Clustering och K betyder: Definition och klusteranalys i Excel
statistik definitioner > Clustering / Cluster Analysis
Vad är Clustering?
Clustering i statistik avser hur data samlas in (“clustered”) av faktorer som:
- ålder.
- hushållens storlek.
- Inkomst.
- eller utbildningsnivå.
sortering av data i kluster leder ibland till mer undersökning av data. Till exempel kan cancerkluster indikera något problem i miljön. Eller de kan bara vara ett resultat av att naturen är slumpmässig. Klusteranalys tenderar att vara subjektiv i många fall; det beror på vad du uppfattar som vanliga trådar i data. Tekniken är inte riktigt något nytt i statistiken; om du någonsin har gjort ett stapeldiagram har du förmodligen redan gjort kluster (även om du inte kallade det så). Till exempel kräver ett stapeldiagram som visar hundraser att du kluster efter ras (Siberian Husky, Border Collie, German Shepherd…) eller ett diagram över inkomstnivåer kan grupperas av låga, mellersta och höga inkomstnivåer.
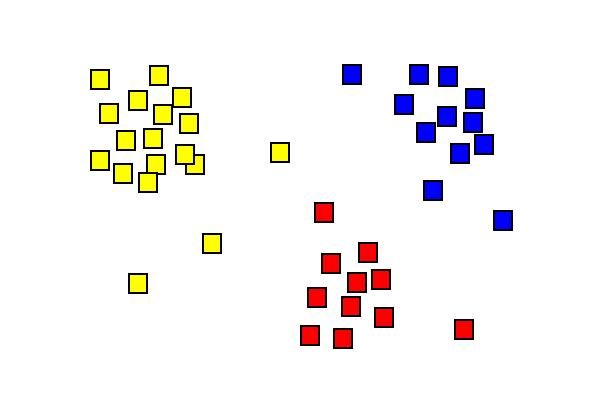
Klusteranalysresultat som visar tre olika färgade kluster.
kluster kan baseras på faktorer som:
- distansbaserad klustring. Objekt sorteras baserat på deras närhet (eller avstånd). Till exempel kan cancerfall samlas ihop om de befinner sig på samma geografiska plats.
- konceptuell kluster. Objekt grupperas efter faktorer som objekt har gemensamt. Till exempel kan cancerkluster grupperas efter “människor som arbetar inom tillverkning.”
Clustering Typer
- Exklusiv Clustering. Varje objekt kan bara tillhöra ett enda kluster. Det kan inte tillhöra ett annat kluster.
- Fuzzy clustering: datapunkter tilldelas en sannolikhet att tillhöra en eller flera kluster.
- Överlappande Kluster. Varje objekt kan tillhöra mer än ett kluster.
- Hierarkisk Gruppering. Detta är ett mer komplext tillvägagångssätt för kluster som används i data mining. I grund och botten ges varje objekt sitt eget kluster. Ett par kluster förenas baserat på likheter, vilket ger ett mindre kluster. Denna process upprepas tills alla objekt är grupperade. Dendrogrammet är ett diagram som visar hierarkiska kluster.
- Probabilistisk Kluster. Data grupperas med hjälp av algoritmer som ansluter objekt med hjälp av avstånd eller densiteter. Detta utförs vanligtvis av en dator.
- Wards metod: använder minsta varians i varje steg för att skapa relativt små kluster med jämn storlek.
K betyder Clustering
Clustering är bara ett sätt att gruppera en uppsättning data i mindre uppsättningar. De två sätten du kan gruppera en uppsättning data är kvantitativt (med siffror) och kvalitativt (med kategorier). Till exempel böcker om Amazon.com listas både efter kategori (kvalitativ) och av bästsäljare (kvantitativ). K-Means clustering är en av de enklaste oövervakade inlärningsalgoritmerna som löser klusterproblem med en kvantitativ metod: du definierar ett antal kluster och använder en enkel algoritm för att sortera dina data. Som sagt,” enkelt ” i datorvärlden motsvarar inte enkelt i verkligheten. Detta är faktiskt ett NP-svårt problem, så du vill använda programvara för K-means clustering. Vissa program som kommer att utföra detta åt dig (klicka på länken för proceduren) är:
- SPSS.
- r
- MATLAB
de allmänna stegen bakom k-means clustering algoritm är:
- Bestäm hur många kluster (k).
- placera k centrala punkter på olika platser (vanligtvis långt ifrån varandra).
- ta varje datapunkt och placera den nära lämplig centralpunkt. Upprepa tills alla datapunkter har tilldelats.
- beräkna om k nya centrala punkter som barycenters.
- upprepa tilldelningen av datapunkter, den här gången till den nya centrala punkten (barycentret).
- upprepa 4 och 5 tills de centrala punkterna (barycenters) inte rör sig längre.
K-Means Clustering: en mer formell Definition
ett mer formellt sätt att definiera K-Means clustering är att kategorisera n-objekt i K(k> 1) fördefinierade grupper. Målet är att minimera avståndet från varje datapunkt till klustret. Med andra ord, för att hitta: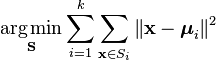
var:
X är en datapunkt
k är antalet kluster
ui är medelvärdet av punkterna i Si.
klusteranalys vs. diskriminantanalys
klusteranalys är mycket lik diskriminantanalys. Båda metoderna innebär separation i grupper. Klusteranalys är dock ett sätt att identifiera grupperna, medan diskrimineringsanalys kräver att du känner till grupperna innan du börjar analysera. Låt oss till exempel säga att du hade en grupp psykiatriska patienter med onormalt beteende. Klusteranalys kan hjälpa dig att hitta olika grupper, som patienter med en historia av missbruk, de med PTSD eller de som upplever hallucinationer. Om du skulle köra diskriminerande analys på samma grupp människor, du måste känna till patienternas diagnoser innan du börjar placera dem i grupper.
kluster i Excel
Microsoft Excel har ett data mining-tillägg för att skapa kluster. Du hittar instruktioner här. Guiden fungerar med Excel-tabeller, intervall eller Analysundersökningsfrågor. Detta tillägg kan anpassas, till skillnad från verktyget identifiera kategorier. Dessutom är verktyget identifiera kategorier begränsat till data från tabeller.
att använda:
- ladda ner och installera tillägget Data Mining.
- klicka på “data Mining” och klicka sedan på “Cluster” och sedan “Next.”
- berätta för Excel var dina data är. Välj Till exempel ett dataområde. Klustersidan kommer att bli tillgänglig.
- Clustering: lämna som är för automatisk gruppering, eller så kan du ange ett antal grupper.
- segment: lämna som är för automatisk gruppering, eller ange ett antal kategorier.
Stephanie Glen. “Clustering och K betyder: Definition & klusteranalys i Excel” från StatisticsHowTo.com: Grundläggande statistik för resten av oss! https://www.statisticshowto.com/clustering/
——————————————————————————
behöver du hjälp med en läxa eller testfråga? Med Chegg Study kan du få steg-för-steg-lösningar på dina frågor från en expert på området. Dina första 30 minuter med en Chegg-handledare är gratis!