Ceph
Benchmark Ceph Cluster Performance Australia
en av de vanligaste frågorna vi hör är “Hur kontrollerar jag om mitt kluster körs med maximal prestanda?”. Wonder no more-i den här guiden går vi igenom några verktyg du kan använda för att jämföra ditt Ceph-kluster.
Obs: ideerna i den här artikeln är baserade på Sebastian hans blogginlägg, Telekomclouds blogginlägg och ingångar från Ceph-utvecklare och ingenjörer.
få Baslinjeprestationsstatistik i genomsnitt
i grund och botten handlar benchmarking om jämförelse. Du vet inte om du Ceph cluster utför under par om du inte först identifierar vad dess maximala möjliga prestanda är. Så innan du börjar benchmarking ditt kluster måste du få baslinjeprestandastatistik för de två huvudkomponenterna i din Ceph-Infrastruktur: dina diskar och ditt nätverk.
Benchmark your Disks Ukrainian
det enklaste sättet att benchmark din disk är med dd. Använd följande kommando för att läsa och skriva en fil, kom ihåg att lägga till Oflag-parametern för att kringgå disksidans cache:shell> dd if=/dev/zero of=here bs=1G count=1 oflag=direct
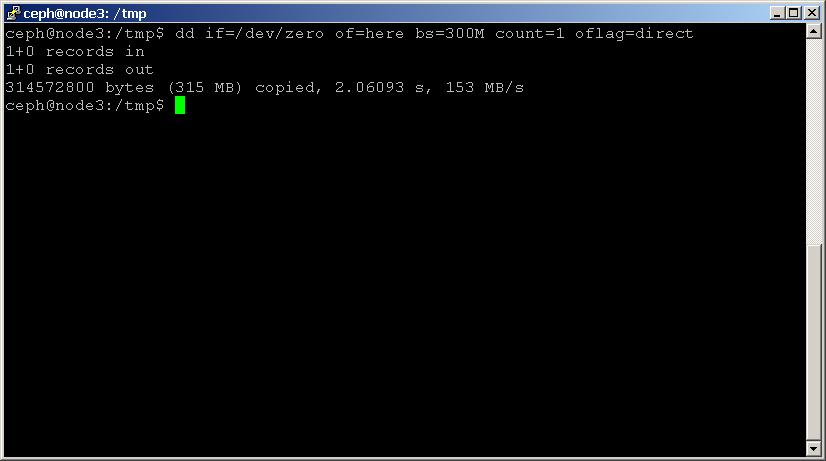
notera den senaste statistiken som tillhandahålls, vilket indikerar diskprestanda i MB / sek. utför detta test för varje disk i ditt kluster och notera resultaten.
Benchmark ditt nätverk 2683>
en annan viktig faktor som påverkar Ceph-klusterprestanda är nätverksflödet. Ett bra verktyg för detta är iperf, som använder en klient-serveranslutning för att mäta TCP-och UDP-bandbredd.
du kan installera iperf med apt-get install iperf eller yum install iperf.
iperf måste installeras på minst två noder i klustret. Starta sedan iperf-servern på en av noderna med följande kommando:
shell> iperf -s
på en annan nod, starta klienten med följande kommando, kom ihåg att använda IP-adressen för noden som är värd för iperf-servern:
shell> iperf -c 192.168.1.1
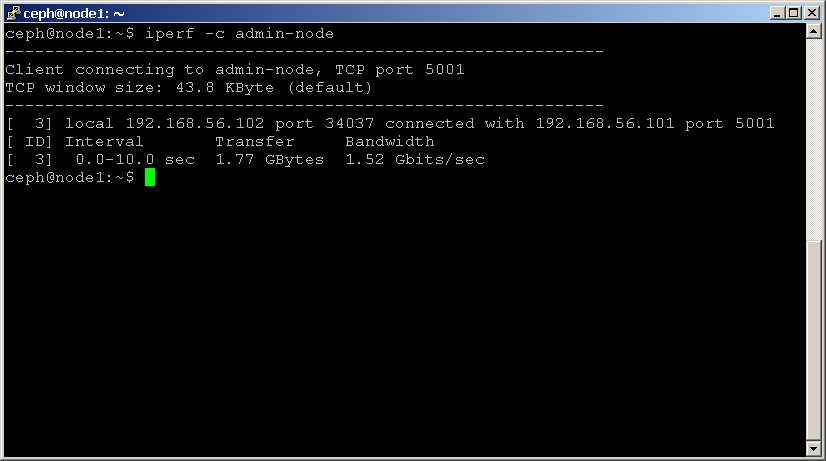
notera bandbreddstatistiken i Mbits / sek, eftersom detta indikerar den maximala genomströmningen som stöds av ditt nätverk.
nu när du har några baslinjetal kan du börja benchmarking ditt Ceph-kluster för att se om det ger dig liknande prestanda. Benchmarking kan utföras på olika nivåer: du kan utföra benchmarking på låg nivå av själva lagringsklustret, eller så kan du utföra benchmarking på högre nivå av nyckelgränssnitten, till exempel blockenheter och objektgateways. Följande avsnitt diskuterar vart och ett av dessa tillvägagångssätt.
OBS: innan du kör något av riktmärkena i efterföljande avsnitt, släpp alla cachar med ett kommando som detta:shell> sudo echo 3 | sudo tee /proc/sys/vm/drop_caches && sudo sync
Benchmark a Ceph Storage Cluster 2249 >
Ceph innehåller rados bench-kommandot, utformat speciellt för att jämföra ett RADOS storage cluster . För att använda den, skapa en lagringspool och använd sedan rados bench för att utföra ett skrivriktmärke, som visas nedan.
Rados-kommandot ingår i Ceph.
shell> ceph osd pool create scbench 128 128
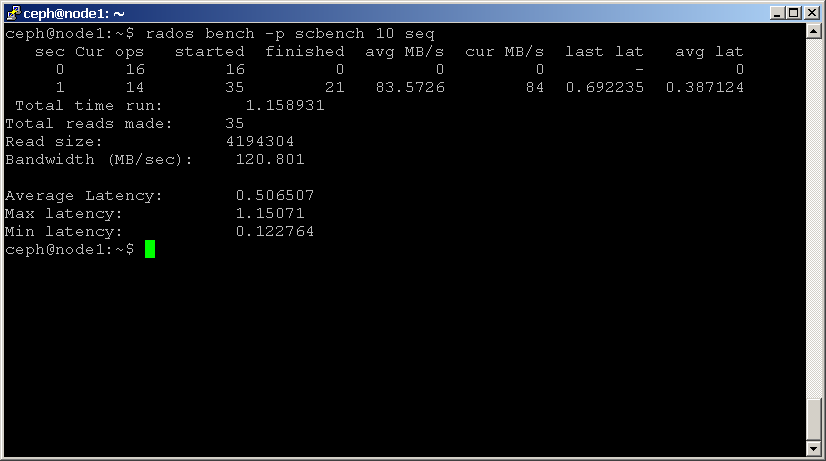
shell> rados bench -p scbench 10 write --no-cleanup
detta skapar en ny pool med namnet ‘scbench’ och utför sedan ett skrivriktmärke i 10 sekunder. Lägg märke till — no-cleanup-alternativet, vilket lämnar vissa data. Utgången ger dig en bra indikator på hur snabbt ditt kluster kan skriva data.
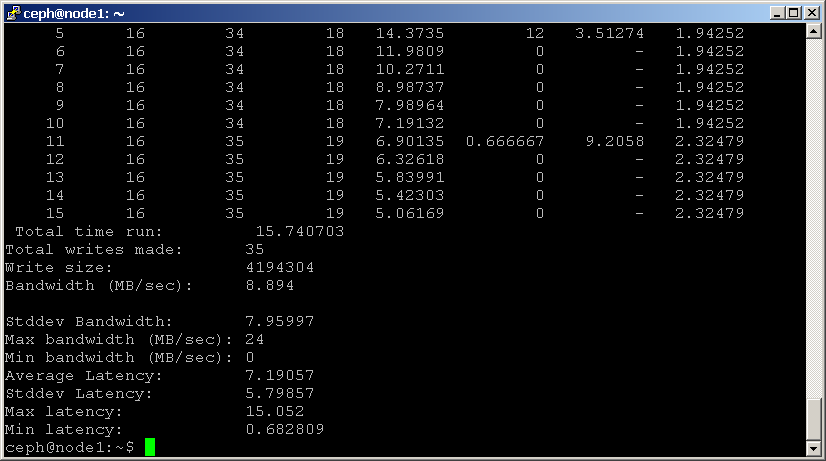
två typer av läsningsriktmärken finns tillgängliga: seq för sekventiella läsningar och rand för slumpmässiga läsningar. För att utföra ett läs-riktmärke, använd kommandona nedan:shell> rados bench -p scbench 10 seq
shell> rados bench -p scbench 10 rand
du kan också lägga till-t-parametern för att öka samtidigheten för läsningar och skrivningar (Standardvärdet är 16 trådar) eller-b-parametern för att ändra storleken på objektet som skrivs (Standardvärdet är 4 MB). Det är också bra att köra flera kopior av detta riktmärke mot olika pooler, för att se hur prestanda förändras med flera klienter.
när du har data kan du börja jämföra klustrets läs-och skrivstatistik med de diskbara riktmärken som utförts tidigare, identifiera hur mycket av ett prestandagap som finns (om det finns några) och börja leta efter skäl.
du kan rensa upp referensdata som lämnats av skrivriktmärket med det här kommandot:
shell> rados -p scbench cleanup
Benchmark a Ceph Block Device exceptional
om du är ett fan av Ceph block-enheter finns det två verktyg du kan använda för att jämföra deras prestanda. Ceph innehåller redan kommandot rbd bench, men du kan också använda det populära i/O-benchmarkingverktyget fio, som nu kommer med inbyggt stöd för RADOS-blockenheter.
RBD-kommandot ingår i Ceph. RBD-stöd i fio är relativt nytt, därför måste du ladda ner det från dess förråd och sedan kompilera och installera det med hjälp av_ konfigurera && gör && gör install_. Observera att du måste installera librbd-dev-utvecklingspaketet med apt-get install librbd-Dev eller yum install librbd-dev innan du sammanställer fio för att aktivera dess RBD-stöd.
innan du använder något av dessa två verktyg, skapa dock en blockenhet med kommandona nedan:shell> ceph osd pool create rbdbench 128 128
shell> rbd create image01 --size 1024 --pool rbdbench
shell> sudo rbd map image01 --pool rbdbench --name client.admin
shell> sudo /sbin/mkfs.ext4 -m0 /dev/rbd/rbdbench/image01
shell> sudo mkdir /mnt/ceph-block-device
shell> sudo mount /dev/rbd/rbdbench/image01 /mnt/ceph-block-device
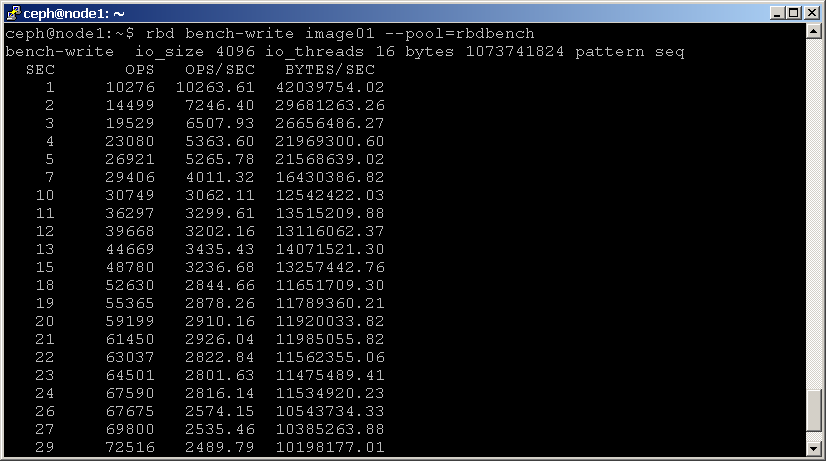
kommandot RBD bench-write genererar en serie sekventiella skrivningar till bilden och mäter skrivgenomströmningen och latensen. Här är ett exempel:
shell> rbd bench-write image01 --pool=rbdbench
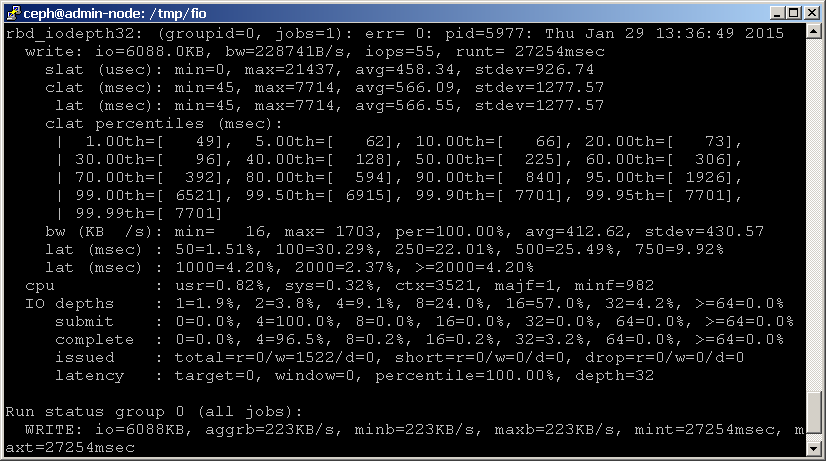
eller så kan du använda fio för att jämföra din blockenhet. Ett exempel rbd.fio-mall ingår i fio-källkoden, som utför ett 4K slumpmässigt skrivtest mot en RADOS-blockenhet via librbd. Observera att du måste uppdatera mallen med rätt namn för din pool och enhet, som visas nedan.
ioengine=rbd
clientname=admin
pool=rbdbench
rbdname=image01
rw=randwrite
bs=4k
iodepth=32
kör sedan fio enligt följande:shell> fio examples/rbd.fio
Benchmark a Ceph Object Gateway
när det gäller benchmarking av Ceph object gateway, leta inte längre än swift-bench, benchmarking-verktyget som ingår i OpenStack Swift. Swift-bench-verktyget testar prestandan för ditt Ceph-kluster genom att simulera klient PUT and GET-förfrågningar och mäta deras prestanda.
du kan installera swift-bench med pip install swift && pip install swift-bench.
för att använda swift-bench måste du först skapa en gateway-användare och underanvändare, som visas nedan:shell> sudo radosgw-admin user create --uid="benchmark" --display-name="benchmark"
shell> sudo radosgw-admin subuser create --uid=benchmark --subuser=benchmark:swift
--access=full
shell> sudo radosgw-admin key create --subuser=benchmark:swift --key-type=swift
--secret=guessme
shell> radosgw-admin user modify --uid=benchmark --max-buckets=0
skapa sedan en konfigurationsfil för swift-bench på en klientvärd, enligt nedan. Kom ihåg att uppdatera autentiseringsadressen för att återspegla den för din Ceph object gateway och att använda rätt användarnamn och referenser.
auth = http://gateway-node/auth/v1.0
user = benchmark:swift
key = guessme
auth_version = 1.0
du kan nu köra ett riktmärke enligt nedan. Använd parametern-c för att justera antalet samtidiga anslutningar (i det här exemplet används 64) och parametern-s för att justera storleken på objektet som skrivs (i det här exemplet används 4K-objekt). Parametrarna-n och-g styr antalet objekt som ska sättas respektive.shell> swift-bench -c 64 -s 4096 -n 1000 -g 100 /tmp/swift.conf
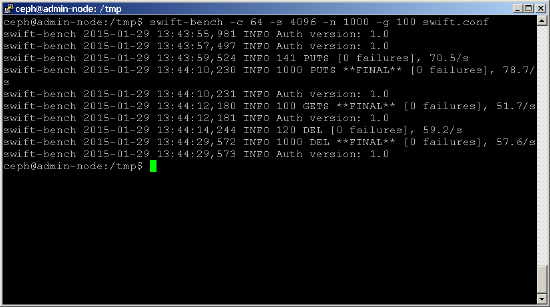
även om swift-bench mäter prestanda i antal objekt / sek, är det lätt att konvertera detta till MB/sek, genom att multiplicera med storleken på varje objekt. Du bör dock vara försiktig med att jämföra detta direkt med baslinjen diskprestanda statistik du fått tidigare, eftersom ett antal andra faktorer påverkar också denna statistik, såsom:
- nivån på replikering (och latency overhead)
- full Data journal skriver (offset i vissa situationer av journal data coalescing)
- fsync på OSDs för att garantera datasäkerhet
- metadata overhead för att hålla data lagrade i RADOS
- latency overhead (nätverk, Ceph, etc) gör readahead viktigare
tips: När det gäller object gateway-prestanda finns det ingen hård och snabb regel som du kan använda för att enkelt förbättra prestanda. I vissa fall har Ceph-ingenjörer kunnat få bättre prestanda än baslinjen med hjälp av smarta cachnings-och koalescerande strategier, medan object gateway-prestanda i andra fall har varit lägre än diskprestanda på grund av latens, fsync och metadatakostnader.
slutsats Bisexuell
det finns ett antal verktyg tillgängliga för att jämföra ett Ceph-kluster, på olika nivåer: disk, nätverk, kluster, enhet och gateway. Du bör nu ha lite inblick i hur du närmar dig benchmarkingprocessen och börjar generera prestandadata för ditt kluster. Lycka till!