Skalierbare, verteilte Sekundärindexierung in Scylla

Das Datenmodell in Scylla und Apache Cassandra partitioniert Daten zwischen Clusterknoten mithilfe eines Partitionsschlüssels, der durch das Datenbankschema definiert ist. Die Verwendung eines Partitionsschlüssels bietet eine effiziente Möglichkeit, Zeilen mithilfe des Partitionsschlüssels nachzuschlagen, da Sie den Knoten finden können, dem die Zeile gehört, indem Sie den Partitionsschlüssel hashen. Leider bedeutet dies auch, dass das Finden einer Zeile mit einem Nicht-Partitionsschlüssel einen vollständigen Tabellenscan erfordert, was ineffizient ist. Sekundärindizes sind ein Mechanismus in Apache Cassandra, der eine effiziente Suche nach Nicht-Partitionsschlüsseln ermöglicht, indem ein Index erstellt wird.
In diesem Blogbeitrag erfahren Sie:
- Wie Apache Cassandra Sekundärindizes mithilfe der lokalen Indizierung implementiert
- Warum wir uns für eine andere Implementierungsstrategie für Scylla mithilfe der globalen Indizierung entschieden haben
- Wie sich die globale Indizierung auf die Verwendung der sekundären Indizierung auswirkt
- So erstellen Sie Ihre eigenen Sekundärindizes und verwenden sie in Ihrer Anwendung CQL-Abfragen
Hintergrund
Die Größe eines Index ist proportional zur Größe der indizierten Daten. Da Daten in Scylla und Apache Cassandra auf mehrere Knoten verteilt sind, ist es unpraktisch, den gesamten Index auf einem einzelnen Knoten zu speichern. Apache Cassandra implementiert sekundäre Indizes als lokale Indizes, was bedeutet, dass der Index auf demselben Knoten gespeichert wird wie die Daten, die von diesem Knoten indiziert werden. Der Vorteil eines lokalen Index besteht darin, dass Schreibvorgänge sehr schnell sind, der Nachteil jedoch darin, dass Lesevorgänge möglicherweise jeden Knoten abfragen müssen, um den Index zu finden, für den eine Suche durchgeführt werden soll. Zusätzlich zu den nativen Sekundärindizes verfügt Apache Cassandra über ein weiteres lokales Indexierungsschema, SSTable Attached Secondary Index (SASI), das komplexe Abfragen und Suchen unterstützt. Aus Sicht der Skalierbarkeit weist es jedoch genau die gleichen Eigenschaften wie die ursprünglichen Sekundärindizes auf.
Materialisierte Ansichten in Scylla und Apache Cassandra sind ein Mechanismus zum automatischen Denormalisieren von Daten aus einer Basistabelle in eine Ansichtstabelle unter Verwendung eines anderen Partitionsschlüssels. Dies löst das Skalierbarkeitsproblem lokaler Indizes, verursacht jedoch Speicherkosten, da Sie im schlimmsten Fall die gesamte Tabelle duplizieren müssen. Materialisierte Ansichten sind daher kein Ersatz für sekundäre Indizes für alle Anwendungsfälle. Materialisierte Ansichten bieten jedoch die erforderliche Infrastruktur, um Sekundärindizes mithilfe der globalen Indizierung zu implementieren.
Globale Indizierung
Scylla verfolgt einen anderen Ansatz als Apache Cassandra und implementiert sekundäre Indizes mithilfe der globalen Indizierung. Bei der globalen Indizierung wird für jeden Index eine materialisierte Ansicht erstellt. Die materialisierte Ansicht enthält die indizierte Spalte als Partitionsschlüssel und den Primärschlüssel (Partitionsschlüssel und Clusterschlüssel) der indizierten Zeile als Clusterschlüssel. Scylla unterteilt indizierte Abfragen in zwei Teile: (1) eine Abfrage der Indextabelle zum Abrufen von Partitionsschlüsseln für die indizierte Tabelle und (2) eine Abfrage der indizierten Tabelle mithilfe der abgerufenen Partitionsschlüssel. Der Vorteil dieses Ansatzes besteht darin, dass wir den Wert der indizierten Spalte verwenden können, um die entsprechende Indextabellenzeile im Cluster zu finden, sodass Lesevorgänge skalierbar sind. Der Nachteil des Ansatzes besteht darin, dass Schreibvorgänge langsamer sind als bei der lokalen Indizierung, da die Indexansicht auf dem neuesten Stand bleibt.
Die Abfrage einer indizierten Spalte sieht wie folgt aus. Nehmen wir eine Tabelle an, die so aussieht:
Und eine Abfrage für die Spalte email, die kein Partitionsschlüssel ist, sondern einen Index hat:
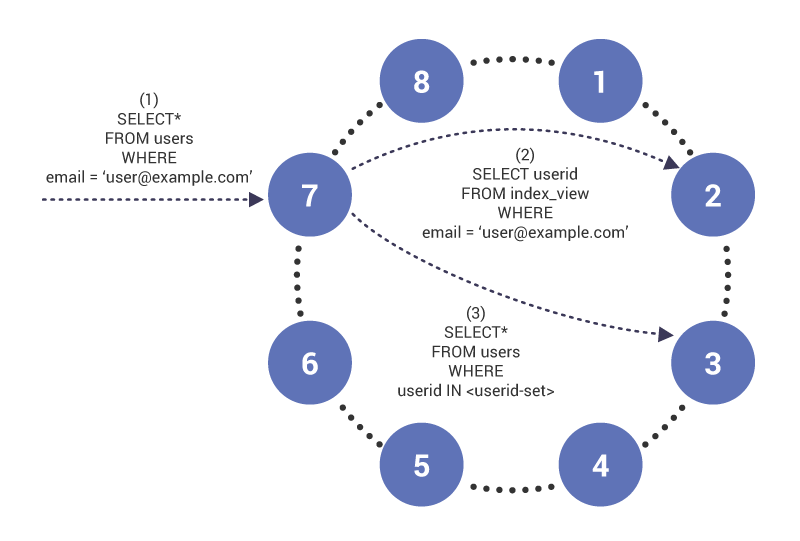
In Phase (1) trifft die Abfrage auf Knoten 7 ein, der als Koordinator für die Abfrage fungiert. Der Knoten bemerkt, dass wir eine indizierte Spalte abfragen, und gibt daher in Phase (2) einen read to index table auf Knoten 2 aus, der die Indextabellenzeile für “” enthält. Die Abfrage gibt einen Satz von Benutzer-IDs zurück, die in Phase (3) verwendet werden, um den Inhalt der indizierten Tabelle abzurufen.
Beispiel
Wir müssen zuerst ein Schema erstellen. In diesem Beispiel haben wir eine Tabelle, die Benutzerinformationen mit Benutzer-ID als Partitionsschlüssel und Name, E-Mail und Land als reguläre Spalten darstellt:
Wir füllen die Tabelle dann mit einigen mit Mockaroo generierten Testdaten:
Sekundärindizes wurden entwickelt, um eine effiziente Abfrage von Nicht-Partitionsschlüsselspalten zu ermöglichen. Während Apache Cassandra auch Abfragen für Nicht-Partitionsschlüsselspalten mit ALLOW FILTERING unterstützt, ist dies sehr ineffizient (erfordert das Scannen der gesamten Tabelle) und wird derzeit von Scylla nicht unterstützt (siehe Problem #2200 für Details).
Sie können Tabellenspalten mit der Anweisung CREATE INDEX indizieren. Um beispielsweise Indizes für E-Mail- und Länderspalten zu erstellen, führen Sie die folgenden CQL-Anweisungen aus:
Scylla erstellt automatisch eine materialisierte Ansicht, die die indizierte Spalte als Partitionsschlüssel und den Primärschlüssel der Zieltabelle (Partitionsschlüssel und Clusterschlüssel) als Clusterschlüssel enthält.
Die materialisierte Ansicht für den Index in der Spalte email sieht beispielsweise wie folgt aus:
Wenn die obige Ansicht als reguläre Tabelle erstellt würde, würde sie effektiv wie folgt aussehen:
Die Spalte email wird als Partitionsschlüssel für die Indextabelle verwendet und userid ist als Clusterschlüssel enthalten, mit dem wir Partitionsschlüssel für die Zieltabelle mit nur email effizient finden können.
Mit dem Befehl DESCRIBE können Sie das gesamte Schema für die Tabelle ks.users einschließlich der erstellten Indizes und Ansichten anzeigen:
Jetzt, da der sekundäre Index vorhanden ist, können Sie indizierte Spalten abfragen, als wären sie Partitionsschlüssel:
Wir sind fertig mit dem Beispiel!
Wann werden Sekundärindizes verwendet?
Sekundärindizes sind (meist) transparent für die Anwendung. Abfragen haben Zugriff auf alle Spalten in der Tabelle und Sie können Indizes hinzufügen und entfernen, ohne die Anwendung zu ändern. Sekundärindizes können auch einen geringeren Speicheraufwand haben als materialisierte Ansichten, da Sekundärindizes nur die indizierte Spalte und den Primärschlüssel duplizieren müssen, nicht die abgefragten Spalten wie bei einer materialisierten Ansicht. Darüber hinaus können Aktualisierungen aus demselben Grund mit sekundären Indizes effizienter sein, da nur Änderungen am Primärschlüssel und an der indizierten Spalte eine Aktualisierung in der Indexansicht verursachen. Bei einer materialisierten Ansicht muss für eine Aktualisierung einer der Spalten, die in der Ansicht angezeigt werden, die Hintergrundansicht aktualisiert werden.
Wie immer hängt die Entscheidung, ob Sekundärindizes oder materialisierte Ansichten verwendet werden, von den Anforderungen Ihrer Anwendung ab. Wenn Sie maximale Leistung benötigen und wahrscheinlich einen bestimmten Satz von Spalten abfragen, sollten Sie materialisierte Ansichten verwenden. Wenn die Anwendung jedoch unterschiedliche Spaltensätze abfragen muss, sind sekundäre Indizes die bessere Wahl, da sie je nach Anwendungsanforderungen mit weniger Speicheraufwand hinzugefügt und entfernt werden können.
Möchten Sie mehr über Sekundärindizes erfahren? Schauen Sie sich meine Präsentation vom Scylla Summit 2017 auf SlideShare an. Wenn Sie diese Funktion ausprobieren möchten, wird sie voraussichtlich in der kommenden Version von Scylla 2.2 enthalten sein.