gemensam sökning: open source-projektet som tar tillbaka PageRank
registrera dig för våra dagliga återblickar av det ständigt föränderliga sökmarknadsföringslandskapet.
Obs: Genom att skicka in detta formulär godkänner du Third Door Medias villkor. Vi respekterar din integritet.

under de senaste åren har Google långsamt minskat mängden data som är tillgänglig för SEO-utövare. Först var det sökordsdata, sedan PageRank-poäng. Nu är det specifik sökvolym från AdWords (om du inte spenderar lite moola). Du kan läsa mer om detta i Russ Jones utmärkta artikel som beskriver effekterna av hans företags forskning och insikter i klickströmsdata för volymdisambiguering.
ett objekt som vi har blivit riktigt involverade i nyligen är vanliga Genomsökningsdata. Det finns flera lag i vår bransch som har använt dessa data under en tid, så jag kände mig lite sen till spelet. Common Crawl data är ett open source-projekt som skrapar hela internet med jämna mellanrum. Tack och lov, Amazon, är det stora företaget det är, slog in för att lagra data för att göra den tillgänglig för många utan de höga lagringskostnaderna.
förutom vanliga Genomsökningsdata finns det en ideell kallad Common Search vars uppdrag är att skapa en alternativ öppen källkod och transparent sökmotor-motsatsen, i många avseenden, av Google. Detta väckte mitt intresse eftersom det betyder att vi alla kan spela, tweak och Mangla signalerna för att lära oss hur sökmotorer fungerar utan den enorma tidsinvesteringen att börja från ground zero.
vanliga sökdata
för närvarande använder Common Search följande datakällor för att beräkna deras sökrankning (detta tas direkt från deras webbplats):
- vanlig genomsökning: det största öppna arkivet med webbgenomsökningsdata. Detta är för närvarande vår unika källa till rå siddata.
- Wikidata: En gratis, länkad databas som fungerar som central lagring för strukturerad data för många Wikimediaprojekt som Wikipedia, Wikivoyage och Wikisource.
- UT1 svartlista: underhålls av Fabrice Prigent från Universit Ukrainian Toulouse 1 Capitole, denna svartlista kategoriserar domäner och webbadresser i flera kategorier, inklusive “vuxen” och “phishing.”
- DMOZ: även känd som Open Directory-projektet, Det är den äldsta och största webbkatalogen som fortfarande lever. Även om dess data inte är lika tillförlitliga som tidigare, använder vi den fortfarande som en signal-och metadatakälla.
- webbdata Commons Hyperlänkdiagram: grafer över alla hyperlänkar från ett vanligt Genomsökningsarkiv från 2012. Vi använder för närvarande sin harmoniska Centralitetsfil som en tillfällig rankningssignal på domäner. Vi planerar att utföra vår egen analys av webbgrafen inom en snar framtid.
- Alexa top 1m-webbplatser: Alexa rankar webbplatser baserat på ett kombinerat mått på sidvisningar och unika webbplatsanvändare. Det är känt att det är demografiskt partiskt. Vi använder det som en tillfällig rankningssignal på domäner.
vanlig sökrankning
förutom dessa datakällor använder den också URL-längd, banlängd och domän PageRank som rankningssignaler i sin algoritm för att undersöka koden. Se och se, sedan juli har Common Search haft sina egna data på värdnivå PageRank, och vi missade alla det.
Jag kommer till PageRank (PR) på ett ögonblick, men det är intressant att granska koden för vanlig genomsökning, särskilt ranker.py del ligger här, eftersom du verkligen kan komma in i förarsätet med tweaking vikterna av de signaler som den använder för att rangordna sidorna:
signal_weights = {"url_total_length": 0.01,"url_path_length": 0.01,"url_subdomain": 0.1,"alexa_top1m": 5,"wikidata_url": 3,"dmoz_domain": 1,"dmoz_url": 1,"webdatacommons_hc": 1,"commonsearch_host_pagerank": 1}
av särskild anmärkning är också att Common Search använder BM25 som likhetsmått för nyckelord för att dokumentera kropp och metadata. BM25 är ett bättre mått än TF-IDF eftersom det tar hänsyn till dokumentlängd, vilket innebär att ett 200-ordsdokument som har ditt sökord fem gånger är förmodligen mer relevant än ett 1500-ordsdokument som har det samma antal gånger.
det är också värt att säga att antalet signaler här är mycket rudimentärt och uppenbarligen saknar många av de förbättringar (och data) som Google har integrerat i sin sökrankningsalgoritm. En av de viktigaste sakerna som vi arbetar med är att använda tillgängliga data i Common Crawl och infrastrukturen för Common Search för att göra ämnesvektorsökning efter innehåll som är relevant baserat på semantik, inte bara sökordsmatchning.
vidare till PageRank
på sidan Här hittar du länkar till Värdnivå PageRank för den gemensamma genomsökningen i juni 2016. Jag använder den som heter pagerank-top1m.txt.GZ (topp 1 miljoner) eftersom den andra filen är 3 GB och över 112 miljoner domäner. Även i R har jag inte tillräckligt med maskin för att ladda den utan att täcka ut.
efter nedladdning måste du ta med filen till din arbetskatalog i R. PageRank-data från vanlig sökning normaliseras inte och är inte heller i det rena 0-10-formatet som vi alla är vana vid att se den i. Vanlig sökning använder ” max (0, min(1, float(rank) / 244660.58)) ” — i grund och botten en domäns rang dividerad med Facebook: s rang-som metoden för att översätta data till en fördelning mellan 0 och 1. Men detta lämnar några bestämda luckor, eftersom detta skulle lämna LinkedIns PageRank som en 1.4 när den skalas av 10.

följande kod laddar datasetet och lägger till en PR-kolumn med en bättre approximerad PR:
#Grab the datadf <- read.csv("pagerank-top1m.txt", header = F, sep = " ")#Log NormalizelogNorm <- function(x){ #Normalize x <- (x-min(x))/(max(x)-min(x)) 10 / (1 - (log10(x)*.25))}#Append a Column named PR to the datasetdf$pr <- (round(logNorm(df$V2),digits = 0))
vi var tvungna att leka lite med siffrorna för att få det någonstans nära (för flera prover av domäner som jag kom ihåg PR för) till den gamla Google PR. Nedan följer några exempel PageRank resultat:
- en.wikipedia.org (8)
- searchengineland.com (6)
- consultwebs.com (5)
- youtube.com (9)
- moz.com (6)
här är en plot av 100 000 slumpmässiga prover. Den beräknade PageRank-poängen är längs Y-axeln, och den ursprungliga gemensamma Sökpoängen är längs X-axeln.
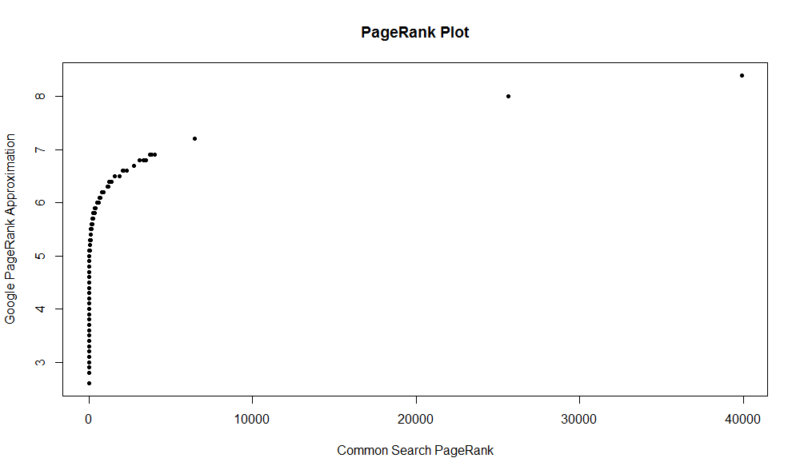
för att ta tag i dina egna resultat kan du köra följande kommando i R (ersätt bara din egen domän):
df

Tänk på att denna dataset bara har de bästa en miljon domänerna av PageRank, så av 112 miljoner domäner som Common Search indexeras finns det en god chans att din webbplats kanske inte är där om den inte har en ganska bra länkprofil. Dessutom innehåller detta mått ingen indikation på skadligheten av länkar, bara en approximation av webbplatsens popularitet med avseende på länkar.
gemensam sökning är ett bra verktyg och en bra grund. Jag ser fram emot att bli mer involverad i samhället där och förhoppningsvis lära mig att förstå muttrarna och bultarna bakom sökmotorer bättre genom att faktiskt arbeta med en. Med R och lite kod kan du snabbt kontrollera PR för en miljon domäner på några sekunder. Hoppas du gillade!
registrera dig för våra dagliga återblickar av det ständigt föränderliga sökmarknadsföringslandskapet.
Obs: Genom att skicka in detta formulär godkänner du Third Door Medias villkor. Vi respekterar din integritet.
om författaren

JR Oakes är senior chef för teknisk SEO-forskning på Locomotive. Han var tidigare chef för teknisk SEO på Adapt Partners agency. Han arbetar med kunder på ett brett spektrum av fronter, inklusive tekniska problem, prestanda, CTR, crawl-förmåga, innehåll och dataanalys. JR älskar att testa, koda och prototypa lösningar på svåra sökmarknadsföringsproblem. När han inte arbetar tycker han om att läsa om ny teknik, spela basgitarr, titta på college basket, laga mat och spendera tid med sina vänner och familj. Han är också en av medarrangörerna för Raleigh SEO Meetup, Raleigh SEO Conference och RTP SEO Meetup.