Cloud Data Warehouse vs traditionella Data Warehouse Concepts
molnbaserade datalager är den nya normen. Borta är de dagar då ditt företag var tvungen att köpa hårdvara, skapa serverrum och hyra, träna och upprätthålla ett dedikerat team av personal för att driva det. Nu, med några klick på din bärbara dator och ett kreditkort, kan du komma åt praktiskt taget obegränsad datorkraft och lagringsutrymme.
detta betyder dock inte att traditionella datalagerideer är döda. Klassisk datalagerteori ligger till grund för det mesta av vad molnbaserade datalager gör.
i den här artikeln förklarar vi de traditionella datalagerkoncepten du behöver veta och de viktigaste molnkoncepten från ett urval av de bästa leverantörerna: Amazon, Google och Panoply. Slutligen avslutar vi med en kostnads-nyttoanalys av traditionella vs. molndatalager, så att du vet vilken som är rätt för dig.
Låt oss komma igång.
- traditionella Datalagerkoncept
- fakta, dimensioner och mått
- normalisering och Denormalisering
- datamodeller
- faktatabell
- Star Schema vs. Snowflake Schema
- OLAP vs. OLTP
- tre Nivåarkitektur
- Virtual Data Warehouse / Data Mart
- Kimball vs. Inmon
- ETL vs. ELT
- Enterprise Data Warehouse
- Cloud Data Warehouse Concepts
- Cloud Data Warehouse Concepts – Amazon Redshift
- kluster
- noder
- partitioner/skivor
- Columnar Storage
- komprimering
- data Loading
- Cloud Database Warehouse – Google BigQuery
- serverlös tjänst
- Colossus filsystem
- Dremel Execution Engine
- datadelning
- Streaming och Batch förtäring
- Cloud Data Warehouse Concepts – Panoply
- primära nycklar
- inkrementella nycklar
- kapslade Data
- Historiktabeller
- transformationer
- strängformat
- dataskydd
- åtkomstkontroll
- IP-vitlistning
- slutsats: traditionella vs. Data Warehouse Concepts i korthet
- traditionella Datalagerkoncept
- Cloud Data Warehouse Concepts-Amazon Redshift som exempel
- Cloud Data Warehouse Concepts-BigQuery som exempel
- traditionell kontra Molnkostnads-nyttoanalys
- Läs mer om datalager
traditionella Datalagerkoncept
ett datalager är ett system som samlar data från ett brett spektrum av källor inom en organisation. Datalager används som centraliserade datalager för analys-och rapporteringsändamål.
ett traditionellt datalager finns på plats på ditt kontor. Du köper hårdvaran, serverrummen och anställer personalen för att köra den. De kallas också lokala, lokala eller (grammatiskt felaktiga) lokala datalager.
fakta, dimensioner och mått
de centrala byggstenarna för information i ett datalager är fakta, dimensioner och mått.
ett faktum är den del av dina data som indikerar en specifik händelse eller transaktion. Till exempel, om ditt företag säljer blommor, är några fakta du skulle se i ditt datalager:
- säljs 30 rosor i butik för $19.99
- beställde 500 nya blomkrukor från Kina för $1500
- betald lön för kassören för denna månad $1000
flera siffror kan beskriva varje faktum, och vi kallar dessa siffror åtgärder. Några åtgärder för att beskriva faktumet ‘beställde 500 nya blomkrukor från Kina för $1500’ är:
- beställd kvantitet-500
- kostnad – $1500
när analytiker arbetar med data utför de beräkningar på mått (t.ex. summa, maximum, average) för att få fram insikter. Till exempel kanske du vill veta det genomsnittliga antalet blomkrukor du beställer varje månad.
en dimension kategoriserar fakta och åtgärder och ger strukturerad märkningsinformation för dem – annars skulle de bara vara en samling oordnade nummer! Några dimensioner för att beskriva faktumet ‘beställde 500 nya blomkrukor från Kina för $1500’ är:
- Land köpt från-Kina
- tid köpt – 1 pm
- förväntat ankomstdatum – 6 juni
du kan inte utföra beräkningar på dimensioner uttryckligen, och det skulle förmodligen inte vara till stor hjälp – hur kan du hitta ‘genomsnittligt ankomstdatum för beställningar’? Det är dock möjligt att skapa nya mått från dimensioner, och dessa är användbara. Om du till exempel vet det genomsnittliga antalet dagar mellan orderdatum och ankomstdatum kan du bättre planera lagerKöp.
normalisering och Denormalisering
normalisering är processen att effektivt organisera data i ett datalager (eller någon annan plats som lagrar data). De viktigaste målen är att minska dataredundans-dvs. ta bort eventuella dubbla data – och förbättra dataintegriteten – dvs. förbättra noggrannheten i data. Det finns olika nivåer av normalisering och ingen konsensus för den bästa metoden. Alla metoder innebär dock att man lagrar separata men relaterade bitar av information i olika tabeller.
det finns många fördelar med normalisering, såsom:
- snabbare sökning och sortering på varje tabell
- enklare tabeller gör kommandon för dataändring snabbare för att skriva och köra
- mindre överflödiga data innebär att du sparar på diskutrymme och så kan du samla in och lagra mer data
Denormalisering är processen att medvetet lägga till överflödiga kopior eller grupper av data till redan normaliserade data. Det är inte samma sak som icke-normaliserade data. Denormalisering förbättrar läsprestanda och gör det mycket lättare att manipulera tabeller i formulär du vill ha. När analytiker arbetar med datalager utför de vanligtvis bara läsningar på data. Således kan denormaliserade data spara dem stora mängder tid och huvudvärk.
fördelar med denormalisering:
- färre tabeller minimerar behovet av tabellanslutningar som påskyndar dataanalytikernas arbetsflöde och leder dem att upptäcka mer användbara insikter i data
- färre tabeller förenklar frågor som leder till färre buggar
datamodeller
det skulle vara väldigt ineffektivt att lagra alla dina data i en massiv tabell. Så, ditt datalager innehåller många tabeller som du kan gå ihop för att få specifik information. Huvudtabellen kallas en faktatabell och dimensionstabeller omger den.
det första steget i att utforma ett datalager är att bygga en konceptuell datamodell som definierar de data du vill ha och relationerna på hög nivå mellan dem.
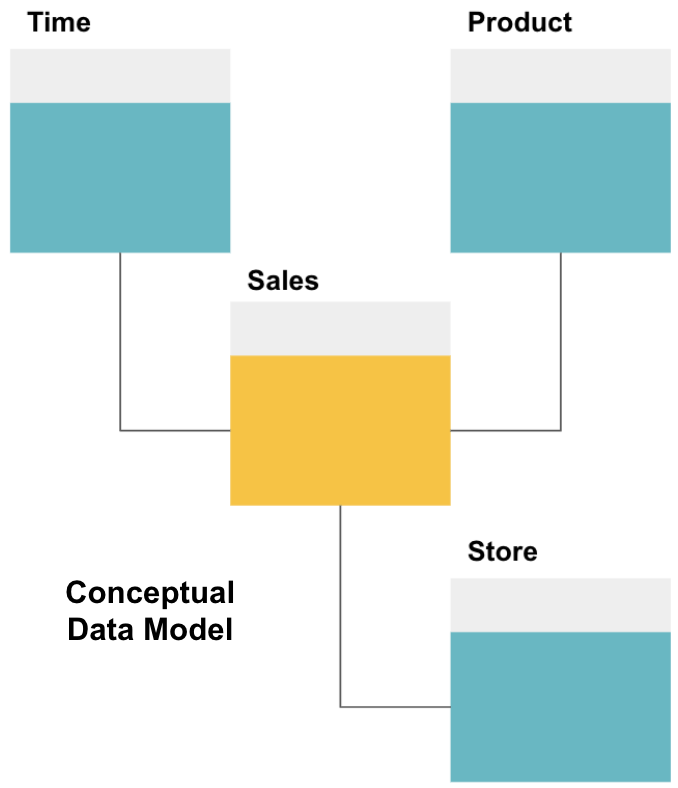
här har vi definierat den konceptuella modellen. Vi lagrar försäljningsdata och har ytterligare tre tabeller – tid, produkt och butik – som ger extra, mer detaljerad information om varje försäljning. Faktatabellen är försäljning, och de andra är dimensionstabeller.
nästa steg är att definiera en logisk datamodell. Denna modell beskriver data i detalj på vanlig engelska utan att oroa sig för hur man implementerar den i kod.
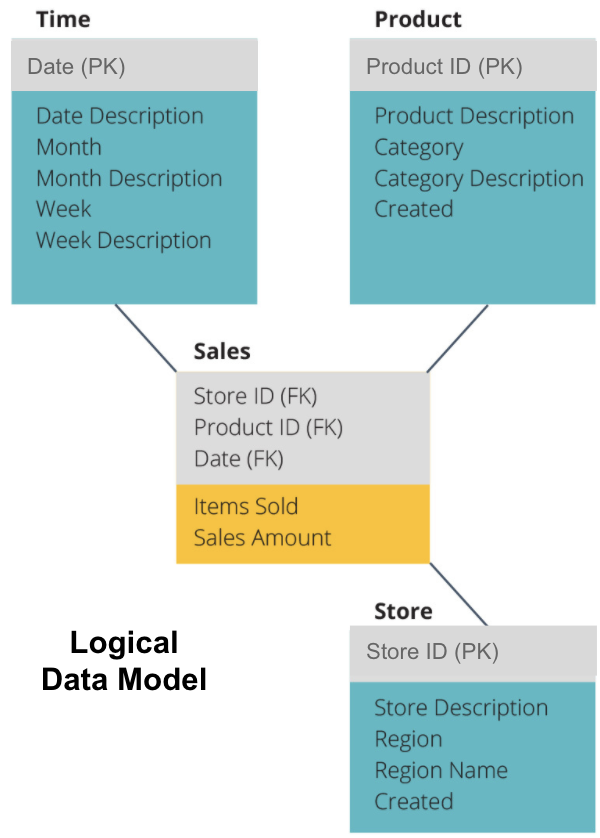
nu har vi fyllt i vilken information varje tabell innehåller på vanlig engelska. Varje dimensionstabell för tid, produkt och butik visar primärnyckeln (PK) i den grå rutan och motsvarande data i de blå rutorna. Försäljningstabellen innehåller tre utländska nycklar (FK) så att den snabbt kan gå med i de andra tabellerna.
det sista steget är att skapa en fysisk datamodell. Denna modell berättar hur du implementerar datalagret i kod. Det definierar tabeller, deras struktur och förhållandet mellan dem. Det anger också datatyper för kolumner, och allt heter som det kommer att finnas i det slutliga datalagret, dvs alla kepsar och kopplade till understreck. Slutligen börjar varje dimensionstabell med DIM_, och varje faktatabell börjar med FACT_.
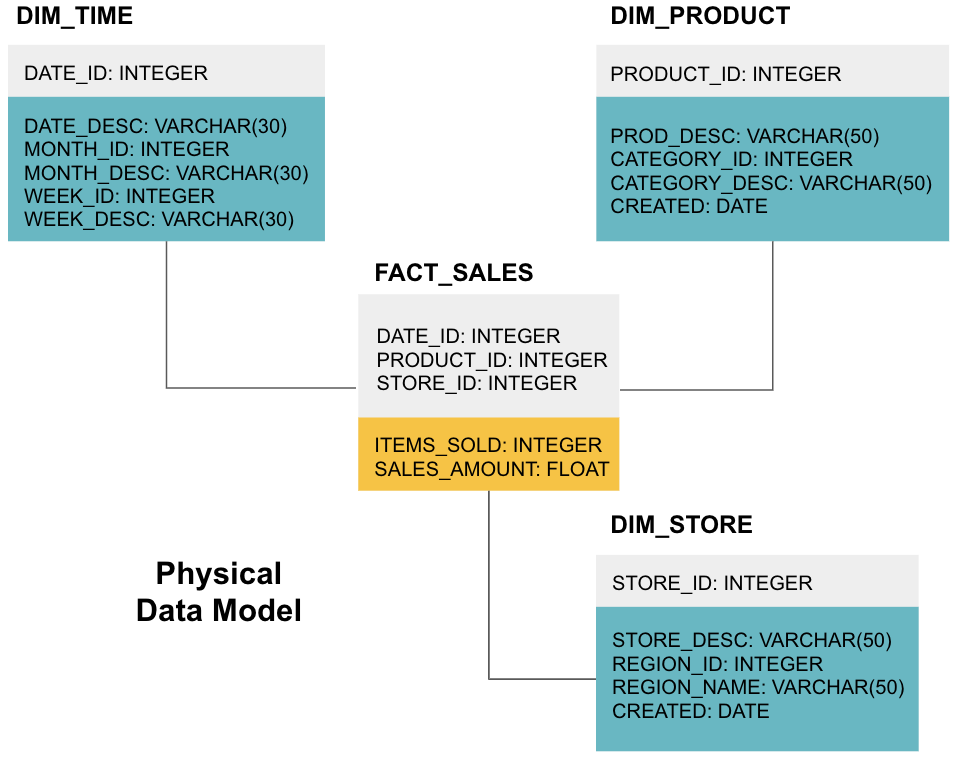
nu vet du hur man utformar ett datalager, men det finns några nyanser till fakta-och dimensionstabeller som vi kommer att förklara nästa.
faktatabell
varje affärsfunktion – t.ex. försäljning, marknadsföring, ekonomi – har en motsvarande faktatabell.
faktatabeller har två typer av kolumner: dimensionskolumner och faktokolumner. Dimensionskolumner-färgade grå i våra exempel-innehåller främmande nycklar (FK) som du använder för att gå med i en faktatabell med en dimensionstabell. Dessa främmande nycklar är Primärnycklarna (PK) för var och en av dimensionstabellerna. Faktakolumner-färgade gula i våra exempel-innehåller de faktiska data och åtgärder som ska analyseras, t.ex. antalet sålda artiklar och det totala dollarvärdet av försäljningen.
en faktumlös faktatabell är en viss typ av faktatabell som bara har dimensionskolumner. Sådana tabeller är användbara för att spåra händelser, till exempel studentdeltagande eller anställdas ledighet, eftersom dimensionerna berättar allt du behöver veta om händelserna.
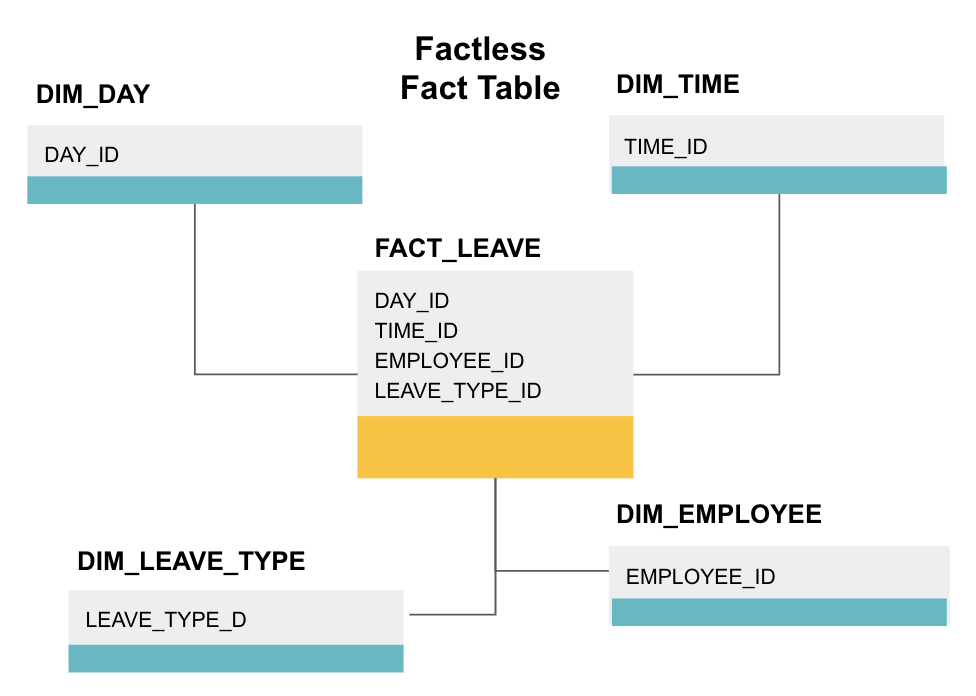
ovanstående faktalösa faktatabell spårar anställdas ledighet. Det finns inga fakta eftersom du bara behöver veta:
- vilken dag de var lediga (DAY_ID).
- hur länge de var avstängda (TIME_ID).
- Vem var på permission (EMPLOYEE_ID).
- deras anledning till att vara ledig, t. ex., sjukdom, semester, läkarmöte etc. (LEAVE_TYPE_ID).
Star Schema vs. Snowflake Schema
ovanstående datalager har alla haft en liknande layout. Detta är dock inte det enda sättet att ordna dem.
de två vanligaste scheman som används för att organisera datalager är star och snowflake. Båda metoderna använder dimensionstabeller som beskriver informationen i en faktatabell.
stjärnschemat tar informationen från faktatabellen och delar upp den i denormaliserade dimensionstabeller. Tyngdpunkten för stjärnschemat ligger på frågehastighet. Endast en koppling behövs för att länka faktatabeller till varje dimension, så det är enkelt att fråga varje tabell. Men eftersom tabellerna är denormaliserade innehåller de ofta upprepade och överflödiga data.
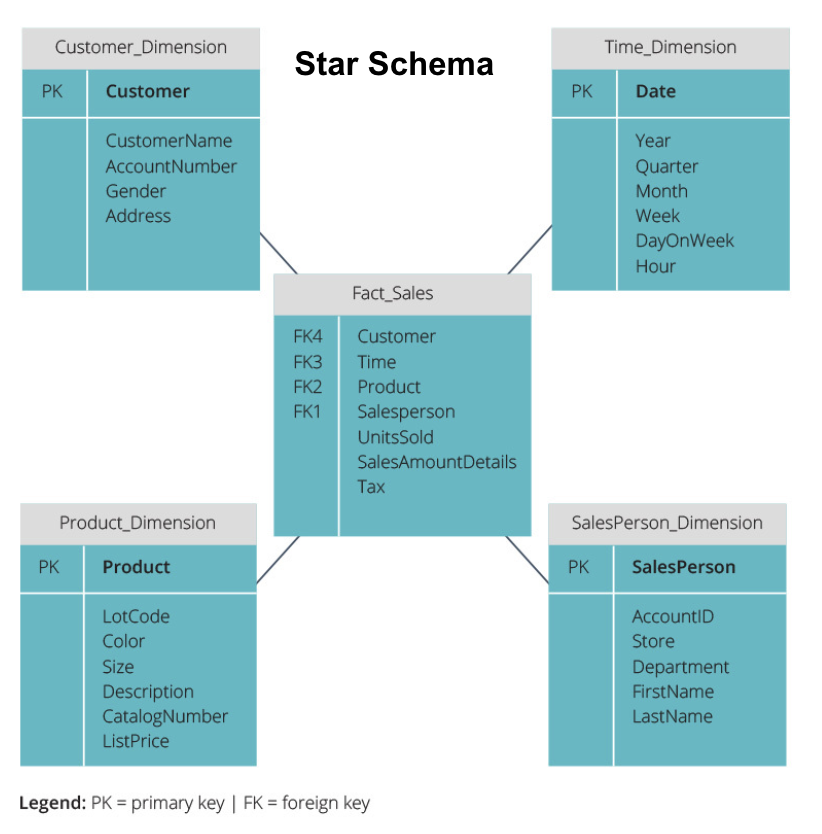
snowflake-schemat delar upp faktatabellen i en serie normaliserade dimensionstabeller. Normalisering skapar fler dimensionstabeller och minskar därmed dataintegritetsproblem. Att fråga är dock mer utmanande med hjälp av snowflake-schemat eftersom du behöver fler tabellkopplingar för att komma åt relevanta data. Så du har mindre överflödiga data, men det är svårare att komma åt.
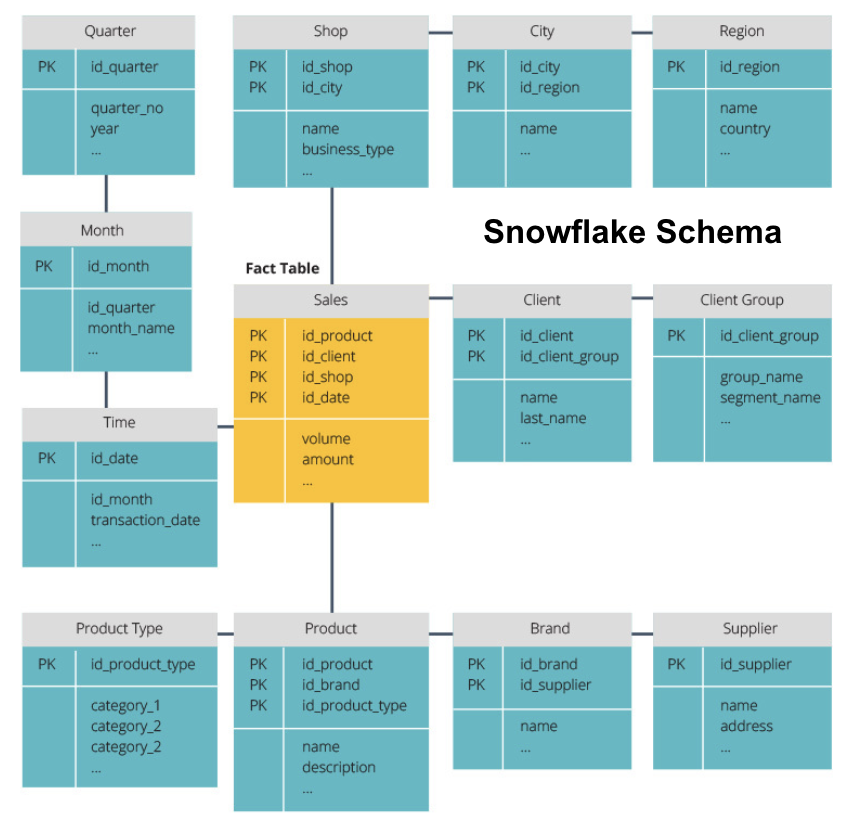
nu ska vi förklara några mer grundläggande datalagerkoncept.
OLAP vs. OLTP
online transaction processing (OLTP) kännetecknas av korta skrivtransaktioner som involverar front-end-applikationerna i ett företags dataarkitektur. OLTP-databaser betonar snabb frågebehandling och hanterar bara aktuella data. Företag använder dessa för att samla in information för affärsprocesser och tillhandahålla källdata för datalagret.
online analytical processing (OLAP) låter dig köra komplexa läsfrågor och därmed utföra en detaljerad analys av historiska transaktionsdata. OLAP-system hjälper till att analysera data i datalagret.
tre Nivåarkitektur
traditionella datalager är vanligtvis strukturerade i tre nivåer:
- nedre nivå: en databasserver, vanligtvis en RDBMS, som extraherar data från olika källor med hjälp av en gateway. Datakällor som matas in i denna nivå inkluderar operativa databaser och andra typer av front-end-data som CSV-och JSON-filer.
- mellannivå: en OLAP-server som antingen
- direkt implementerar operationerna, eller
- kartlägger operationerna på flerdimensionella data till standardrelationella operationer, t.ex. plattning av XML-eller JSON-data i rader i tabeller.
- Top Tier: frågande och rapporteringsverktyg för dataanalys och business intelligence.
Virtual Data Warehouse / Data Mart
Virtual data warehousing använder distribuerade frågor på flera databaser, utan att integrera data i ett fysiskt datalager.
Data marts är delmängder av datalager inriktade på specifika affärsfunktioner, såsom försäljning eller ekonomi. Ett datalager kombinerar vanligtvis information från flera data marts i flera affärsfunktioner. Ändå innehåller en data mart data från en uppsättning källsystem för en affärsfunktion.
Kimball vs. Inmon
det finns två tillvägagångssätt för datalagerdesign, föreslagen av Bill Inmon och Ralph Kimball. Bill Inmon är en amerikansk datavetare som är erkänd som far till data warehouse. Ralph Kimball är en av de ursprungliga arkitekterna för datalagring och har skrivit flera böcker om ämnet.
de två experterna hade motstridiga åsikter om hur datalager skulle struktureras. Denna konflikt har gett upphov till två tankeskolor.
Inmon-metoden är en top-down-design. Med inmon-metoden skapas datalagret först och ses som den centrala komponenten i den analytiska miljön. Data sammanfattas sedan och distribueras från det centraliserade lagret till en eller flera beroende datamarter.
Kimball-metoden tar en bottom-up-vy av datalagerdesign. I denna arkitektur skapar en organisation separata data marts, som ger vyer i enskilda avdelningar inom en organisation. Data warehouse är kombinationen av dessa data marts.
ETL vs. ELT
extrahera, transformera, ladda (ETL) beskriver processen att extrahera data från källsystem (vanligtvis transaktionssystem), konvertera data till ett format eller en struktur som är lämplig för fråga och analys och slutligen ladda den i datalagret. ETL utnyttjar en separat staging-databas och tillämpar en serie regler eller funktioner på den extraherade data innan den laddas.
Extract, Load, Transform (ELT) är ett annat sätt att ladda data. ELT tar data från olika källor och laddar dem direkt i målsystemet, till exempel datalagret. Systemet omvandlar sedan den laddade data on-demand för att möjliggöra analys.
ELT erbjuder snabbare laddning än ETL, men det kräver ett kraftfullt system för att utföra datatransformationer på begäran.
Enterprise Data Warehouse
ett enterprise data warehouse är avsett som ett enhetligt, centraliserat lager som innehåller all transaktionsinformation i organisationen, både aktuell och historisk. Ett företagsdatalager bör innehålla data från alla ämnesområden relaterade till verksamheten, såsom marknadsföring, försäljning, ekonomi och personalresurser.
dessa är de grundläggande ideerna som utgör traditionella datalager. Låt oss nu titta på vilka molndatalager som har lagts till ovanpå dem.
Cloud Data Warehouse Concepts
Cloud Data Warehouse är nya och ständigt förändras. För att bäst förstå deras grundläggande begrepp är det bäst att lära sig om de ledande molndatalagerlösningarna.
tre ledande molndatalagerlösningar är Amazon Redshift, Google BigQuery och Panoply. Nedan förklarar vi grundläggande begrepp från var och en av dessa tjänster för att ge dig en allmän förståelse för hur moderna datalager fungerar.
Cloud Data Warehouse Concepts – Amazon Redshift
följande begrepp används uttryckligen i Amazon Redshift cloud data warehouse men kan gälla för ytterligare data warehouse-lösningar i framtiden baserat på Amazon-Infrastruktur.
kluster
Amazon Redshift baserar sin arkitektur på kluster. Ett kluster är helt enkelt en grupp delade datorresurser, kallade noder.
noder
noder är datorresurser som har CPU, RAM och hårddiskutrymme. Ett kluster som innehåller två eller flera noder består av en ledare nod och beräkna noder.
Leadernoder kommunicerar med klientprogram och kompilerar kod för att utföra frågor, tilldela den för att beräkna noder. Compute nodes kör frågorna och returnerar resultaten till leadernoden. En beräkningsnod kör bara frågor som refererar till tabeller som är lagrade på den noden.
partitioner/skivor
Amazon partitioner varje compute nod i skivor. En skiva tar emot en tilldelning av minne och diskutrymme på noden. Flera skivor fungerar parallellt för att påskynda exekveringstiden för frågan.
Columnar Storage
Redshift använder columnar storage, vilket möjliggör bättre analytisk frågeprestanda. I stället för att lagra poster i rader lagras värden från en enda kolumn för flera rader. Följande diagram gör detta tydligare:
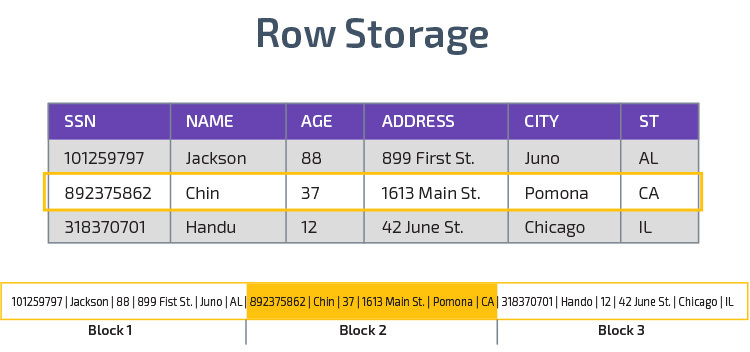
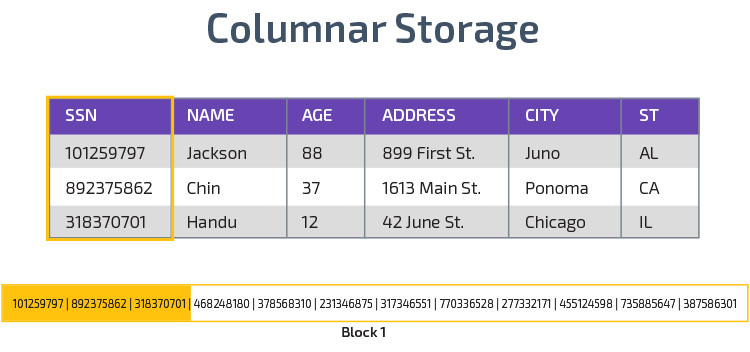
Kolumnlagring gör det möjligt att läsa data snabbare, vilket är avgörande för analytiska frågor som spänner över många kolumner i en datamängd. Kolumnlagring tar också mindre diskutrymme, eftersom varje block innehåller samma typ av data, vilket betyder att det kan komprimeras till ett specifikt format.
komprimering
komprimering minskar storleken på lagrade data. I Redshift, på grund av hur data lagras, sker komprimering på kolumnnivå. Redshift låter dig komprimera information manuellt när du skapar en tabell eller automatiskt använder kommandot Kopiera.
data Loading
du kan använda redshifts KOPIERINGSKOMMANDO för att ladda stora mängder data i datalagret. Kopieringskommandot utnyttjar redshifts MPP-arkitektur för att läsa och ladda data parallellt från filer på Amazon S3, från en DynamoDB-tabell eller textutmatning från en eller flera fjärrvärdar.
det är också möjligt att strömma data till Redshift med hjälp av Amazon Kinesis Firehose-tjänsten.
Cloud Database Warehouse – Google BigQuery
följande begrepp används uttryckligen i Google BigQuery cloud data warehouse men kan gälla ytterligare lösningar i framtiden baserat på Googles infrastruktur.
serverlös tjänst
BigQuery använder serverlös arkitektur. Med BigQuery behöver företag inte hantera fysiska serverenheter för att driva sina datalager. Istället hanterar BigQuery dynamiskt fördelningen av sina datorresurser. Företag som använder tjänsten betalar helt enkelt för datalagring per gigabyte och frågor per terabyte.
Colossus filsystem
BigQuery använder den senaste versionen av Googles distribuerade filsystem, kodnamnet Colossus. Colossus-filsystemet använder kolumnar lagrings-och komprimeringsalgoritmer för att lagra data för analytiska ändamål optimalt.
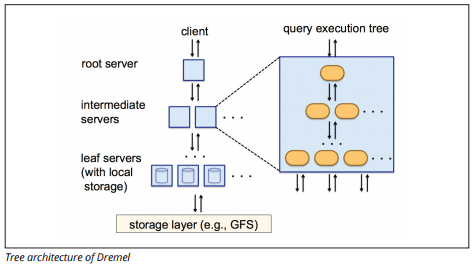
Dremel Execution Engine
Dremel execution engine använder en kolumnär layout för att snabbt söka stora datalager. Dremels exekveringsmotor kan köra ad hoc-frågor på miljarder rader på några sekunder eftersom den använder massivt parallell bearbetning i form av en trädarkitektur.
trädarkitekturen distribuerar frågor mellan flera mellanliggande servrar från en rotserver. De mellanliggande servrarna trycker ner frågan till leaf-servrar (som innehåller lagrad data), som skannar data parallellt. På vägen tillbaka upp i trädet skickar varje bladserver frågeresultat, och de mellanliggande servrarna utför en parallell aggregering av partiella resultat.
Bildkälla
Dremel gör det möjligt för organisationer att köra frågor på upp till tiotusentals servrar samtidigt. Enligt Google kan Dremel skanna 35 miljarder rader utan index på tiotals sekunder.
datadelning
Google Bigquerys serverlösa arkitektur gör det möjligt för företag att enkelt dela data med andra organisationer utan att kräva att dessa organisationer investerar i sin egen lagring.
organisationer som vill fråga delade data kan göra det, och de betalar bara för frågorna. Det finns inget behov av att skapa kostsamma delade datasilor, utanför organisationens datainfrastruktur, och kopiera data till dessa silor.
Streaming och Batch förtäring
det är möjligt att ladda data till BigQuery från Google Cloud Storage, inklusive CSV, JSON (newline-avgränsad), och Avro-filer, samt Google Cloud datastore säkerhetskopior. Du kan också ladda data direkt från en läsbar datakälla.
BigQuery erbjuder också ett Streaming API för att ladda data i systemet med en hastighet på miljontals rader per sekund utan att utföra en belastning. Uppgifterna är tillgängliga för analys nästan omedelbart.
Cloud Data Warehouse Concepts – Panoply
Panoply är ett allt-i-ett-lager som kombinerar ETL med ett kraftfullt datalager. Det är det enklaste sättet att synkronisera, lagra och komma åt ett företags data genom att eliminera utvecklingen och kodningen i samband med att omvandla, integrera och hantera stora data.
Nedan följer några av huvudkoncepten i Panoply data warehouse relaterade till datamodellering och dataskydd.
primära nycklar
primära nycklar se till att alla rader i dina tabeller är unika. Varje tabell har en eller flera primära nycklar som definierar vad som representerar en enda unik rad i databasen. Alla API: er har en standard primärnyckel för tabeller.
inkrementella nycklar
Panoply använder en inkrementell nyckel för att styra attribut för stegvis laddning av data till datalagret från källor snarare än att ladda om hela datauppsättningen varje gång något ändras. Den här funktionen är användbar för större datamängder, vilket kan ta lång tid att läsa mestadels oförändrade data. Inkrementell nyckel anger den senaste uppdateringspunkten för raderna i den datakällan.
kapslade Data
kapslade data är inte helt kompatibel med BI—sviter och standard SQL-frågor-Panoply behandlar kapslade data genom att använda en starkt relationell modell som inte tillåter kapslade värden. Panoply omvandlar kapslade data på dessa sätt:
- Subtables: som standard omvandlar Panoply kapslade data till en uppsättning av många-till-många eller en-till-många relationstabeller, som är platta relationstabeller.
- flattning: med det här läget aktiverat plattar Panoply den kapslade strukturen på posten som innehåller den.
Historiktabeller
ibland behöver du analysera data genom att hålla reda på att ändra data över tiden för att se exakt hur data ändras (till exempel människors adresser).
för att utföra sådana analyser använder Panoply Historiktabeller, som är tidsserietabeller som innehåller historiska ögonblicksbilder av varje rad i den ursprungliga statiska tabellen. Du kan sedan utföra enkla frågor om den ursprungliga tabellen eller revideringar av tabellen genom att spola tillbaka till någon tidpunkt.
transformationer
Panoply använder ELT, vilket är en variant på den ursprungliga ETL-dataintegrationsprocessen. När du har injicerat data från källan till ditt datalager omvandlar Panoply det omedelbart. Denna process ger dig realtidsdataanalys och optimal prestanda jämfört med standard ETL-processen.
strängformat
panoply tolkar strängformat och hanterar dem som om de var kapslade objekt i originaldata. Stödda strängformat är CSV, TSV, JSON, JSON-Line, Ruby object format, URL-frågesträngar och webbdistributionsloggar.
dataskydd
Panoply är byggt ovanpå AWS, så det har de senaste säkerhetsuppdateringarna och krypteringsfunktionerna från AWS, inklusive hårdvaruaccelererad RSA-kryptering och Amazon redshifts specifika uppsättning säkerhetsfunktioner.
extra skydd kommer från kolumnkryptering, som låter dig använda dina privata nycklar som inte lagras på Panoplys servrar.
åtkomstkontroll
Panoply använder tvåstegsverifiering för att förhindra obehörig åtkomst, och ett behörighetssystem låter dig begränsa åtkomsten till specifika tabeller, vyer eller kolumner. Anomali upptäckt identifierar frågor som kommer från nya datorer eller ett annat land, så att du kan blockera dessa frågor om de inte får manuellt godkännande.
IP-vitlistning
vi rekommenderar att du blockerar anslutningar från okända källor med hjälp av en brandvägg eller en AWS-säkerhetsgrupp och vitlista de IP-adresser som Panoplys datakällor alltid använder när du öppnar din databas.
slutsats: traditionella vs. Data Warehouse Concepts i korthet
för att avsluta sammanfattar vi de begrepp som introduceras i detta dokument.
traditionella Datalagerkoncept
- fakta och mått: en åtgärd är en egenskap som beräkningar kan göras på. Vi hänvisar till en samling åtgärder som fakta, men ibland används termerna omväxlande.
- normalisering: processen att minska mängden dubbla data, vilket leder till ett mer minneseffektivt datalager som är långsammare att fråga.
- Dimension: används för att kategorisera och kontextualisera fakta och åtgärder, vilket möjliggör analys av och rapportering om dessa åtgärder.
- konceptuell datamodell: definierar de kritiska högnivådataenheterna och relationerna mellan dem.
- logisk datamodell: Beskriver datarelationer, entiteter och attribut på vanlig engelska utan att oroa dig för hur man implementerar det i kod.
- fysisk datamodell: en representation av hur man implementerar datadesignen i ett specifikt databashanteringssystem.
- stjärnschema: tar en faktatabell och delar upp informationen i denormaliserade dimensionstabeller.
- Snowflake schema: delar upp faktatabellen i normaliserade dimensionstabeller. Normalisering minskar problem med dataredundans och förbättrar dataintegriteten, men frågor är mer komplexa.
- OLTP: Online transaktionsbehandlingssystem underlättar snabb, transaktionsorienterad bearbetning med enkla frågor.
- OLAP: online analytisk bearbetning låter dig köra komplexa läsfrågor och därmed utföra en detaljerad analys av historiska transaktionsdata.
- Data mart: ett arkiv med data som fokuserar på ett specifikt ämne eller avdelning inom en organisation.
- Inmon approach: Bill Inmon ‘ s data warehouse approach definierar data warehouse som det centraliserade Datalagret för hela företaget. Data marts kan byggas från data warehouse för att tjäna de analytiska behoven hos olika avdelningar.
- Kimball approach: Ralph Kimball beskriver ett datalager som en sammanslagning av verksamhetskritiska data marts, som först skapas för att tjäna de analytiska behoven hos olika avdelningar.
- ETL: integrerar data i datalagret genom att extrahera det från olika transaktionskällor, omvandla data för att optimera det för analys och slutligen ladda det i datalagret.
- ELT: En variation på ETL som extraherar rådata från en organisations datakällor och laddar den i datalagret. Vid behov omvandlas den för analytiska ändamål.
- Enterprise Data Warehouse: EDW konsoliderar data från alla ämnesområden relaterade till företaget.
Cloud Data Warehouse Concepts-Amazon Redshift som exempel
- Cluster: en grupp delade datorresurser baserade i molnet.
- nod: en datorresurs som finns i ett kluster. Varje nod har sin egen CPU, RAM och hårddiskutrymme.
- kolumnär Lagring: Detta lagrar värdena för en tabell i kolumner snarare än rader, vilket optimerar data för aggregerade frågor.
- komprimering: tekniker för att minska storleken på lagrade data.
- dataladdning: hämta data från källor till det molnbaserade datalagret. I Redshift kan du använda kommandot Kopiera eller en dataströmningstjänst.
Cloud Data Warehouse Concepts-BigQuery som exempel
- serverlös tjänst: molnleverantören hanterar dynamiskt allokeringen av maskinresurser baserat på det belopp användaren förbrukar. Molnleverantören döljer serverhantering och kapacitetsplaneringsbeslut från användarna av tjänsten.
- Colossus file system: ett distribuerat filsystem som använder kolumnär lagring och datakomprimeringsalgoritmer för att optimera data för analys.
- Dremel execution engine: en frågemotor som använder massivt parallell bearbetning och kolumnlagring för att snabbt utföra frågor.
- datadelning: i en serverlös tjänst är det praktiskt att fråga en annan organisations delade data utan att investera i datalagring—du betalar helt enkelt för frågorna.
- strömmande data: infoga data i realtid i datalagret utan att utföra en belastning. Du kan strömma data i batch-förfrågningar, som är flera API-samtal kombinerade till en HTTP-begäran.
traditionell kontra Molnkostnads-nyttoanalys
| kostnad / nytta | traditionell | moln |
| Kostnad | stor kostnad för att köpa och installera ett on-prem-system. du behöver maskinvara, serverrum och specialpersonal (som du betalar löpande). om du är osäker på hur mycket lagringsutrymme du behöver finns det risk för höga sjunkna kostnader som är svåra att återhämta sig. |
inget behov av att köpa hårdvara, serverrum eller anställa specialister. ingen risk för sjunkna kostnader – det är enkelt att köpa mer lagring i framtiden. plus, kostnaden för lagring och datorkraft minskar med tiden. |
| skalbarhet | när du maximerar dina nuvarande serverrum eller hårdvarukapacitet kan du behöva köpa ny hårdvara och bygga/köpa fler platser för att hysa den. Plus, du måste köpa tillräckligt med lagring för att klara topptider; således används det mesta av din lagring inte för det mesta. |
du kan enkelt köpa mer lagring när och när du behöver det. måste ofta bara betala för det du använder, så det finns liten eller ingen risk för överbetalning. |
| integrationer | eftersom cloud computing är normen kommer de flesta integrationer du vill göra att vara molntjänster. att ansluta ditt anpassade datalager till dem kan vara utmanande. |
eftersom molndatalager redan finns i molnet är det enkelt att ansluta till en rad andra molntjänster. |
| säkerhet | du har total kontroll över ditt datalager. jämför mängden data du hyser till Amazon eller Google, du är ett mindre mål för tjuvar. Så du kan vara mer benägna att vara ensam. |
leverantörer av Molndatalager har team fulla av högkvalificerade säkerhetsingenjörer vars enda syfte är att göra deras produkt så säker som möjligt. de mest framstående företagen i världen hanterar dem och implementerar därför säkerhetspraxis i världsklass. |
| styrning | du vet exakt var dina data är och kan komma åt dem lokalt. mindre risk för att mycket känsliga data oavsiktligt bryter mot lagen genom att till exempel resa över hela världen på en molnserver. |
de bästa leverantörerna av molndatalager säkerställer att de följer lagar om styrning och säkerhet, till exempel GDPR. Dessutom hjälper de ditt företag att se till att du är kompatibel. det har varit problem med att veta exakt dina data är och var de rör sig. Dessa problem behandlas och löses aktivt. Observera att lagring av stora mängder mycket känslig data i molnet kan strida mot specifika lagar. Detta är ett exempel där cloud computing kan vara olämpligt för ditt företag. |
| tillförlitlighet | om ditt on-prem datalager misslyckas är det ditt ansvar att fixa det. ditt IT-team har tillgång till den fysiska hårdvaran och kan komma åt alla programlager för att felsöka. Denna snabba åtkomst kan göra att lösa problem mycket snabbare. det finns dock ingen garanti för att ditt lager kommer att ha en viss drifttid varje år. |
leverantörer av Molndatalager garanterar deras tillförlitlighet och drifttid i sina SLA: er. de arbetar på massivt distribuerade system över hela världen, så om det finns ett fel på en, är det högst osannolikt att påverka dig. |
| kontroll | ditt datalager är specialbyggt för att passa dina behov. I teorin gör det vad du vill att det ska göra, när du vill att det ska, på ett sätt du förstår. | du har inte total kontroll över ditt datalager. men majoriteten av tiden är kontrollen du har mer än tillräckligt. |
| hastighet | om du är ett litet företag på en geografisk plats med en liten mängd data kommer din databehandling att bli snabbare. vi pratar dock millisekunder mot sekunder för att vissa processer ska slutföras. ett stort företag som verkar i flera länder är osannolikt att se betydande hastighetsvinster med ett on-prem-system. |
molnleverantörer har investerat i och skapat system som implementerar Massively Parallel Processing (MPP), specialbyggda arkitektur-och exekveringsmotorer och intelligenta databehandlingsalgoritmer. Molndatalager är resultatet av år av forskning och testning för att skapa resurser optimerade för hastighet och prestanda. det kan vara något långsammare än on-prem i vissa fall, men dessa förseningar är ofta försumbara för människor (sekunder vs millisekunder). |
Panoply är en säker plats att lagra, synkronisera och komma åt alla dina affärsdata. Panoply kan ställas in på några minuter, kräver noll pågående underhåll och ger online-support, inklusive tillgång till erfarna dataarkitekter. Prova Panoply gratis i 14 dagar.
Läs mer om datalager
- Data Warehouse Architecture: Traditional vs. Cloud
- databas vs. Data Warehouse
- Data Mart vs. Data Warehouse