det konkava skrovet
skapa en klustergräns med hjälp av en k-närmaste grannstrategi
för några månader sedan skrev jag här på Medium en artikel om kartläggning av Storbritanniens trafikolyckor hotspots. Jag var mest bekymrad över att illustrera användningen av dbscan-klusteralgoritmen på geografiska data. I artikeln använde jag geografisk information publicerad av den brittiska regeringen om rapporterade trafikolyckor. Mitt syfte var att köra en täthetsbaserad klusterprocess för att hitta de områden där trafikolyckor rapporteras oftast. Slutresultatet var skapandet av en uppsättning geo-staket som representerar dessa olyckshändelser.
genom att samla alla punkter i ett visst kluster kan du få en uppfattning om hur klustret skulle se ut på en karta, men du kommer att sakna en viktig information: klustrets yttre form. I det här fallet talar vi om en sluten polygon som kan representeras på en karta som ett geo-staket. Varje punkt inuti geo-staketet kan antas tillhöra klustret, vilket gör denna form till en intressant information: du kan använda den som en diskrimineringsfunktion. Alla nyligen samplade punkter som faller inuti polygonen kan antas tillhöra motsvarande kluster. Som jag antydde i artikeln kan du använda sådana polygoner för att hävda din körrisk genom att använda dem för att klassificera din egen samplade GPS-plats.
frågan är nu hur man skapar en meningsfull polygon ur ett moln av punkter som utgör ett specifikt kluster. Min inställning i den första artikeln var något na ouguive och återspeglade en lösning som jag redan hade använt i produktionskoden. Denna lösning innebar att placera en cirkel centrerad vid var och en av klustrets punkter och sedan slå samman alla cirklar för att bilda en molnformad polygon. Resultatet är inte särskilt trevligt eller realistiskt. Genom att använda cirklar som basform för att bygga den slutliga polygonen kommer dessa också att ha fler poäng än en mer strömlinjeformad form, vilket ökar lagringskostnaderna och gör inkluderingsdetekteringsalgoritmerna långsammare att köra.

å andra sidan har detta tillvägagångssätt fördelen att det är beräkningsmässigt enkelt (åtminstone ur utvecklarens perspektiv), eftersom det använder Shapelys cascaded_union – funktion för att slå samman alla cirklar tillsammans. En annan fördel är att polygonens form implicit definieras med alla punkter i klustret.
för mer sofistikerade tillvägagångssätt måste vi på något sätt identifiera klustrets gränspunkter, de som verkar definiera punktmolnformen. Intressant, med vissa dbscan-implementeringar kan du faktiskt återställa gränspunkterna som en biprodukt av klusterprocessen. Tyvärr är denna information (tydligen) inte tillgänglig på SciKit learns implementering, så vi måste göra det.
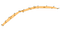
det första tillvägagångssättet som kom att tänka på var att beräkna det konvexa skrovet för uppsättningen punkter. Detta är en väl förstådd algoritm men lider av problemet med att inte hantera konkava former, som den här:

denna form fångar inte korrekt kärnan i de underliggande punkterna. Om det användes som diskriminator skulle vissa punkter felaktigt klassificeras som inne i klustret när de inte är det. Vi behöver ett annat tillvägagångssätt.
det konkava Skrovalternativet
lyckligtvis finns det alternativ till detta tillstånd: vi kan beräkna ett konkavt skrov. Så här ser det konkava skrovet ut när det appliceras på samma uppsättning punkter som i föregående bild:

eller kanske den här:
som du kan se, och i motsats till det konvexa skrovet finns det ingen enda definition av vad det konkava skrovet för en uppsättning punkter är. Med algoritmen som jag presenterar här, valet av hur konkav du vill att dina skrov ska göras genom en enda parameter: k — antalet närmaste grannar som beaktas vid skrovberäkningen. Låt oss se hur det fungerar.
algoritmen
algoritmen jag presenterar här beskrivs för över ett decennium sedan av Adriano Moreira och Maribel Yasmina Santos från University of Minho, Portugal . Från abstrakt:
detta dokument beskriver en algoritm för att beräkna kuvertet för en uppsättning punkter i ett plan, som genererar konvex på icke-konvexa skrov som representerar det område som upptas av de givna punkterna. Den föreslagna algoritmen är baserad på en k-närmaste grannstrategi, där värdet på k, den enda algoritmparametern, används för att styra “jämnheten” i den slutliga lösningen.
eftersom jag kommer att tillämpa denna algoritm på geografisk information, måste vissa ändringar göras, nämligen vid beräkning av vinklar och avstånd . Men dessa förändrar inte på något sätt kärnan i algoritmen, som i stort sett kan beskrivas med följande steg:
- hitta punkten med den lägsta y (latitud) koordinaten och gör den till den nuvarande.
- hitta K-närmaste punkter till den aktuella punkten.
- från K-närmaste punkter, välj den som motsvarar den största högra svängen från föregående vinkel. Här kommer vi att använda begreppet lager och börja med en vinkel på 270 grader (rakt västerut).
- kontrollera om den inte skär sig genom att lägga till den nya punkten i den växande radsträngen. Om det gör det, välj en annan punkt från K-närmaste eller starta om med ett större värde på k.
- gör den nya punkten till den aktuella punkten och ta bort den från listan.
- efter k iterationer Lägg till den första punkten tillbaka till listan.
- slinga till nummer 2.
algoritmen verkar vara ganska enkel, men det finns ett antal detaljer som måste beaktas, särskilt för att vi har att göra med Geografiska koordinater. Avstånd och vinklar mäts på ett annat sätt.
koden
här publicerar jag en anpassad version av föregående artikels kod. Du hittar fortfarande samma klusterkod och samma molnformade klustergenerator. Den uppdaterade versionen innehåller nu ett paket med namnet geomath.hulls där du kan hitta klassen ConcaveHull. För att skapa dina konkava skrov gör du enligt följande:
i koden ovan är points en matris med dimensioner (N, 2), där raderna innehåller de observerade punkterna och kolumnerna innehåller de geografiska koordinaterna (longitud, latitud). Den resulterande matrisen har exakt samma struktur, men innehåller bara de punkter som hör hemma i klustrets polygonala form. Ett filter av olika slag.
eftersom vi kommer att hantera matriser är det bara naturligt att ta NumPy in i striden. Alla beräkningar var vederbörligen vektoriserade, när det var möjligt, och ansträngningar gjordes för att förbättra prestanda när man lägger till och tar bort objekt från arrays (spoiler: de flyttas inte alls). En av de saknade förbättringarna är kodparallellisering. Men det kan vänta.
jag organiserade koden runt algoritmen som exponerad i papperet, även om vissa optimeringar gjordes under översättningen. Algoritmen är uppbyggd kring ett antal subrutiner som tydligt identifieras av papperet, så låt oss få dem ur vägen just nu. För din läskomfort kommer jag att använda samma namn som används i papperet.
CleanList-rengöring listan över punkter utförs i klassen konstruktören:
som du kan se är listan över punkter implementerad som en NumPy-array av prestandaskäl. Rengöringen av listan utförs på rad 10, där endast de unika punkterna hålls. Datamängden är organiserad med observationer i rader och geografiska koordinater i de två kolumnerna. Observera att jag också skapar en boolesk array på rad 13 som kommer att användas för att indexera i huvuddatauppsättningen, lätta på att ta bort objekt och en gång i taget lägga till dem tillbaka. Jag har sett denna teknik som kallas en” mask ” på NumPy dokumentation, och det är mycket kraftfull. När det gäller primtalen kommer jag att diskutera dem senare.
FindMinYPoint-detta kräver en liten funktion:
denna funktion anropas med datauppsättningsmatrisen som argument och returnerar indexet för punkten med lägsta latitud. Observera att rader är kodade med longitud i den första kolumnen och latitud i den andra.
RemovePoint
AddPoint — dessa är no-brainers, på grund av användningen av indices array. Denna array används för att lagra de aktiva indexen i huvuddatamängden, så det är enkelt att ta bort objekt från datamängden.
även om algoritmen som beskrivs i papperet kräver att man lägger till en punkt i matrisen som utgör skrovet, implementeras detta faktiskt som:
senare kommer variabeln test_hull att tilldelas tillbaka till hull när linjesträngen anses vara icke-skärande. Men jag går före spelet här. Att ta bort en punkt från datauppsättningsmatrisen är så enkelt som:
self.indices = False
att lägga tillbaka det handlar bara om att vända det arrayvärdet vid samma index tillbaka till Sant. Men all denna bekvämlighet kommer med priset för att behöva hålla våra flikar på indexen. Mer om detta senare.
NearestPoints-saker börjar bli intressanta här eftersom vi inte har att göra med plana koordinater, så ut med Pythagoras och in med Haversine:
Observera att de andra och tredje parametrarna är matriser i datasetformatet: longitud i den första kolumnen och latitud i den andra. Som du kan se returnerar den här funktionen en rad avstånd i meter mellan punkten i det andra argumentet och punkterna i det tredje argumentet. När vi har dessa, vi kan få k-närmaste grannar på det enkla sättet. Men det finns en specialiserad funktion för det och det förtjänar några förklaringar:
funktionen börjar med att skapa en array med basindexen. Det här är indexen för de punkter som inte har tagits bort från datamängden. Till exempel, om vi på ett tiopunktskluster började med att ta bort den första punkten, skulle basindexmatrisen vara . Därefter beräknar vi avstånden och sorterar de resulterande arrayindexen. Den första k extraheras och används sedan som en mask för att hämta basindexen. Det är typ av förvrängd men fungerar. Som du kan se returnerar funktionen inte en matris med koordinater, utan en uppsättning index i datamängden.
SortByAngle-det finns mer problem här eftersom vi inte beräknar enkla vinklar, vi beräknar lager. Dessa mäts som noll grader rakt norrut, med vinklar som ökar medurs. Här är kärnan i koden som beräknar lagren:
funktionen returnerar en rad lager mätt från den punkt vars index är i det första argumentet, till de punkter vars index är i det tredje argumentet. Sortering är enkel:
vid denna punkt, kandidaterna array innehåller index för k-närmaste punkter sorterade efter fallande ordning lager.
IntersectQ — istället för att rulla mina egna linjekorsningsfunktioner vände jag mig till Shapely för hjälp. Faktum är att vi, när vi bygger polygonen, i huvudsak hanterar en linjesträng och lägger till segment som inte skär varandra med de tidigare. Testning för detta är enkelt: vi plockar upp skrovmatrisen under konstruktion, konverterar den till ett välformat linjesträngobjekt och testar om det är enkelt (icke självkorsande) eller inte.
i ett nötskal blir en välformad linjesträng komplex om den själv korsar, så is_simple-predikatet blir falskt. Lätt.
PointInPolygon-detta visade sig vara den svåraste att genomföra. Låt mig förklara genom att titta på koden som utför den slutliga skrovpolygonvalideringen (kontrollerar om alla punkter i klustret ingår i polygonen):
Shapelys funktioner för att testa för korsning och inkludering borde ha varit tillräckligt för att kontrollera om den slutliga skrovpolygonen överlappar alla klustrets punkter, men de var inte. Varför? Shapely är koordinat-agnostiker, så det kommer att hantera geografiska koordinater uttryckta i breddgrader och longituder exakt på samma sätt som koordinater på ett kartesiskt plan. Men världen beter sig annorlunda när du bor på en sfär, och vinklar (eller lager) är inte konstanta längs en geodetisk. Exemplet på referens av en geodetisk linje som förbinder Bagdad till Osaka illustrerar perfekt detta. Det händer så att algoritmen under vissa omständigheter kan innehålla en punkt baserad på lagerkriteriet men senare, med Shapelys plana algoritmer, anses någonsin så lite utanför polygonen. Det är vad den lilla avståndskorrigeringen gör där.
det tog mig ett tag att räkna ut detta. Min felsökningshjälp var QGIS, en stor del av fri programvara. Vid varje steg i de misstänkta beräkningarna skulle jag mata ut data i WKT-format till en CSV-fil som ska läsas in som ett lager. En riktig livräddare!
slutligen, om polygonen inte täcker alla klustrets punkter, är det enda alternativet att öka k och försöka igen. Här har jag lagt till lite av min egen intuition.
Prime k
artikeln föreslår att värdet på k ökas med en och att algoritmen körs igen från början. Mina tidiga tester med det här alternativet var inte särskilt tillfredsställande: körtiderna skulle vara långsamma på problematiska kluster. Detta berodde på den långsamma ökningen av k, så jag bestämde mig för att använda ett annat ökningsschema: en tabell med primtal. Algoritmen börjar redan med k = 3, så det var en enkel förlängning för att få den att utvecklas på en lista med primtal. Det här är vad du ser hända i det rekursiva samtalet:
jag har en sak för primtal, du vet…
spränga
de konkava skrovpolygonerna som genereras av denna algoritm behöver fortfarande ytterligare bearbetning, eftersom de bara kommer att diskriminera punkter inuti skrovet, men inte nära det. Lösningen är att lägga till lite vaddering i dessa magra kluster. Här använder jag exakt samma teknik som tidigare, och här är hur det ser ut:

här använde jag Shapely S bufferfunktion för att göra susen.
funktionen accepterar en välformad Polygon och returnerar en uppblåst version av sig själv. Den andra parametern är radien i meter av den tillsatta stoppningen.
kör koden
börja med att dra koden från GitHub-förvaret till din lokala maskin. Filen du vill köra är ShowHotSpots.py i huvudkatalogen. Vid första körningen kommer koden att läsa i de brittiska trafikolycksdata från 2013 till 2016 och klustera den. Resultaten cachas sedan som en CSV-fil för efterföljande körningar.
du kommer då att presenteras med två kartor: den första genereras med hjälp av molnformade kluster medan den andra använder den konkava klusteralgoritmen som diskuteras här. Medan polygongenereringskoden körs kan du se att några fel rapporteras. För att förstå varför algoritmen misslyckas med att skapa ett konkavt skrov skriver koden klusterna till CSV-filer till katalogen data/out/failed/. Som vanligt kan du använda QGIS för att importera dessa filer som lager.
i huvudsak misslyckas denna algoritm när den inte hittar tillräckligt med poäng för att “gå runt” formen utan att självkorsa. Det betyder att du måste vara redo att antingen kasta bort dessa kluster eller att tillämpa en annan behandling på dem (konvex skrov eller sammanslagna bubblor).
konkavitet
det är en wrap. I den här artikeln presenterade jag en metod för efterbehandling dbscan genererade geografiska kluster i konkava former. Denna metod kan ge en bättre passande yttre polygon för klusterna jämfört med andra alternativ.
Tack för att du läste och njut av att tinka med koden!
Kryszkiewicz M., Lasek P. (2010) TI-DBSCAN: kluster med DBSCAN med hjälp av triangeln ojämlikhet. I: Szczuka M., Kryszkiewicz M., Ramanna S., Jensen R., Hu Q. (Red) grova uppsättningar och aktuella trender inom databehandling. RSCTC 2010. Föreläsningsanteckningar i datavetenskap, vol 6086. Springer, Berlin, Heidelberg
Scikit-lär dig: maskininlärning i Python, Pedregosa et al., JMLR 12, pp. 2825-2830, 2011
Moreira, A. och Santos, M. Y., 2007, konkav skrov: en K-närmaste grannmetod för beräkning av regionen upptagen av en uppsättning punkter
beräkna avstånd, lager och mer mellan latitud / Longitudpunkter
GitHub repository