de Sincronização em Sistemas Distribuídos
facebook.com ou google.com, talvez não menos de uma vez você se perguntou como esses sites podem lidar com milhões ou mesmo dezenas de milhões de pedidos por segundo. Haverá algum servidor comercial único que possa suportar esta enorme quantidade de pedidos, da forma que cada pedido pode ser servido oportunamente para os usuários finais?Ao mergulhar mais fundo nesta questão, chegamos ao conceito de sistemas distribuídos, uma coleção de computadores independentes (ou nós) que aparecem para seus usuários como um único sistema coerente. Esta noção de coerência para os usuários é clara, pois eles acreditam que estão lidando com uma única máquina gigantesca que toma a forma de múltiplos processos correndo em paralelo para lidar com lotes de pedidos de uma vez. No entanto, para as pessoas que compreendem a infra-estrutura do sistema, as coisas não se tornam tão fáceis como tal.
para milhares de máquinas independentes rodando simultaneamente que podem abranger vários fusos horários e continentes, alguns tipos de sincronização ou coordenação devem ser dadas para que estas máquinas colaborem eficientemente umas com as outras (para que possam aparecer como uma). Neste blog, vamos discutir a sincronização do tempo e como ele alcança consistência entre as máquinas na ordenação e causalidade dos eventos.
o conteúdo deste blog será organizado da seguinte forma:
- Sincronização de Relojoaria
- relógios lógicos
- Take away
- o que se segue?
Relógios físicos
num sistema centralizado, o tempo é inequívoco. Quase todos os computadores têm um “relógio em tempo real” para manter o controle do tempo, geralmente em sincronia com um cristal de quartzo usinado com precisão. Baseado na bem definida oscilação de frequência deste quartzo, o sistema operacional de um computador pode monitorar com precisão o tempo interno. Mesmo quando o computador é desligado ou sai de carga, o quartzo continua a tick devido à bateria CMOS, uma pequena potência integrada na placa-mãe. Quando o computador se conecta à rede (Internet), o SO então contacta um servidor de temporizador, que é equipado com um receptor UTC ou um relógio preciso, para restaurar com precisão o temporizador local usando o protocolo de tempo de rede, também chamado NTP.
embora esta frequência do quartzo cristal seja razoavelmente estável, é impossível garantir que todos os cristais de diferentes computadores funcionem exatamente na mesma frequência. Imagine um sistema com computadores n, cujos cristais rodam a taxas ligeiramente diferentes, fazendo com que os relógios gradualmente saiam da Sincronia e dêem valores diferentes quando são lidos. A diferença nos valores de tempo causados por isso é chamado de deslocamento de relógio.Nestas circunstâncias, as coisas complicaram-se por terem múltiplas máquinas separadas espacialmente. Se o uso de vários relógios físicos internos é desejável, como os sincronizamos com relógios do mundo real? Como os sincronizamos uns com os outros?
Network Time Protocol
A common approach for pair-wise synchronization between computers is through the use of the client-server model I. e let clients contact a time server. Vamos considerar o seguinte exemplo com 2 máquinas A e B:
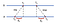
Em Primeiro Lugar, A envia um pedido de tempo limitado com o valor T₀ para B. B, as the message arrives, records the time of receipt T₁ from its own local clock and responses with a message timestampted with T₂, piggybacking the previously recorded value T₁. Por último, A, ao receber a resposta de B, regista a hora de chegada T₃. A conta para o tempo de atraso na entrega de mensagens, calculamos Δ₁ = T₁-T₀, Δ₂ = T₃-T₂. Agora, estima-se que o deslocamento de Um em relação a B é:

Based on θ, we can either slow down the clock of a or fix it so that the two machines can be synchronized with each other.
uma vez que NTP é aplicável em par, o relógio de B pode ser ajustado para o de A também. No entanto, é insensato ajustar o relógio em B se se sabe que é mais preciso. Para resolver este problema, NTP divide os servidores em estratos, isto é, servidores de ranking de modo que os relógios de servidores menos precisos com fileiras menores serão sincronizados com os dos mais precisos com fileiras mais altas.O algoritmo de Berkeley
em contraste com os clientes que periodicamente contactam um servidor de tempo para sincronizar o tempo com precisão, Gusella e Zatti, em 1989 Berkeley Unix paper , propôs o modelo cliente-servidor em que o servidor de tempo (daemon) pesquisa cada máquina periodicamente para perguntar Que horas ele está lá. Baseado nas respostas, ele calcula o tempo de ida e volta das mensagens, calcula o tempo atual com a ignorância de quaisquer valores anómalos no tempo, e “diz a todas as outras máquinas para avançar seus relógios para o novo tempo ou desacelerar seus relógios até que alguma redução especificada haw foi alcançada” .
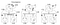
Relógios lógicos
vamos dar um passo atrás e reconsiderar a nossa base para datas sincronizadas. Na seção anterior, atribuímos valores concretos aos relógios de todas as máquinas participantes, a partir de agora eles podem chegar a acordo sobre uma linha do tempo global em que os eventos acontecem durante a execução do sistema. No entanto, o que realmente importa ao longo da linha do tempo é a ordem em que eventos relacionados ocorrem. Por exemplo, se, de alguma forma, nós só precisamos saber evento acontece antes do evento B, não importa se Tₐ = 2, Tᵦ = 6 ou Tₐ = 4, Tᵦ = 10, enquanto Tₐ < Tᵦ. Isto muda nossa atenção para o reino dos relógios lógicos, onde a sincronização é influenciada pela definição de Leslie Lamport de relação “acontece-antes”.
Relógios lógicos de Lamport
In his phenomenal 1978 paper Time, Clocks, and the Ordering of Events in a Distributed System, Lamport defined the “happens-before” relationship → ” as follows:
1. Se a e b são eventos no mesmo processo, e a vem antes de b, então a→B.
2. Se um é o envio de uma mensagem por um processo, e b é o recebimento da mesma mensagem por outro processo, então a→b.
3. Se a→b e b→c, então a→c.
Se eventos x, y ocorrem em diferentes processos que não trocam mensagens, nem x → y nem y → x é verdade, x e y são ditos ser concorrentes. Dada uma função C que atribui um valor de tempo C (a) para um evento em que todos os processos concordam, se a e b são eventos dentro do mesmo processo e a ocorre antes de b, C(a) < c(b)*. Da mesma forma, se a é o envio de uma mensagem por um processo e b é a recepção dessa mensagem por outro processo, C(a) < c(b) **.
agora vamos olhar para o algoritmo que Lamport propôs para atribuir tempos a eventos. Considere o seguinte exemplo, com um cluster de 3 processos A, B, C:

estes relógios de 3 processos funcionam no seu próprio tempo e estão inicialmente fora de sincronia. Cada relógio pode ser implementado com um simples contador de software, incrementado por um valor específico cada unidade de tempo T. No entanto, o valor pelo qual um relógio é incrementado difere por processo: 1 para Um, 5 para o B, e 2 para C.
No momento 1, A envia a mensagem m1 para B. No momento da chegada, o relógio do B lê 10 em seu relógio interno. Uma vez que a mensagem foi enviada foi adiada com o tempo 1, o valor 10 no processo B é certamente possível (podemos inferir que foram precisos 9 carrapatos para chegar a B a partir de a).
considere agora a mensagem m2. Deixa o B aos 15 e chega ao C às 8. Este valor de relógio em C é claramente impossível, uma vez que o tempo não pode ir para trás. A partir de ** e o fato de que o m2 sai aos 15, ele deve chegar aos 16 ou mais tarde. Portanto, temos que atualizar o valor de tempo atual em C para ser maior que 15 (adicionamos +1 ao tempo para simplicidade). Em outras palavras, quando uma mensagem chega e o relógio do receptor mostra um valor que precede o timestamp que indica a partida da mensagem, o receptor avança rapidamente seu relógio para ser uma unidade de tempo a mais do que o tempo de partida. Na Figura 6, vemos que o m2 agora corrige o valor do relógio de C a 16. Da mesma forma, m3 e m4 chegam a 30 e 36, respectivamente.Do exemplo acima, Maarten van Steen et al formula o algoritmo de Lamport da seguinte forma::
1. Antes de executar um evento (isto é, enviar uma mensagem através da rede,…), os incrementos Pᵢ Cᵢ: Cᵢ <- cᵢ + 1.
2. Quando o processo Pᵢ envia a mensagem m para o processo Pj, ele define o timestamp ts(m) de m igual a Cᵢ depois de ter executado o passo anterior.
3. Após a recepção de uma mensagem m, O process Pj ajusta o seu próprio contador local como Cj <- max{cj, ts(m)} após o qual executa o primeiro passo e entrega a mensagem à aplicação.
Vector Clocks
Lembre-se de costas para Lamport definição de “acontece antes” relação, se existem dois eventos a e b tais que a ocorre antes de b, então a é também posicionado em que a ordenação antes de b, que é C(a) < C(b). No entanto, isso não implica causalidade inversa, uma vez que não podemos deduzir que a vai Antes de b simplesmente comparando os valores de C(A) E C(b) (A prova é deixada como um exercício para o leitor).
a fim de obter mais informações sobre a ordenação de eventos com base em seu timestamp, Relógios vetoriais, uma versão mais avançada do relógio lógico de Lamport, é proposto. Para cada processo Pᵢ do sistema, o algoritmo mantém um vcᵢ vetorial com os seguintes atributos:
1. VCᵢ: relógio lógico local em Pᵢ, ou o número de eventos que ocorreram antes da data atual.
2. Se vc = = k, Pᵢ sabe que K eventos ocorreram em Pj.
o algoritmo dos relógios vectoriais passa a seguir:
1. Antes de executar um evento, Pᵢ registra um novo evento acontece em si mesmo, executando vc
2. Quando o Pᵢ envia uma mensagem m para o Pj, define timestamp ts(m) igual a VCᵢ depois de ter executado o passo anterior.
3. Quando a mensagem m é recebida, o processo Pj actualiza cada k do seu próprio relógio vectorial: VCj max max { VCj , ts(m)}. Em seguida, ele continua executando o primeiro passo e entrega a mensagem para a aplicação.
Por essas etapas, quando um processo Pj recebe uma mensagem de m de processo Pᵢ com carimbo de data / hora ts(m), ele sabe o número de eventos que ocorreram em Pᵢ casualmente precedida o envio de m. Além disso, a Pj também sabe sobre os eventos que têm sido conhecidos para Pᵢ sobre outros processos antes de enviar m. (Sim, isso é verdade, se você está relacionando este algoritmo para a Fofoca Protocolo 🙂).Com sorte, a explicação não o deixa a coçar a cabeça por muito tempo. Vamos mergulhar num exemplo para dominar o conceito:

com base na forma como avançamos os relógios internos para a sincronização, o evento a precede o evento B se para todo k, ts(a) ≤ ts(B), e existe pelo menos um índice k’ para o qual ts(a) < ts(B). Não é difícil ver que (2, 2, 0) precede (3, 2, 1), mas (1, 4, 0) e (3, 2, 0) podem entrar em conflito uns com os outros. Portanto, com relógios vetoriais, podemos detectar se há ou não uma dependência causal entre quaisquer dois eventos.
Tirar
Quando ele vem para o conceito de tempo no sistema distribuído, o principal objetivo é alcançar a ordem correta dos eventos. Eventos podem ser posicionados em ordem cronológica com relógios físicos ou em ordem lógica com relógios lógicos de Lamtport e Relógios vetoriais ao longo da linha do tempo de execução.O que se segue?
a seguir na série, vamos rever como a sincronização do tempo pode fornecer respostas surpreendentemente simples para alguns problemas clássicos em sistemas distribuídos: no máximo , uma mensagem , consistência de cache e exclusão mútua .Leslie Lamport: Time, Clocks, and the Ordering of Events in a Distributed System. 1978.
Barbara Liskov: Practical uses of synchronized clocks in distributed systems. 1993.Maarten van Steen, Andrew S. Tanenbaum: Distributed Systems. 2017.
Barbara Liskov, Liuba Shrira, John Wroclawski: Mensagens eficientes no máximo baseadas em relógios sincronizados. 1991.
Cary G. Gray, David R. Cheriton: Loces: An Efficient Fault-Tolerant Mechanism for Distributed File Cache Consistency. 1989.Ricardo Gusella, Stefano Zatti: the Accuracy of the Clock Synchronization Achieved by TEMPO in Berkeley Unix 4.3 BSD. 1989.