utveckling av klusterschemaläggningssystem
Kubernetes har blivit de facto-standarden inom containerorkestrering. Alla applikationer kommer att utvecklas och köras på Kubernetes i framtiden. Syftet med denna artikelserie är att introducera Kubernetes underliggande implementeringsprinciper på ett djupgående och enkelt sätt.
Kubernetes är ett klusterschemaläggningssystem. Denna artikel introducerar främst några tidigare kluster schemaläggning systemarkitektur Kubernetes. Genom att analysera deras designideer och arkitekturens egenskaper kan vi studera utvecklingsprocessen för klusterplaneringssystemarkitektur och det största problemet som måste beaktas i arkitekturdesignen. Det kommer att vara till stor hjälp för att förstå Kubernetes arkitektur.
vi måste förstå några av de grundläggande begreppen i cluster scheduling system, för att göra det klart kommer jag att förklara konceptet genom ett exempel, låt oss anta att vi vill implementera en distribuerad Cron. Systemet hanterar en uppsättning Linux-värdar. Användaren definierar jobbet genom API som tillhandahålls av systemet. systemet kommer regelbundet att utföra motsvarande uppgift baserat på uppgiftsdefinitionen, i det här exemplet är de grundläggande begreppen nedan:
- kluster: Linux-värdarna som hanteras av detta system utgör en resurspool för att köra uppgifter. Denna resurspool kallas kluster.
- jobb: det definierar hur klustret utför sina uppgifter. I det här exemplet är Crontab exakt ett enkelt jobb som tydligt visar vad som behöver göras (exekveringsskript) vid vilken tidpunkt(tidsintervall).Definitionen av vissa jobb är mer komplex, till exempel definitionen av ett jobb som ska slutföras i flera uppgifter, och beroenden mellan uppgifter, liksom resurskraven för varje uppgift.
- uppgift: ett jobb måste schemaläggas till specifika prestandauppgifter. Om vi definierar ett jobb för att utföra ett skript klockan 1 varje natt, är skriptprocessen som utförs klockan 1 varje dag en uppgift.
vid utformning av klusterschemaläggningssystemet är systemets kärnuppgifter två:
- schemaläggning av uppgifter: När jobben har skickats till klusterschemaläggningssystemet måste de inlämnade jobben delas in i specifika exekveringsuppgifter och exekveringsresultaten för uppgifterna måste spåras och övervakas. I exemplet med den distribuerade Cron måste schemaläggningssystemet i rätt tid starta processen i enlighet med kraven i operationen. Om processen misslyckas med att utföra är försöket nödvändigt etc. Vissa komplexa scenarier, såsom Hadoop Map Reduce, schemaläggningssystemet måste dela kartan minska uppgiften i motsvarande flera kartan och minska uppgifter, och i slutändan få uppgiften utförande resultatdata.
- Resursschemaläggning: används huvudsakligen för att matcha aktiviteter och resurser, och lämpliga resurser allokeras för att köra aktiviteter enligt resursanvändning av värdar i klustret. Det liknar processen för schemaläggning algoritm av operativsystemet, är det huvudsakliga målet med resurs schemaläggning att förbättra resursutnyttjandet så långt som möjligt och minska väntetiden för uppgifter under förutsättning av den fasta tillgången på resurser, och minska fördröjningen av uppgiften eller svarstid (om det är batch uppgift, hänvisar den till tiden från början till slut av uppgiften operationer, om det är online svarstyp uppgifter, såsom webbapplikationer, som hänvisar till varje svarstid på begäran), har uppgiften prioritet tas i beaktande samtidigt som möjligt (resurser är ganska allokerade till alla uppgifter). Några av dessa mål är motstridiga och måste balanseras, såsom resursutnyttjande, svarstid, rättvisa och prioriteringar.
Hadoop MRv1
Map Reduce är en typ av parallell datormodell. Hadoop kan köra denna typ av klusterhanteringsplattform för parallell databehandling. MRv1 är den första generationens version av Map minska uppgiften schemaläggning motor Hadoop plattform. Kort sagt, MRv1 är ansvarig för schemaläggning och utförande jobbet på klustret, och återgå till beräkningsresultaten när en användare definierar en karta minska beräkning och skicka den till Hadoop. Så här ser arkitekturen för MRv1 ut:
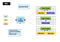
arkitekturen är relativt enkel, standard Master / Slave-arkitekturen har två kärnkomponenter:
- Job Tracker är huvudhanteringskomponenten i cluster, som ansvarar för både resursschemaläggning och aktivitetsschemaläggning.
- Task Tracker körs på varje maskin i klustret, som ansvarar för att köra specifika uppgifter på värd-och rapporteringsstatus.
med populariteten hos Hadoop och ökningen av olika krav har MRv1 följande problem att förbättras:
- prestandan har en viss flaskhals: det maximala antalet noder som stöder hanteringen är 5 000 och det maximala antalet uppgifter för att stödja operationen är 40 000. Det finns fortfarande utrymme för förbättringar.
- det är inte tillräckligt flexibelt för att utöka eller stödja andra aktivitetstyper. Förutom Map reduce-type-uppgifter finns det många andra uppgiftstyper i Hadoop-ekosystemet som måste schemaläggas, till exempel Spark, Hive, HBase, Storm, Oozie, etc. Därför behövs ett mer allmänt schemaläggningssystem som kan stödja och utöka fler uppgiftstyper
- lågt resursutnyttjande: MRv1 konfigurerar statiskt ett fast antal slitsar för varje nod, och varje slits kan endast användas för den specifika uppgiftstypen (karta eller minska), vilket leder till problemet med resursutnyttjande. Till exempel står ett stort antal kartuppgifter i kö för lediga resurser, men i själva verket är ett stort antal Reduktionsplatser lediga för maskiner.
- flerhyres-och flerversionsproblem. Till exempel kör olika avdelningar uppgifter i samma kluster, men de är logiskt isolerade från varandra, eller de kör olika versioner av Hadoop i samma kluster.
garn
garn(ännu en Resursförhandlare) är en andra generation av Hadoop ,huvudsyftet är att lösa alla typer av problem i MRv1. GARNARKITEKTUREN ser ut så här:

den enkla förståelsen av garn är att den huvudsakliga förbättringen jämfört med MRv1 är att dela ansvaret för det ursprungliga JobTrack i två olika komponenter: Resource Manager och Application Master
- Resource Manager: Det ansvarar för Resursschemaläggning, hanterar alla resurser, tilldelar resurser till olika typer av uppgifter och utökar enkelt Resursschemaläggningsalgoritmen genom en pluggbar arkitektur.
- Application Master: det är ansvarigt för schemaläggning av uppgifter. Varje jobb (kallas Application in YARN) startar en motsvarande application Master, som ansvarar för att dela upp jobbet i specifika uppgifter och ansöka om resurser från Resource Manager, starta aktiviteten, spåra status för aktiviteten och rapportera resultaten.
Låt oss ta en titt på hur denna arkitekturförändring löste MRv1: s olika problem:
- dela upp den ursprungliga uppgiften schemaläggning ansvar Job Tracker, och resulterar i betydande prestandaförbättringar. Uppgiftsplaneringsansvaret för den ursprungliga Jobbspåraren delades ut för att utföras av Application Master,och Application Master distribuerades, varje instans hanterade bara begäran om ett jobb, så det främjade det maximala antalet klusternoder från 5 000 till 10 000.
- komponenterna i task scheduling, Application Master och resource scheduling frikopplas och skapas dynamiskt baserat på jobbförfrågningar. En Application Master instans är ansvarig för endast ett jobb med schemaläggning, vilket gör det lättare att stödja olika typer av jobb.
- containerisoleringstekniken introduceras, varje uppgift körs i en isolerad behållare, vilket avsevärt förbättrar resursutnyttjandet enligt uppgiftens efterfrågan på resurser som kan tilldelas dynamiskt. Nackdelen med detta är Garns resurshantering och allokering har bara en dimension av minnet.
Mesos architecture
designmålet för garn är fortfarande att tjäna schemaläggningen av Hadoop-ekosystemet. Mesos mål närmar sig, det är utformat för att vara ett allmänt schemaläggningssystem som kan hantera driften av hela datacentret. Som vi ser använde mesos arkitektoniska design mycket garn som referens, jobbet schemaläggning och resursplanering bärs av de olika modulerna separat. Men den största skillnaden mellan Mesos och garn är sättet att schemalägga resurser, en unik mekanism som kallas Resurserbjudande är utformad. Trycket i resursschemaläggningen släpps ytterligare, och jobbschemaläggningens skalbarhet ökar också.

de viktigaste komponenterna i Mesos är:
- Mesos Master: det är en komponent som är ensam ansvarig för resursallokering och ledningskomponenter, vilket är Resurshanteraren som motsvarar det inre garnet. Men driftsättet är något annorlunda om det kommer att diskuteras senare.
- Framework: ansvarar för jobbplanering, olika jobbtyper kommer att ha ett motsvarande ramverk, till exempel Spark Framework som ansvarar för Spark jobs.
Resurserbjudande av Mesos
det kan verka som att Mesos – och GARNARKITEKTURERNA är ganska lika, men i själva verket har mesos-mästaren en mycket unik (och något bisarr) Resurserbjudandemekanism:
- garn är Pull: Resurserna som tillhandahålls av Resource Manager i garn är passiva, när konsumenterna av resource (Application Master) behöver resurser kan det ringa gränssnittet för Resource Manager för att få resurser, och Resource Manager svarar bara passivt på behoven hos Application Master.
- Mesos är Push: resurserna som tillhandahålls av Master of Mesos är proaktiva. Master of Mesos kommer regelbundet att ta initiativ till att driva alla nuvarande tillgängliga resurser (de så kallade Resurserbjudandena, jag kommer att kalla det erbjudande från och med nu) till ramverket. Om det finns uppgifter för ramverket att utföra kan det inte aktivt ansöka om resurser, såvida inte erbjudandena tas emot. Framework väljer en kvalificerad resurs från erbjudandet att acceptera (denna rörelse kallas Acceptera I Mesos) och avvisa de återstående erbjudandena (denna rörelse kallas avvisa). Om det inte finns tillräckligt med kvalificerade resurser i denna erbjudande, måste vi vänta på nästa omgång av Master för att ge erbjudande.
jag tror att när du ser denna aktiva erbjudande mekanism, du kommer att ha samma känsla med mig. Det vill säga effektiviteten är relativt låg och följande problem kommer att uppstå:
- beslutets effektivitet i alla ramar påverkar den totala effektiviteten. För konsekvens kan Master bara erbjuda ett ramverk i taget och vänta på att ramverket väljer erbjudandet innan resten ges till nästa ramverk. På detta sätt kommer beslutseffektiviteten i alla ramar att påverka den totala effektiviteten.
- “slösa” mycket tid på ramar som inte kräver resurser. Mesos vet inte riktigt vilket ramverk som behöver resurser. Så det kommer att finnas ramverk med resurskrav står i kö för erbjudande, men ramverket utan resurskrav får ofta erbjudande.
som svar på ovanstående problem har Mesos tillhandahållit några mekanismer för att mildra problemen, till exempel att ställa in en timeout för ramverket att fatta beslut eller låta ramverket avvisa erbjudanden genom att ställa in det för att undertrycka tillstånd. Eftersom det inte är fokus för denna diskussion försummas detaljerna här.
faktum är att det finns några uppenbara fördelar för Mesos som använder denna mekanism för aktivt erbjudande:
- prestandan är uppenbarligen förbättrad. Ett kluster kan stödja upp till 100 000 noder enligt simuleringstestningen, för Twitters produktionsmiljö, kan det största klustret stödja 80 000 noder. Huvudskälet är att det aktiva erbjudandet om Mesos Master mechanism förenklar Mesos ansvar ytterligare. processen för resursschemaläggning, matchning av resurs till uppgift, i Mesos är uppdelad i två steg: resurser att erbjuda och erbjuda uppgift. Mesos-mästaren är bara ansvarig för att slutföra den första fasen, och matchningen av den andra fasen lämnas till ramverket.
- mer flexibel och kunna möta mer ansvarsfulla policyer för schemaläggning av uppgifter. Till exempel resursanvändningsstrategin för alla eller ingenting.
Schemaläggningsalgoritm för Mesos DRF (Dominant Resource Fairness)
när det gäller DRF-algoritmen har det faktiskt inget att göra med vår förståelse av Mesos-arkitektur, men det är mycket kärna och viktigt i Mesos, så jag kommer att förklara lite mer här.
som nämnts ovan ger Mesos erbjudande till ramverket i sin tur, så vilken ram bör väljas för att ge erbjudande varje gång? Detta är kärnproblemet som ska lösas av DRF-algoritmen. Grundprincipen är att ta hänsyn till både rättvisa och effektivitet. Samtidigt som man uppfyller alla resurskrav i ramverket, bör det vara så rättvist som möjligt att undvika att en ram förbrukar för många resurser och svälter andra ramar till döds.
DRF är en variant av min-max rättvisa algoritm. Enkelt uttryckt är det att välja ramverket med den lägsta dominerande resursanvändningen för att ge erbjudandet varje gång. Hur man beräknar den dominerande resursanvändningen av ramverket? Från alla resurstyper som används i ramverket väljs resurstypen med den lägsta resursbefattningsgraden som den dominerande resursen. Dess Resursbearbetningsgrad är exakt den dominerande resursanvändningen av ramverket. Till exempel upptar en CPU av RAM 20% av den totala resursen, 30% av minnet och 10% av skivan. Så den dominerande resursanvändningen av ramverket kommer att vara 10%, den officiella termen kallar en disk som dominerande resurs, och denna 10% kallas dominerande resursanvändning.
det ultimata målet för DRF är att fördela resurser lika mellan alla ramar. Om en Framework X accepterar för många resurser i denna erbjudande, tar det mycket längre tid att få möjlighet till nästa erbjudande. Men noggranna läsare kommer att upptäcka att det finns ett antagande i denna algoritm, det vill säga efter att ramverket accepterar resurser, kommer det att släppa dem snabbt, annars kommer det att finnas två konsekvenser:
- andra ramar svälter ihjäl. One Framework a accepterar de flesta resurserna i klustret på en gång, och uppgiften fortsätter att springa utan att sluta, så att de flesta resurserna är upptagna av Framework A hela tiden, och andra ramar kommer inte längre att få resurserna.
- svälta dig själv till döds. Eftersom den dominerande resursanvändningen av denna ram alltid är mycket hög, så finns det ingen chans att få erbjudande under lång tid, så fler uppgifter kan inte köras.
så Mesos är endast lämplig för schemaläggning korta uppgifter, och Mesos var ursprungligen avsedd för korta uppgifter datacenter.
sammanfattning
från den stora arkitekturen är all schemaläggningssystemarkitektur Master/Slave-arkitektur, Slave end installeras på varje maskin med krav på hantering, som används för att samla in värdinformation och utföra uppgifter på värden. Master är huvudsakligen ansvarig för resursplanering och schemaläggning. Resursschemaläggning har högre krav på prestanda och schemaläggning har högre krav på skalbarhet. Den allmänna trenden är att diskutera de två typerna av tullavkoppling och komplettera dem med olika komponenter.
